Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Mecanismo de clasificación cuando se utiliza una combinación de paralelismo de canalización y paralelismo de tensores
En esta sección se explica cómo funciona el mecanismo de clasificación del paralelismo de modelos con el paralelismo de tensores. Esto es una extensión de los conceptos básicos de clasificaciónsmp.tp_rank() tensorial, APIs para el rango paralelo de smp.pp_rank() canalización y para smp.rdp_rank() el rango paralelo de datos reducidos. Los grupos de proceso de comunicación correspondientes son grupo paralelo tensorial (TP_GROUP), grupo paralelo de canalización (PP_GROUP) y grupo paralelo de datos reducidos (RDP_GROUP). Estos grupos se definen de la siguiente manera:
-
Un grupo paralelo tensorial (
TP_GROUP) es un subconjunto uniformemente divisible del grupo paralelo de datos, sobre el cual tiene lugar la distribución tensorial paralela de los módulos. Cuando el grado de paralelismo de la canalización es 1,TP_GROUPes el mismo que el del grupo paralelo modelo (MP_GROUP). -
Un grupo paralelo de canalización (
PP_GROUP) es el grupo de procesos sobre los que tiene lugar el paralelismo de canalización. Cuando el grado de paralelismo de tensores es 1,PP_GROUPes igual queMP_GROUP. -
Un grupo paralelo de datos reducidos (
RDP_GROUP) es un conjunto de procesos que contienen las mismas particiones de paralelismo de canalización y las mismas particiones paralelas tensoriales, y realizan paralelismo de datos entre sí. Esto se denomina grupo paralelo de datos reducido porque es un subconjunto de todo el grupo de paralelismo de datos,DP_GROUP. Para los parámetros del modelo que se distribuyen dentro delTP_GROUP, la operaciónallreducedel gradiente se realiza solo para el grupo paralelo de datos reducidos, mientras que para los parámetros que no están distribuidos, el gradienteallreducese produce en todo el grupoDP_GROUP. -
Un grupo paralelo de modelos (
MP_GROUP) se refiere a un grupo de procesos que almacenan colectivamente todo el modelo. Consiste en la unión de losPP_GROUPs de todos los rangos que se encuentran en elTP_GROUPdel proceso actual. Cuando el grado de paralelismo de tensores es 1,MP_GROUPequivale aPP_GROUP. También es coherente con la definición existente deMP_GROUPde versiones anteriores desmdistributed. Tenga en cuenta que el actualTP_GROUPes un subconjunto del actualDP_GROUPy del actualMP_GROUP.
Para obtener más información sobre el proceso de comunicación APIs en la biblioteca de paralelismo de SageMaker modelos, consulte lo común API
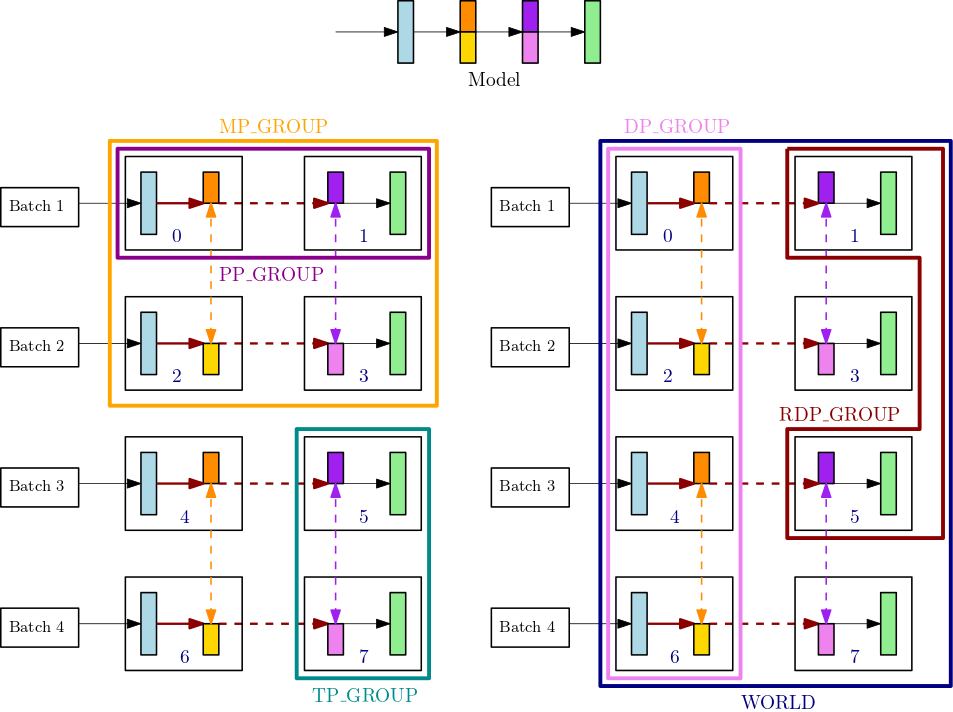
Por ejemplo, considere los grupos de procesos para un solo nodo con 8GPUs, donde el grado de paralelismo tensorial es 2, el grado de paralelismo de canalización es 2 y el grado de paralelismo de datos es 4. La parte central superior de la figura anterior muestra un ejemplo de un modelo con 4 capas. Las partes inferior izquierda e inferior derecha de la figura ilustran el modelo de 4 capas distribuido en 4 GPUs utilizando tanto el paralelismo de canalización como el paralelismo tensorial, donde el paralelismo tensorial se usa para las dos capas centrales. Estas dos figuras inferiores son copias simples para ilustrar diferentes líneas de límite de grupo. El modelo particionado se replica para lograr un paralelismo de datos entre 0-3 y 4-7. GPUs La figura inferior izquierda muestra las definiciones de MP_GROUP, PP_GROUP y TP_GROUP. La figura inferior derecha muestraRDP_GROUP, DP_GROUP y sobre el mismo conjunto de. WORLD GPUs Los gradientes de las capas y los sectores de capas que tienen el mismo color están agrupados en allreduce para obtener un paralelismo de datos. Por ejemplo, en la primera capa (azul claro) se transmiten las operaciones allreduce en DP_GROUP, mientras que en el segmento naranja oscuro de la segunda capa solo se transmiten las operaciones allreduce de dentro del RDP_GROUP de su proceso. Las flechas de color rojo oscuro en negrita representan los tensores con el lote completo TP_GROUP.
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
En este ejemplo, el paralelismo canalizado se produce entre los GPU pares (0,1); (2,3); (4,5) y (6,7). Además, el paralelismo de datos (allreduce) tiene lugar en GPUs 0, 2, 4, 6 e independientemente en GPUs 1, 3, 5, 7. El paralelismo tensorial ocurre en subconjuntos de DP_GROUP s, en los GPU pares (0,2); (1,3); (4,6) y (5,7).
