Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Paralelismo de datos partidos
El paralelismo de datos fragmentados es una técnica de entrenamiento distribuido que ahorra memoria y que divide el estado de un modelo (parámetros del modelo, gradientes y estados del optimizador) en un grupo paralelo de datos. GPUs
nota
El paralelismo de datos fragmentados está disponible en la biblioteca de paralelismo de modelos, versión 1.11.0 y versiones posteriores. PyTorch SageMaker
Al ampliar tu trabajo de entrenamiento a un clúster de GPU de gran tamaño, puedes reducir el consumo de memoria del modelo por GPU dividiendo el estado de entrenamiento del modelo en varias unidades. GPUs Esto ofrece dos ventajas: puede instalar modelos más grandes, que de otro modo se quedarían sin memoria con el paralelismo de datos estándar, o puede aumentar el tamaño del lote utilizando la memoria de la GPU liberada.
La técnica de paralelismo de datos estándar replica los estados de entrenamiento en el grupo paralelo de datos y realiza GPUs la agregación de gradientes en función de la operación. AllReduce El paralelismo de datos partidos modifica el procedimiento de entrenamiento distribuido de datos paralelos estándar para tener en cuenta la naturaleza partida de los estados del optimizador. Un grupo de rangos en los que se parten los estados del modelo y del optimizador se denomina grupo de partición. La técnica de paralelismo de datos fragmentados divide los parámetros entrenables de un modelo y los gradientes y estados del optimizador correspondientes en el grupo de fragmentación. GPUs
SageMaker La IA logra un paralelismo de datos fragmentados mediante la implementación de indicadores de ingresos medios, algo que se analiza en la entrada del blog Near-linear scaling of gigantic-model training on. AWSAWSAllGather Tras pasar cada capa hacia adelante o hacia atrás, MiCS vuelve a partir los parámetros para ahorrar memoria en la GPU. Durante el paso hacia atrás, el MIC reduce los gradientes y, al mismo tiempo, los fragmenta a lo largo GPUs de la operación. ReduceScatter Por último, MiCS aplica los gradientes locales reducidos y partidos a sus correspondientes particiones de parámetros locales, utilizando las particiones locales de los estados del optimizador. Para reducir la sobrecarga de comunicación, la biblioteca de paralelismo de SageMaker modelos busca previamente las siguientes capas en la fase de avance o retroceso y superpone la comunicación de red con el cálculo.
El estado de entrenamiento del modelo se replica en todos los grupos de partición. Esto significa que antes de aplicar los gradientes a los parámetros, la operación AllReduce debe realizarse en todos los grupos de partición, además de la operación ReduceScatter que se lleva a cabo dentro del grupo de partición.
En efecto, el paralelismo de datos partidos supone un equilibrio entre la sobrecarga de comunicación y la eficiencia de la memoria de la GPU. El uso del paralelismo de datos partidos aumenta el coste de la comunicación, pero el espacio de memoria por GPU (excluido el uso de memoria debido a las activaciones) se divide por el grado de paralelismo de los datos partidos, por lo que pueden caber modelos más grandes en el clúster de la GPU.
Seleccionar el grado de paralelismo de los datos partidos
Al seleccionar un valor para el grado de paralelismo de los datos partidos, el valor debe dividir uniformemente el grado de paralelismo de los datos. Por ejemplo, para un trabajo de paralelismo de datos de 8 vías, seleccione 2, 4 u 8 como grado de paralelismo de datos partidos. Al elegir el grado de paralelismo de los datos partidos, le recomendamos que comience con un número pequeño y vaya aumentado poco a poco hasta que el modelo quepa en la memoria y tenga el tamaño de lote deseado.
Seleccionar el tamaño del lote
Tras configurar el paralelismo de datos partidos, asegúrese de encontrar la configuración de entrenamiento más óptima que pueda ejecutarse correctamente en el clúster de la GPU. Para entrenar modelos de lenguaje grandes (LLM), comience con el tamaño de lote 1 y auméntelo gradualmente hasta llegar al punto en el que aparezca el error (OOM). out-of-memory Si encuentra el error OOM incluso con el tamaño de lote más pequeño, aplique un mayor grado de paralelismo de datos partidos o una combinación de paralelismo de datos partidos y paralelismo de tensores.
Temas
Cómo aplicar el paralelismo de datos partidos a su trabajo de entrenamiento
Para empezar con el paralelismo de datos fragmentados, aplique las modificaciones necesarias al guion de entrenamiento y configure el estimador con los parámetros. SageMaker PyTorch sharded-data-parallelism-specific Considere también tomar valores de referencia y cuadernos de ejemplo como punto de partida.
Adapta tu guion de entrenamiento PyTorch
Siga las instrucciones del paso 1: modifique un guion de PyTorch entrenamiento para envolver los objetos del modelo y del optimizador con los smdistributed.modelparallel.torch envoltorios de los módulos torch.nn.parallel ytorch.distributed.
(Opcional) Modificación adicional para registrar los parámetros externos del modelo
Si el modelo está creado con torch.nn.Module y usa parámetros que no están definidos en la clase de módulo, debe registrarlos manualmente en el módulo para que SMP recopile todos los parámetros. Para registrar los parámetros en un módulo, utilice smp.register_parameter(module,
parameter).
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
Configure el estimador SageMaker PyTorch
Al configurar un SageMaker PyTorch estimador enPaso 2: Inicie un trabajo de formación con el SDK de SageMaker Python, añada los parámetros para el paralelismo de datos fragmentados.
Para activar el paralelismo de datos fragmentados, añada el parámetro al estimador. sharded_data_parallel_degree SageMaker PyTorch Este parámetro especifica el número GPUs durante el cual se fragmenta el estado de entrenamiento. El valor de sharded_data_parallel_degree debe ser un número entero entre uno y el grado de paralelismo de los datos y debe dividir el grado de paralelismo de los datos de manera uniforme. Tenga en cuenta que la biblioteca detecta automáticamente el número de, GPUs por lo que el grado de paralelismo de los datos. Los siguientes parámetros adicionales están disponibles para configurar el paralelismo de datos partidos.
-
"sdp_reduce_bucket_size"(int, predeterminado: 5e8): especifica el tamaño de los cubos de gradiente del PyTorch DDPen cuanto al número de elementos del tipo d predeterminado. -
"sdp_param_persistence_threshold"(int, predeterminado: 1e6): especifica el tamaño de un tensor de parámetros en cuanto al número de elementos que pueden permanecer en cada GPU. El paralelismo de datos fragmentados divide cada tensor de parámetros en un grupo paralelo de GPUs datos. Si el número de elementos en el tensor de parámetros es menor que este umbral, el tensor de parámetros no se divide; esto ayuda a reducir la sobrecarga de comunicación porque el tensor de parámetros se replica en el paralelo de datos. GPUs -
"sdp_max_live_parameters"(int, predeterminado: 1e9): especifica el número máximo de parámetros que pueden estar simultáneamente en un estado de entrenamiento recombinado durante la pasada hacia adelante y hacia atrás. La búsqueda de parámetros con la operaciónAllGatherse detiene cuando el número de parámetros activos alcanza el umbral indicado. Tenga en cuenta que al aumentar este parámetro se incrementa el consumo de memoria. -
"sdp_hierarchical_allgather"(bool, predeterminado: true): si se establece enTrue, la operaciónAllGatherse ejecuta jerárquicamente; se ejecuta dentro de cada nodo primero, y luego se ejecuta a través de todos los nodos. En el caso de los trabajos de entrenamiento distribuidos con varios nodos, la operaciónAllGatherjerárquica se activa automáticamente. -
"sdp_gradient_clipping"(float, predeterminado: 1.0): especifica un umbral para recortar en gradiente la norma L2 de los gradientes antes de propagarlos hacia atrás a través de los parámetros del modelo. Cuando se activa el paralelismo de datos partidos, también se activa el recorte por gradiente. El umbral por defecto es1.0. Ajuste este parámetro si tiene el problema de la explosión de los gradientes.
El siguiente código muestra un ejemplo de cómo configurar el paralelismo de datos partidos.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
Configuraciones de referencia
El equipo de formación SageMaker distribuido proporciona las siguientes configuraciones de referencia que puede utilizar como punto de partida. Puede extrapolar las siguientes configuraciones para experimentar y estimar el uso de memoria de la GPU para configurar su modelo.
Paralelismo de datos partidos con colectivos SMDDP
| Modelo/número de parámetros | Número de instancias | Tipo de instancia | Longitud de secuencia | Tamaño de lote global | Tamaño de minilote | Grado de paralelismo de datos partidos |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
Por ejemplo, si aumenta la longitud de secuencia de un modelo de 20 000 millones de parámetros o aumenta el tamaño del modelo a 65 000 millones de parámetros, primero debe intentar reducir el tamaño del lote. Si el modelo sigue sin ajustarse al tamaño de lote más pequeño (el tamaño de lote de 1), intente aumentar el grado de paralelismo de modelos.
Paralelismo de datos partidos con paralelismo de tensores y colectivos NCCL
| Modelo/número de parámetros | Número de instancias | Tipo de instancia | Longitud de secuencia | Tamaño de lote global | Tamaño de minilote | Grado de paralelismo de datos partidos | Grado de tensor paralelo | Descarga de activación |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | Y |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | Y |
El uso combinado del paralelismo de datos fragmentados y el paralelismo tensorial resulta útil cuando se quiere incluir un modelo de lenguaje (LLM) de gran tamaño en un clúster a gran escala y, al mismo tiempo, utilizar datos de texto con una longitud de secuencia más larga, lo que lleva a utilizar un tamaño de lote más pequeño y, por lo tanto, gestionar el uso de la memoria de la GPU para entrenar con secuencias de texto más largas. LLMs Para obtener más información, consulte Paralelismo de datos partidos con paralelismo de tensores.
Para ver casos prácticos, puntos de referencia y más ejemplos de configuración, consulte la entrada del blog Nuevas mejoras de rendimiento en la biblioteca paralela de modelos Amazon SageMaker AI
Paralelismo de datos partidos con colectivos SMDDP
La biblioteca SageMaker de paralelismo de datos ofrece primitivas de comunicación colectiva (colectivos SMDDP) optimizadas para la infraestructura. AWS Logra la optimización al adoptar un patrón de all-to-all-type comunicación mediante el uso del Elastic Fabric Adapter (EFA)
nota
El paralelismo de datos fragmentados con SMDDP Collectives está disponible en la biblioteca de paralelismo de SageMaker modelos, versión 1.13.0 y versiones posteriores, y en la biblioteca de paralelismo de datos, versión 1.6.0 y versiones posteriores. SageMaker Consulte también Supported configurations para utilizar el paralelismo de datos partidos con los colectivos SMDDP.
En el paralelismo de datos partidos, que es una técnica de uso común en el entrenamiento distribuido a gran escala, el colectivo AllGather se utiliza para reconstituir los parámetros de la capa partida para los cálculos de la pasada hacia adelante y hacia atrás, en paralelo con el cálculo de la GPU. En el caso de los modelos de gran tamaño, es fundamental realizar la operación AllGather de forma eficiente para evitar problemas con la GPU y reducir la velocidad de entrenamiento. Cuando se activa el paralelismo de datos partidos, los colectivos SMDDP se agrupan en estos colectivos AllGather fundamentales para el rendimiento, lo que mejora el rendimiento del entrenamiento.
Entrenar con colectivos SMDDP
Cuando su trabajo de entrenamiento tenga activado el paralelismo de datos partidos y cumpla con Supported configurations, los colectivos SMDDP se activarán automáticamente. Internamente, los colectivos SMDDP optimizan el colectivo para que funcione en la infraestructura y recurren a la NCCL para todos los demás colectivos. AllGather AWS Además, en configuraciones no compatibles, todos los colectivos, incluidos AllGather, utilizan automáticamente el backend de los NCCL.
A partir de la versión 1.13.0 de la biblioteca de paralelismo de SageMaker modelos, el parámetro se añade a las opciones. "ddp_dist_backend" modelparallel El valor predeterminado de este parámetro de configuración es "auto", que utiliza los colectivos SMDDP siempre que sea posible y, de lo contrario, recurre a los NCCL. Para forzar a la biblioteca a utilizar siempre los NCCL, especifique "nccl" en el parámetro de configuración "ddp_dist_backend".
El siguiente ejemplo de código muestra cómo configurar un PyTorch estimador utilizando el paralelismo de datos fragmentados con el "ddp_dist_backend" parámetro, que está establecido en forma predeterminada y, por lo tanto, su adición es opcional. "auto"
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Configuraciones admitidas
La operación AllGather con los colectivos SMDDP se activa en los trabajos de entrenamiento cuando se cumplen todos los requisitos de configuración siguientes.
-
El grado de paralelismo de los datos partidos es superior a 1
-
Instance_countmayor que 1 -
Instance_typeigual aml.p4d.24xlarge -
SageMaker contenedor de entrenamiento para la versión 1.12.1 o posterior PyTorch
-
La biblioteca de paralelismo SageMaker de datos v1.6.0 o posterior
-
La biblioteca de paralelismo de SageMaker modelos v1.13.0 o posterior
Ajuste del rendimiento y de la memoria
Los colectivos SMDDP utilizan memoria de GPU adicional. Existen dos variables de entorno para configurar el uso de la memoria de la GPU en función de los diferentes casos de uso de entrenamiento de modelos.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESDurante la operaciónAllGatherSMDDP, el búfer de entradaAllGatherse copia en un búfer temporal para la comunicación entre nodos. La variableSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTEScontrola el tamaño (en bytes) de este búfer temporal. Si el tamaño del búfer temporal es menor que el tamaño del búfer de entradaAllGather, el colectivoAllGatherrecurre a los NCCL.-
Valor predeterminado: 16 * 1024 * 1024 (16 MB)
-
Valores aceptables: cualquier múltiplo de 8192
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTESLa variableSMDDP_AG_SORT_BUFFER_SIZE_BYTESconsiste en dimensionar el búfer temporal (en bytes) para almacenar los datos recopilados de la comunicación entre nodos. Si el tamaño de este búfer temporal es inferior a1/8 * sharded_data_parallel_degree * AllGather input size, el colectivoAllGatherrecurre a los NCCL.-
Valor predeterminado: 128 * 1024 * 1024 (128 MB)
-
Valores aceptables: cualquier múltiplo de 8192
-
Guía de ajuste de las variables de tamaño del búfer
Los valores predeterminados de las variables de entorno deberían funcionar bien en la mayoría de los casos de uso. Recomendamos ajustar estas variables solo si en el entrenamiento se produce el error (OOM). out-of-memory
En la siguiente lista, se describen algunos consejos de ajuste para reducir el consumo de memoria de la GPU de los colectivos SMDDP y, al mismo tiempo, conservar la ganancia de rendimiento que generan.
-
Ajustar
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
El tamaño del búfer de entrada
AllGatheres menor para los modelos más pequeños. Por lo tanto, el tamaño requerido paraSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpuede ser menor para los modelos con menos parámetros. -
El tamaño del búfer de
AllGatherentrada disminuye a medida quesharded_data_parallel_degreeaumenta, ya que el modelo se fragmenta más. GPUs Por lo tanto, el tamaño requerido paraSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpuede ser menor para tareas de entrenamiento con valores grandes parasharded_data_parallel_degree.
-
-
Ajustar
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
La cantidad de datos recopilados de la comunicación entre nodos es menor para los modelos con menos parámetros. Por lo tanto, el tamaño requerido para
SMDDP_AG_SORT_BUFFER_SIZE_BYTESpuede ser menor para estos modelos con un número menor de parámetros.
-
Es posible que algunos colectivos recurran a los NCCL; por lo tanto, es posible que no consiga el rendimiento de los colectivos SMDDP optimizados. Si hay memoria de GPU adicional disponible para su uso, puede considerar la posibilidad de aumentar los valores de SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES y SMDDP_AG_SORT_BUFFER_SIZE_BYTES para aprovechar la ganancia de rendimiento.
El siguiente código muestra cómo configurar las variables de entorno agregándolas al parámetro mpi_options de distribución del estimador. PyTorch
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Entrenamiento de precisión mixto con paralelismo de datos partidos
Para ahorrar aún más memoria en la GPU con números de punto flotante de precisión media y paralelismo de datos fragmentados, puede activar el formato de punto flotante de 16 bits (FP16) o el formato de punto flotante Brain
nota
El entrenamiento de precisión mixta con paralelismo de datos fragmentados está disponible en la biblioteca de paralelismo de modelos, versión 1.11.0 y versiones posteriores. SageMaker
FP16 Para el entrenamiento con paralelismo de datos fragmentados
Para ejecutar el FP16 entrenamiento con paralelismo de datos fragmentados, agréguelo al diccionario de configuración. "fp16": True" smp_options En el script de su entrenamiento, puede elegir entre las opciones de escalado de pérdidas estáticas y dinámicas a través del módulo smp.DistributedOptimizer. Para obtener más información, consulte FP16 Entrenamiento con paralelismo de modelos.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
Para BF16 entrenar con paralelismo de datos fragmentados
La función de paralelismo de datos fragmentados de la IA permite el entrenamiento en tipos de datos. SageMaker BF16 El tipo de BF16 datos usa 8 bits para representar el exponente de un número de coma flotante, mientras que el tipo de FP16 datos usa 5 bits. Conservar los 8 bits del exponente permite mantener la misma representación del exponente de un número de coma flotante () de precisión simple de 32 bits. FP32 Esto hace que la conversión entre un FP32 y otro sea BF16 más sencilla y mucho menos propensa a provocar problemas de desbordamiento o subflujo que suelen surgir durante el FP16 entrenamiento, especialmente cuando se entrenan modelos más grandes. Si bien ambos tipos de datos utilizan 16 bits en total, este aumento del rango de representación del exponente en el BF16 formato se produce a expensas de una menor precisión. Para el entrenamiento de modelos grandes, esta precisión reducida suele considerarse una compensación aceptable entre el alcance y la estabilidad del entrenamiento.
nota
Actualmente, el BF16 entrenamiento solo funciona cuando el paralelismo de datos fragmentados está activado.
Para ejecutar el BF16 entrenamiento con paralelismo de datos fragmentados, añádalo al diccionario de configuración. "bf16": True smp_options
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
Paralelismo de datos partidos con paralelismo de tensores
Si utiliza el paralelismo de datos partidos y también necesita reducir el tamaño del lote global, considere la posibilidad de utilizar el paralelismo de tensores con el paralelismo de datos partidos. Al entrenar un modelo grande con paralelismo de datos partidos en un clúster de procesamiento muy grande (normalmente 128 nodos o más), incluso un tamaño de lote pequeño por GPU da como resultado un tamaño de lote global muy grande. Puede provocar problemas de convergencia o problemas de bajo rendimiento computacional. En ocasiones, no es posible reducir el tamaño del lote por GPU solo con el paralelismo de datos partidos si un solo lote ya es grande y no puede reducirse más. En estos casos, el uso del paralelismo de datos partidos en combinación con el paralelismo de tensores ayuda a reducir el tamaño del lote global.
La elección de los grados paralelos y tensoriales paralelos óptimos para los datos partidos depende de la escala del modelo, el tipo de instancia y el tamaño del lote global que sea razonable para que el modelo converja. Le recomendamos que comience con un grado de tensor paralelo bajo para ajustar el tamaño del lote global al clúster de procesamiento a fin de resolver los out-of-memory errores de CUDA y lograr el mejor rendimiento. Consulte los dos casos de ejemplo siguientes para saber cómo la combinación de paralelismo tensorial y paralelismo de datos fragmentados le ayuda a ajustar el tamaño del lote global mediante la agrupación GPUs según el paralelismo del modelo, lo que se traduce en un menor número de réplicas de modelos y un tamaño de lote global más pequeño.
nota
Esta función está disponible en la biblioteca de paralelismo de modelos, versión 1.15, y es compatible con la versión 1.13.1. SageMaker PyTorch
nota
Esta característica está disponible para los modelos compatibles mediante la funcionalidad de paralelismo de tensores de la biblioteca. Para ver la lista de modelos compatibles, consulte Soporte listo para usar modelos Hugging Face Transformer. Tenga en cuenta también que debe pasar tensor_parallelism=True al argumento smp.model_creation mientras modifica el script de su entrenamiento. Para obtener más información, consulte el guion de formación en el repositorio de ejemplos de IA. train_gpt_simple.py
Ejemplo 1
Supongamos que queremos entrenar un modelo sobre un clúster de 1536 GPUs (192 nodos con 8 GPUs en cada uno), estableciendo el grado de paralelismo de los datos fragmentados en 32 (sharded_data_parallel_degree=32) y el tamaño del lote por GPU en 1, donde cada lote tiene una longitud de secuencia de 4096 fichas. En este caso, hay 1536 réplicas de modelos, el tamaño del lote global pasa a ser 1536 y cada lote global contiene unos 6 millones de tokens.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
Si se le añade un paralelismo de tensores, se puede reducir el tamaño del lote global. Un ejemplo de configuración puede ser establecer el grado de paralelismo del tensor en 8 y el tamaño del lote por GPU en 4. Esto forma 192 grupos tensoriales paralelos o 192 réplicas de modelos, donde cada réplica de modelo se distribuye en 8. GPUs El tamaño del lote de 4 es la cantidad de datos de entrenamiento por iteración y por grupo de tensores paralelos; es decir, cada réplica del modelo consume 4 lotes por iteración. En este caso, el tamaño del lote global pasa a ser 768 y cada lote global contiene unos 3 millones de tokens. Por lo tanto, el tamaño del lote global se reduce a la mitad en comparación con el caso anterior solo con el paralelismo de datos partidos.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
Ejemplo 2
Cuando se activan tanto el paralelismo de datos partidos como el paralelismo de tensores, la biblioteca primero aplica el paralelismo de tensores y parte el modelo en esta dimensión. Para cada rango paralelo tensorial, el paralelismo de datos se aplica según sharded_data_parallel_degree.
Por ejemplo, supongamos que queremos establecer 32 GPUs con un grado de paralelo tensorial de 4 (formando grupos de 4 GPUs), un grado de paralelo de datos fragmentados de 4 y terminando con un grado de replicación de 2. La asignación crea ocho grupos de GPU en función del grado paralelo del tensor de la siguiente manera: (0,1,2,3), (4,5,6,7), (8,9,10,11), (12,13,14,15), (16,17,18,19), (20,21,22,23), (24,25,26,27), (28,29,30,31). Es decir, cuatro GPUs forman un grupo tensorial paralelo. En este caso, el grupo paralelo de datos reducido para el rango 0 GPUs de los grupos paralelos de tensores sería. (0,4,8,12,16,20,24,28) El grupo paralelo de datos reducido se fragmenta en función del grado de paralelo de datos fragmentados de 4, lo que da como resultado dos grupos de replicación para el paralelismo de datos. GPUs(0,4,8,12)forman un grupo de fragmentación, que en conjunto contienen una copia completa de todos los parámetros del rango 0 del tensor paralelo, GPUs (16,20,24,28) y forman otro grupo similar. Otros rangos paralelos tensoriales también tienen grupos de partición y replicación similares.
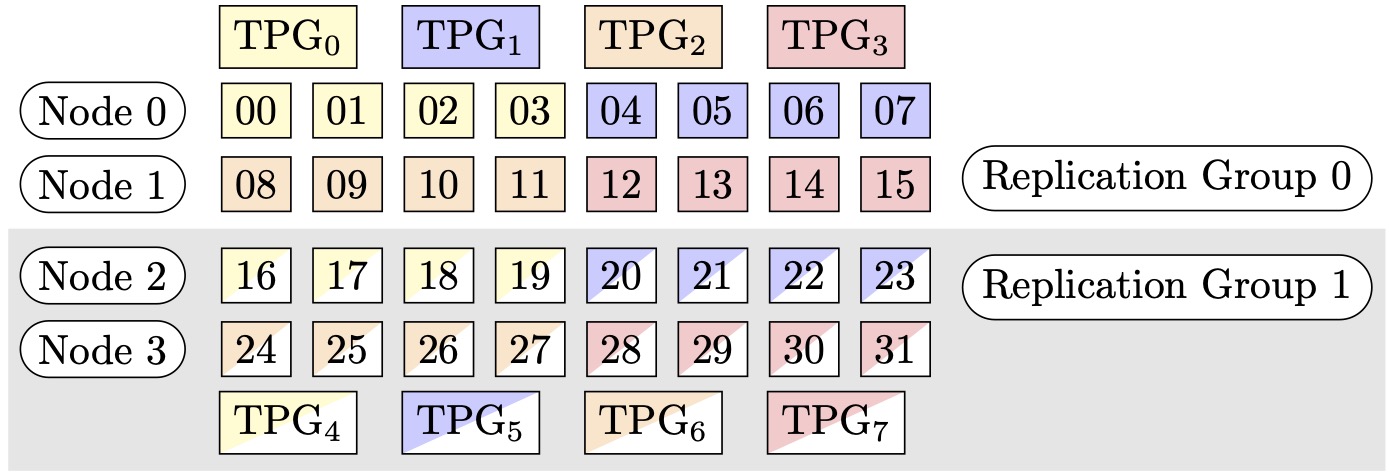
Figura 1: grupos de paralelismo de tensores para (nodos, grado de paralelismo de datos particionados, grado de paralelismo de tensores) = (4, 4, 4), donde cada rectángulo representa una GPU con índices de 0 a 31. GPUs Forman grupos de paralelismo tensorial de TPG a TPG. 0 7 Los grupos de replicación son ({TPG0, TPG4}, {TPG1, TPG5}, {TPG2, TPG6} y {TPG3, TPG7}); cada par de grupos de replicación comparte el mismo color pero se rellena de forma diferente.
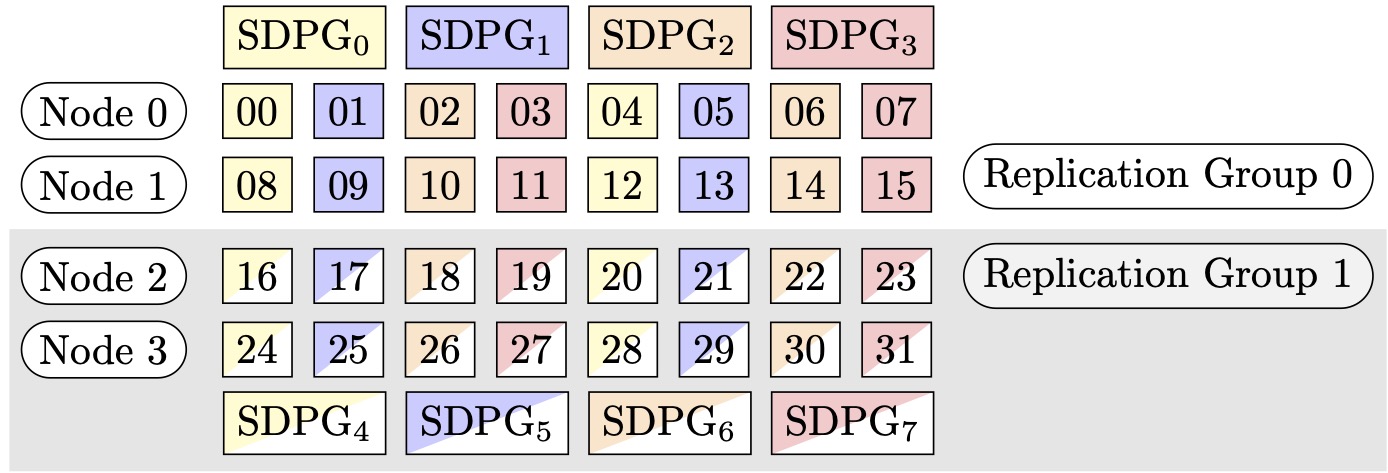
Figura 2: grupos de paralelismo de datos particionados para (nodos, grado de paralelismo de datos particionados, grado de paralelismo de tensores) = (4, 4, 4), donde cada rectángulo representa una GPU con índices de 0 a 31. La GPUs forma agrupa el paralelismo de datos fragmentados de SDPG a SDPG. 0 7 Los grupos de replicación son ({SDPG0, SDPG4}, {SDPG1, SDPG5}, {SDPG2, SDPG6} y {SDPG3, SDPG7}); cada par de grupos de replicación comparte el mismo color pero se rellena de forma diferente.
Cómo activar el paralelismo de datos partidos con el paralelismo de tensores
Para utilizar el paralelismo de datos fragmentados con el paralelismo tensorial, es necesario establecer ambos sharded_data_parallel_degree parámetros y en la configuración para la que se va a crear un objeto de la clase estimador. tensor_parallel_degree distribution SageMaker PyTorch
También debe activar prescaled_batch. Esto significa que, en lugar de que cada GPU lea su propio lote de datos, cada grupo paralelo de tensores leerá colectivamente un lote combinado del tamaño de lote elegido. Efectivamente, en lugar de dividir el conjunto de datos en partes iguales al número de GPUs (o tamaño paralelo de los datossmp.dp_size()), se divide en partes iguales al número de GPUs dividido por tensor_parallel_degree (también denominado tamaño paralelo de datos reducidosmp.rdp_size()). Para obtener más información sobre el lote preescalado, consulte Lote preescalado en la documentacióntrain_gpt_simple.py
El siguiente fragmento de código muestra un ejemplo de creación de un objeto PyTorch estimador basado en el escenario mencionado anteriormente en. Ejemplo 2
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
Consejos y consideraciones a tener en cuenta para utilizar el paralelismo de datos partidos
Tenga en cuenta lo siguiente al utilizar el paralelismo de datos fragmentados de la SageMaker biblioteca de paralelismo de modelos.
-
El paralelismo de datos fragmentados es compatible con el entrenamiento. FP16 Para ejecutar el FP16 entrenamiento, consulta la sección. FP16 Entrenamiento con paralelismo de modelos
-
El paralelismo de datos partidos es compatible con el paralelismo de tensores. Es posible que deba tener en cuenta los siguientes elementos para utilizar el paralelismo de datos partidos con el paralelismo de tensores.
-
Al utilizar el paralelismo de datos partidos con el paralelismo de tensores, las capas incrustadas también se distribuyen automáticamente en el grupo tensorial paralelo. En otras palabras, el parámetro
distribute_embeddingse establece automáticamente enTrue. Para obtener más información sobre el paralelismo de tensores, consulte Paralelismo de tensores. -
Tenga en cuenta que el paralelismo de datos partidos con el paralelismo de tensores utiliza actualmente los colectivos NCCL como base de la estrategia de entrenamiento distribuido.
Para obtener más información, consulte la sección Paralelismo de datos partidos con paralelismo de tensores.
-
-
El paralelismo de datos partidos actualmente no es compatible con el paralelismo de canalización o la partición del estado del optimizador. Para activar el paralelismo de datos partidos, desactive la partición del estado del optimizador y establezca el grado de paralelo de la canalización en 1.
-
Las funciones de verificación de activación y descarga de activación son compatibles con el paralelismo de datos partidos.
-
Para utilizar el paralelismo de datos partidos con la acumulación de gradientes, defina el argumento
backward_passes_per_stepen función del número de pasos de acumulación mientras agrupa el modelo con el módulosmdistributed.modelparallel.torch.DistributedModel. Esto garantiza que la operación AllReducede gradiente en todos los grupos de replicación del modelo (grupos de partición) se lleve a cabo en el límite de acumulación de gradientes. -
Puede comprobar sus modelos entrenados con paralelismo de datos fragmentados mediante los puntos de control de la biblioteca, y. APIs
smp.save_checkpointsmp.resume_from_checkpointPara obtener más información, consulte Verificación de un PyTorch modelo distribuido (para la biblioteca de paralelismo de SageMaker modelos v1.10.0 y versiones posteriores). -
El comportamiento del parámetro de configuración
delayed_parameter_initializationcambia con el paralelismo de datos partidos. Cuando estas dos funciones se activan simultáneamente, los parámetros se inicializan inmediatamente al crear el modelo de forma partida, en lugar de retrasar la inicialización de los parámetros, de modo que cada rango se inicializa y almacena su propia partición de parámetros. -
Cuando se activa el paralelismo de datos partidos, la biblioteca recorta el gradiente internamente al ejecutar la llamada
optimizer.step(). No es necesario utilizar una utilidad APIs para recortar con gradientes, como.torch.nn.utils.clip_grad_norm_()Para ajustar el valor límite para el recorte de gradiente, puede establecerlo mediante el sdp_gradient_clippingparámetro de la configuración del parámetro de distribución al construir el SageMaker PyTorch estimador, como se muestra en la sección. Cómo aplicar el paralelismo de datos partidos a su trabajo de entrenamiento
