Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Canalización de un modelo
Una de las características principales de la biblioteca de paralelismo SageMaker de modelos es el paralelismo de canalización, que determina el orden en que se realizan los cálculos y se procesan los datos en todos los dispositivos durante el entrenamiento del modelo. La canalización es una técnica que permite lograr una verdadera paralelización en el paralelismo del modelo, ya que permite GPUs procesar simultáneamente diferentes muestras de datos y superar la pérdida de rendimiento provocada por el cálculo secuencial. Al utilizar el paralelismo de canalización, el trabajo de entrenamiento se ejecuta de forma escalonada en microlotes para maximizar el uso de la GPU.
nota
El paralelismo por canalización, también denominado particionamiento de modelos, está disponible tanto para como para. PyTorch TensorFlow Para las versiones compatibles de los marcos, consulte Marcos admitidos y Regiones de AWS.
Programa de ejecución de canalización
La canalización se basa en dividir un minilote en microlotes, que se introducen en el proceso de formación one-by-one y siguen un programa de ejecución definido por el tiempo de ejecución de la biblioteca. Un microlote es un subconjunto más pequeño de un minilote de entrenamiento determinado. El programa de canalización determina qué microlote ejecuta cada dispositivo en cada intervalo de tiempo.
Por ejemplo, según el cronograma de procesamiento y la partición del modelo, la GPU i puede realizar el cálculo (hacia adelante o hacia atrás) en microlotes, b mientras que la GPU i+1 realiza el cálculo en microlotesb+1, manteniendo así ambos activos al mismo tiempo. GPUs Durante una sola pasada hacia adelante o hacia atrás, el flujo de ejecución de un único microlote puede visitar el mismo dispositivo varias veces, en función de la decisión de división. Por ejemplo, una operación que se realiza al principio del modelo se puede colocar en el mismo dispositivo que una operación al final del modelo, mientras que las operaciones intermedias se realizan en diferentes dispositivos, lo que significa que este dispositivo se visita dos veces.
La biblioteca ofrece dos programas de canalización diferentes, simples e intercalados, que se pueden configurar mediante el pipeline parámetro del SDK de SageMaker Python. En la mayoría de los casos, la canalización intercalada puede lograr un mejor rendimiento al utilizarla de manera más eficiente. GPUs
Canalización intercalada
En una canalización intercalada, se prioriza la ejecución inversa de los microlotes siempre que sea posible. Esto permite liberar más rápidamente la memoria utilizada para las activaciones, lo que permite utilizar la memoria de manera más eficiente. También permite aumentar el número de microlotes, lo que reduce el tiempo de inactividad del. GPUs En estado estable, cada dispositivo alterna entre pasadas hacia adelante y hacia atrás. Esto significa que la pasada hacia atrás de un microlote puede transcurrir antes de que finalice la pasada hacia adelante de otro microlote.

La figura anterior ilustra un ejemplo de programa de ejecución para la canalización intercalada a lo largo de 2. GPUs En dicha figura, F0 representa la pasada hacia adelante para el microlote 0 y B1 representa la pasada hacia atrás para el microlote 1. La actualización representa la actualización de los parámetros por parte del optimizador. La GPU0 siempre prioriza las pasadas hacia atrás siempre que sea posible (por ejemplo, ejecuta B0 antes que F2), lo que permite borrar la memoria utilizada para las activaciones anteriores.
Canalización sencilla
Por el contrario, una canalización simple termina de ejecutar la pasada hacia adelante para cada microlote antes de iniciar la pasada hacia atrás. Esto significa que solo canaliza la pasada hacia adelante y la pasada hacia atrás dentro de sí misma. En la siguiente figura, se muestra un ejemplo de cómo funciona, durante 2. GPUs

Canalización de la ejecución en marcos específicos
Utilice las siguientes secciones para obtener información sobre las decisiones de programación de canalizaciones específicas del marco que utiliza SageMaker la biblioteca de paralelismo modelo para y. TensorFlow PyTorch
Pipeline Execution con TensorFlow
La siguiente imagen es un ejemplo de un TensorFlow gráfico dividido por la biblioteca de paralelismo de modelos, mediante la división automática de modelos. Al dividir un gráfico, cada subgráfico resultante se replica B veces (excepto las variables), donde B es el número de microlotes. En esta figura, cada subgráfico se repite 2 veces (B=2). Se inserta una operación SMPInput en cada entrada de un subgráfico y se inserta una operación SMPOutput en cada salida. Estas operaciones se comunican con el servidor de la biblioteca para transferir los tensores entre sí.

La siguiente imagen es un ejemplo de 2 subgráficos divididos por B=2 con operaciones de gradiente añadidas. El gradiente de una operación SMPInput es una operación SMPOutput y viceversa. Esto permite que los gradientes fluyan hacia atrás durante la retropropagación.
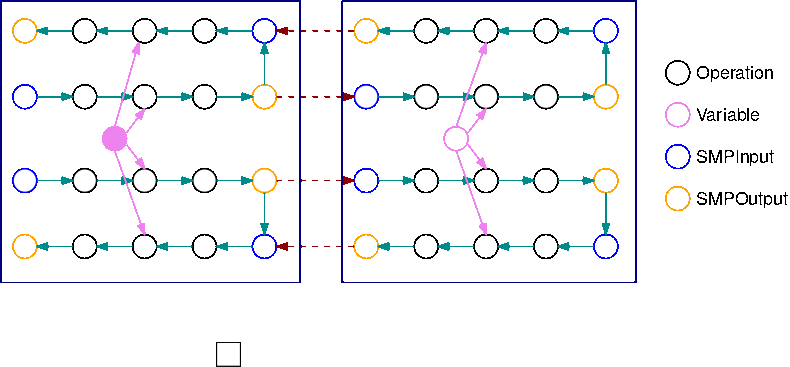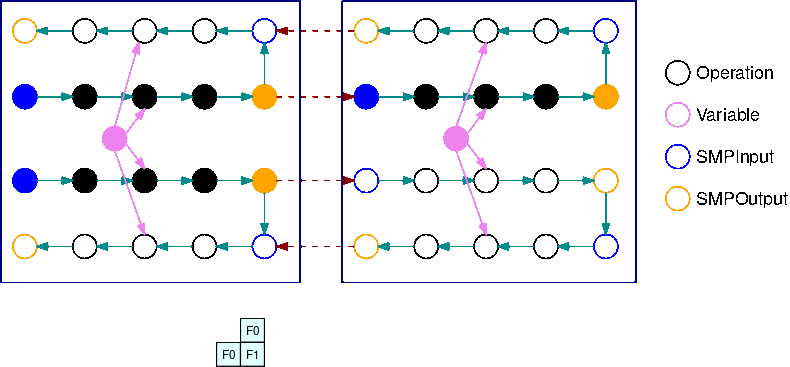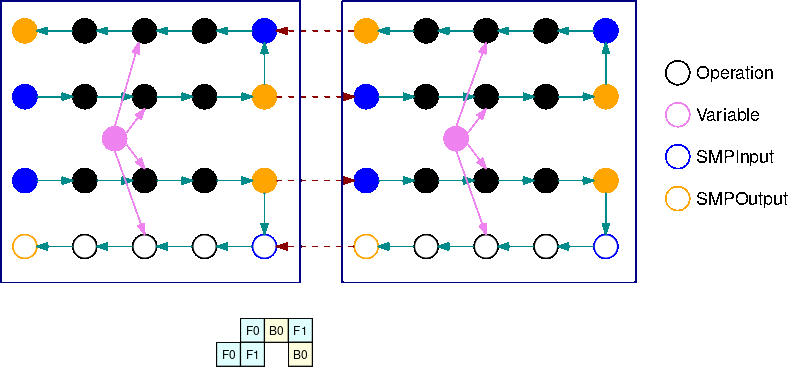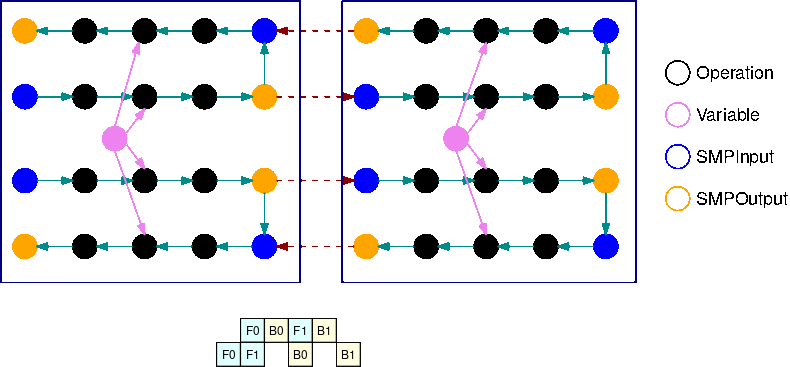
Este GIF muestra un ejemplo de un programa de ejecución de tuberías intercalado con B=2 microlotes y 2 subgráficos. Cada dispositivo ejecuta secuencialmente una de las réplicas de los subgráficos para mejorar el uso de la GPU. A medida que B crece, la fracción de los intervalos de tiempo de inactividad se reduce a cero. Siempre que llegue el momento de realizar un cálculo (hacia adelante o hacia atrás) en una réplica de subgráfico específica, la capa de canalización envía señales a las operaciones SMPInput azules correspondientes para que comiencen a ejecutarse.
Una vez calculados los gradientes de todos los microlotes de un único minilote, la biblioteca combina los gradientes de todos los microlotes para luego aplicarlos a los parámetros.
Pipeline Execution con PyTorch
Conceptualmente, la canalización sigue una idea similar en. PyTorch Sin embargo, dado que PyTorch no incluye gráficos estáticos, la PyTorch función de la biblioteca de paralelismo de modelos utiliza un paradigma de canalización más dinámico.
Por ejemplo TensorFlow, cada lote se divide en varios microlotes, que se ejecutan uno a la vez en cada dispositivo. Sin embargo, el programa de ejecución se gestiona a través de servidores de ejecución lanzados en cada dispositivo. Siempre que se necesite la salida de un submódulo colocado en otro dispositivo en el dispositivo actual, se envía una solicitud de ejecución al servidor de ejecución del dispositivo remoto junto con los tensores de entrada al submódulo. Luego, el servidor ejecuta este módulo con las entradas dadas y devuelve la respuesta al dispositivo actual.
Como el dispositivo actual está inactivo durante la ejecución remota del submódulo, la ejecución local del microlote actual se detiene y el tiempo de ejecución de la biblioteca cambia la ejecución a otro microlote en el que el dispositivo actual puede trabajar activamente. La priorización de los microlotes viene determinada por el programa de canalización elegido. En el caso de un programa de canalización intercalado, siempre que sea posible, se prioriza los microlotes que se encuentran en la fase anterior del cálculo.
