Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Implementación de modelos para inferencia en tiempo real
importante
Las políticas de IAM personalizadas que permiten a Amazon SageMaker Studio o Amazon SageMaker Studio Classic crear SageMaker recursos de Amazon también deben conceder permisos para añadir etiquetas a esos recursos. El permiso para añadir etiquetas a los recursos es necesario porque Studio y Studio Classic etiquetan automáticamente todos los recursos que crean. Si una política de IAM permite a Studio y Studio Classic crear recursos, pero no permite el etiquetado, se pueden producir errores de tipo AccessDenied «» al intentar crear recursos. Para obtener más información, consulte Proporcione permisos para etiquetar los recursos de SageMaker IA.
AWS políticas gestionadas para Amazon SageMaker AIque otorgan permisos para crear SageMaker recursos ya incluyen permisos para añadir etiquetas al crear esos recursos.
Existen varias opciones para implementar un modelo mediante servicios de alojamiento de SageMaker IA. Puede implementar un modelo de forma interactiva con SageMaker Studio. O bien, puede implementar un modelo mediante programación mediante un AWS SDK, como el SDK de SageMaker Python o el SDK para Python (Boto3). También puede implementarlo mediante. AWS CLI
Antes de empezar
Antes de implementar un modelo de SageMaker IA, localice y tome nota de lo siguiente:
-
El Región de AWS lugar en el que se encuentra su bucket de Amazon S3
-
La ruta de URI de Amazon S3 donde se almacenan los artefactos del modelo
-
La función de IAM para la IA SageMaker
-
La ruta de registro de URI de Amazon ECR de Docker para la imagen personalizada que contiene el código de inferencia, o el marco y la versión de una imagen de Docker integrada que es compatible y por AWS
Para obtener una lista de las Servicios de AWS disponibles en cada una de ellas Región de AWS, consulte Region Maps
importante
El bucket de Amazon S3 donde se almacenan los artefactos del modelo debe almacenarse en la misma Región de AWS que la del modelo que está creando.
Utilización de recursos compartidos con varios modelos
Puede implementar uno o más modelos en un punto final con Amazon SageMaker AI. Cuando varios modelos comparten un punto de conexión, utilizan conjuntamente los recursos que se alojan allí, como, por ejemplo, las instancias de computación de ML, las CPU y los aceleradores. La forma más flexible de implementar varios modelos en un punto de conexión es definir cada modelo como un componente de inferencia.
Componentes de inferencias
Un componente de inferencia es un objeto de alojamiento de SageMaker IA que puede utilizar para implementar un modelo en un punto final. En la configuración del componente de inferencia, especifique el modelo, el punto de conexión y la forma en que el modelo utiliza los recursos que aloja el punto de conexión. Para especificar el modelo, puede especificar un objeto del modelo de SageMaker IA o puede especificar directamente los artefactos y la imagen del modelo.
En la configuración, puede optimizar la utilización de los recursos adaptando la forma en que se asignan al modelo los aceleradores, la memoria y los núcleos de CPU necesarios. Puede implementar varios componentes de inferencia en un punto de conexión, donde cada componente de inferencia incluya un modelo y las necesidades de utilización de recursos de dicho modelo.
Tras implementar un componente de inferencia, puedes invocar directamente el modelo asociado cuando utilices la InvokeEndpoint acción en la SageMaker API.
Los componentes de inferencia proporcionan las siguientes ventajas:
- Flexibilidad
-
El componente de inferencia desacopla los detalles del alojamiento del modelo del propio punto de conexión. Esto proporciona más flexibilidad y control sobre cómo se alojan y dan servicio los modelos con un punto de conexión. Puede alojar varios modelos en la misma infraestructura y puede añadir o eliminar modelos de un punto de conexión según sea necesario. Puede actualizar cada modelo de forma independiente.
- Escalabilidad
-
Puede especificar el número de copias de cada modelo que desee alojar y puede establecer un número mínimo de copias para garantizar que el modelo se cargue en la cantidad necesaria para dar servicio a las solicitudes. Puede reducir verticalmente a cero cualquier copia de un componente de inferencia, lo que deja espacio para que otra copia se escale verticalmente.
SageMaker La IA empaqueta tus modelos como componentes de inferencia cuando los despliegas mediante:
-
SageMaker Studio Classic.
-
El SDK de SageMaker Python para implementar un objeto modelo (en el que se establece el tipo de punto final
EndpointType.INFERENCE_COMPONENT_BASED). -
El AWS SDK para Python (Boto3) para definir
InferenceComponentlos objetos que se implementan en un punto final.
Implemente modelos con SageMaker Studio
Complete los siguientes pasos para crear e implementar su modelo de forma interactiva a través de SageMaker Studio. Para obtener más información sobre Studio, consulte la documentación de Studio. Para obtener más información sobre varios escenarios de implementación, consulte el blog Package and deploy modelos de ML clásicos y LLM fácilmente con Amazon SageMaker AI —
Preparación de los artefactos y los permisos
Complete esta sección antes de crear un modelo en Studio. SageMaker
Tiene dos opciones para traer los artefactos y crear un modelo en Studio:
-
Puede traer un archivo
tar.gzpreempaquetado, que debería incluir los artefactos del modelo, los códigos de inferencia personalizados y todas las dependencias enumeradas en un archivorequirements.txt. -
SageMaker La IA puede empaquetar tus artefactos por ti. Solo tienes que incluir los artefactos del modelo sin procesar y cualquier dependencia en un
requirements.txtarchivo, y la SageMaker IA puede proporcionarte el código de inferencia predeterminado (o puedes anular el código predeterminado por tu propio código de inferencia personalizado). SageMaker La IA admite esta opción para los siguientes marcos: XGBoost. PyTorch
Además de incorporar tu modelo, tu función AWS Identity and Access Management (IAM) y un contenedor de Docker (o el marco y la versión deseados para los que SageMaker AI tiene un contenedor prediseñado), también debes conceder permisos para crear e implementar modelos a través de AI Studio. SageMaker
Debes tener la AmazonSageMakerFullAccesspolítica asociada a tu función de IAM para poder acceder a la SageMaker IA y a otros servicios relevantes. Para ver los precios de los tipos de instancias en Studio, también debes adjuntar la AWS PriceListServiceFullAccesspolítica (o, si no quieres adjuntar la política completa, más específicamente, la pricing:GetProducts acción).
Si decide cargar los artefactos del modelo al crear un modelo (o cargar un archivo de carga útil de muestra para obtener recomendaciones de inferencia), debe crear un bucket de Amazon S3. El nombre del bucket debe ir precedido de la palabra SageMaker AI. También se aceptan capitalizaciones alternativas de SageMaker IA: Sagemaker o. sagemaker
Recomendamos utilizar la convención de nomenclatura de los buckets sagemaker-{. Este bucket se utiliza para almacenar los artefactos que cargue.Region}-{accountID}
Tras crear el bucket, asocie la siguiente política de CORS (uso compartido de recursos entre orígenes) al bucket:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
Puede asociar una política de CORS a un bucket de Amazon S3 mediante cualquiera de los siguientes métodos:
-
A través de la página Edit cross-origin resource sharing (CORS)
de la consola de Amazon S3 -
Uso de la API de Amazon S3 PutBucketCors
-
Mediante el comando put-bucket-cors AWS CLI :
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
Creación de un modelo implementable
En este paso, debe crear una versión desplegable de su modelo en SageMaker IA. Para ello, debe proporcionar sus artefactos junto con especificaciones adicionales, como el contenedor y el marco que desee, cualquier código de inferencia personalizado y la configuración de red.
Cree un modelo desplegable en SageMaker Studio de la siguiente manera:
-
Abre la aplicación SageMaker Studio.
-
En el panel de navegación izquierdo, elija Models (Modelos).
-
Seleccione la pestaña Modelos implementables.
-
En la página Modelos implementables, elija Crear.
-
En la página Crear modelo implementable, en el campo Nombre del modelo, introduzca un nombre para el modelo.
Hay varias secciones más que puede completar en la página Crear modelo implementable.
La sección Definición de contenedor tiene un aspecto similar al de la captura de pantalla siguiente:
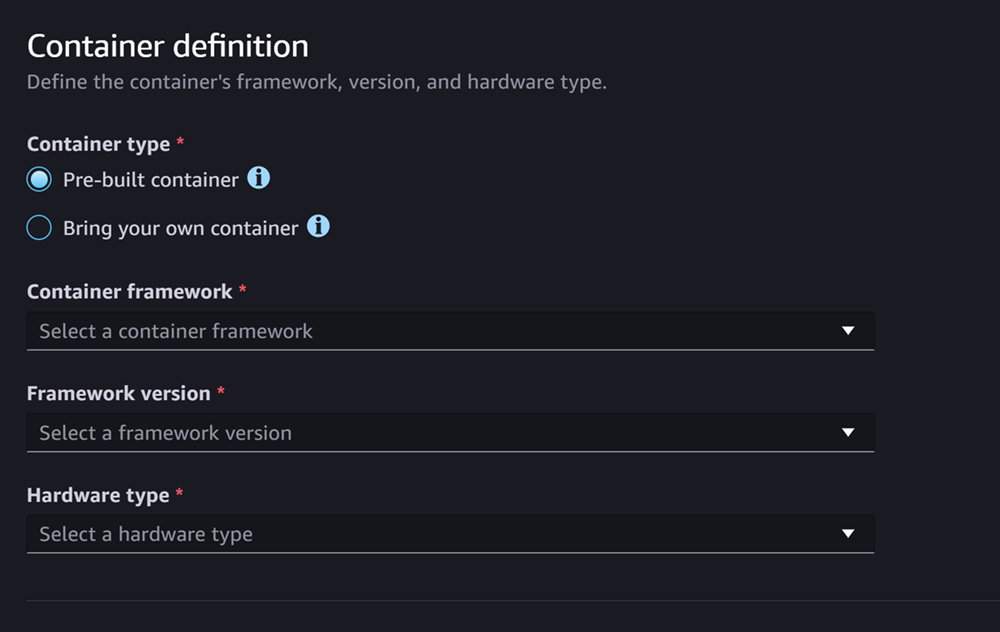
Para el registro Definición de contenedor sección, haga lo siguiente:
-
Para el tipo de Pre-builtcontenedor, selecciona un contenedor si quieres usar un contenedor gestionado por SageMaker IA, o selecciona Traiga su propio contenedor si tiene su propio contenedor.
-
Si seleccionaste Pre-built un contenedor, selecciona el marco del contenedor, la versión del marco y el tipo de hardware que deseas usar.
-
Si ha seleccionado Traiga su propio contenedor, introduzca una ruta de Amazon ECR como Ruta de ECR a la imagen del contenedor.
A continuación, complete la sección Artefactos, que tiene un aspecto similar al de la captura de pantalla siguiente:

Para el registro Artefactos sección, haga lo siguiente:
-
Si utilizas uno de los marcos compatibles con la SageMaker IA para empaquetar artefactos modelo (PyTorch o XGBoost), para Artifacts, puedes elegir la opción Cargar artefactos. Con esta opción, solo tienes que especificar los artefactos del modelo sin procesar, cualquier código de inferencia personalizado que tengas y tu archivo requirements.txt, y SageMaker AI se encargará de empaquetar el archivo por ti. Haga lo siguiente:
-
En Artefactos, seleccione Cargar artefactos para seguir proporcionando los archivos. De lo contrario, si ya tiene un archivo
tar.gzque incluye los archivos del modelo, el código de inferencia y el archivorequirements.txt, seleccione Introducir el URI de S3 para los artefactos preempaquetados. -
Si has decidido cargar tus artefactos, para el depósito de S3, introduce la ruta de Amazon S3 hasta un depósito en el que quieras que la SageMaker IA almacene tus artefactos después de empaquetarlos por ti. A continuación, complete los pasos siguientes.
-
En Cargar artefactos de modelos, cargue los archivos del modelo.
-
En Código de inferencia, selecciona Usar código de inferencia predeterminado si quieres usar el código predeterminado que proporciona la SageMaker IA para realizar inferencias. De lo contrario, seleccione Cargar código de inferencia personalizado para utilizar su propio código de inferencia.
-
En Cargar requirements.txt, cargue un archivo de texto que enumere las dependencias que desee instalar en el tiempo de ejecución.
-
-
Si no utilizas un marco compatible con la SageMaker IA para empaquetar artefactos modelo, Studio te mostrará la opción de Pre-packagedartefactos y tendrás que proporcionar todos los artefactos ya empaquetados como un archivo.
tar.gzHaga lo siguiente:-
En el caso de Pre-packaged los artefactos, seleccione Introducir el URI de S3 para los artefactos del modelo preempaquetados si ya ha cargado el
tar.gzarchivo en Amazon S3. Seleccione Cargar artefactos modelo preempaquetados si desea cargar su archivo directamente a SageMaker AI. -
Si ha seleccionado Introducir el URI de S3 para los artefactos del modelo preempaquetados, introduzca la ruta de Amazon S3 al archivo para URI de S3. De lo contrario, seleccione y cargue el archivo desde la máquina local.
-
La siguiente sección es Seguridad, que tiene un aspecto similar al de la captura de pantalla siguiente:
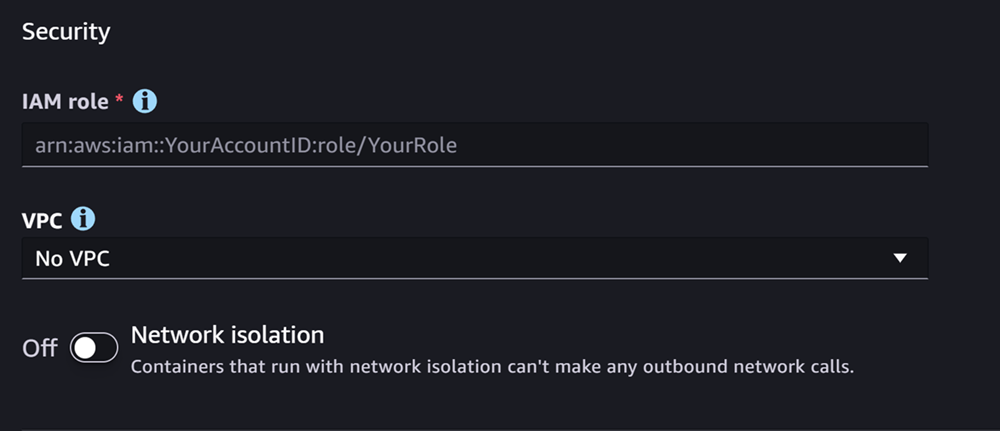
Para el registro Seguridad sección, haga lo siguiente:
-
En Rol de IAM, escriba el ARN de un rol de IAM.
-
(Opcional) En Nube privada virtual (VPC), puede seleccionar una Amazon VPC para almacenar la configuración y los artefactos del modelo.
-
(Opcional) Active el conmutador de Aislamiento de red si desea restringir el acceso a Internet por parte del contenedor.
Por último, si lo desea, puede completar la sección Opciones avanzadas, que tiene un aspecto similar al de la captura de pantalla siguiente:
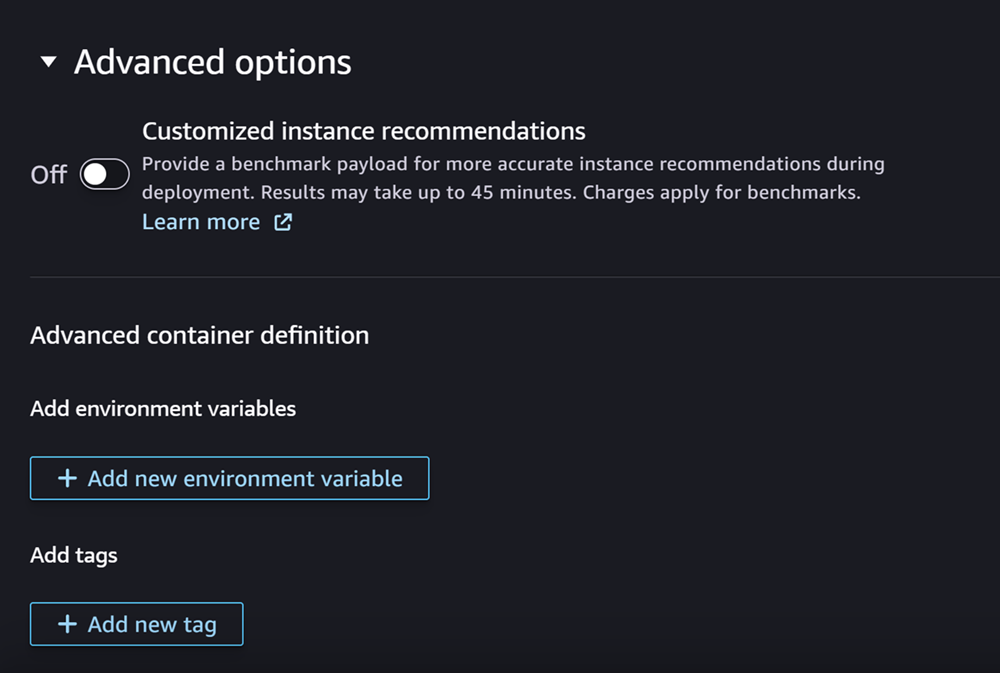
(Opcional) Para Opciones avanzadas sección, haga lo siguiente:
-
Activa la opción Recomendaciones de instancias personalizadas si quieres ejecutar un trabajo de Amazon SageMaker Inference Recommender en tu modelo después de su creación. El Recomendador de inferencias es una característica que le proporciona los tipos de instancias recomendados para optimizar el rendimiento y el costo de las inferencias. Puede ver estas recomendaciones de instancias al prepararse para implementar el modelo.
-
En Añadir variables de entorno, introduzca una variable de entorno para el contenedor como pares clave-valor.
-
En Etiquetas, introduzca cualquier etiqueta como pares clave-valor.
-
Una vez finalizada la configuración del modelo y del contenedor, elija Crear modelo implementable.
Ahora debería tener un modelo en SageMaker Studio listo para su implementación.
Implementación del modelo
Por último, implemente el modelo que ha configurado en el paso anterior en un punto de conexión HTTPS. Puede implementar un solo modelo o varios modelos en el punto de conexión.
Compatibilidad con modelos y puntos de conexión
Antes de implementar un modelo en un punto de conexión, el modelo y el punto de conexión deben ser compatibles y tener los mismos valores para los siguientes ajustes:
-
El rol de IAM
-
La Amazon VPC, incluidos sus grupos de seguridad y subredes
-
El aislamiento de red (habilitado o deshabilitado)
Studio impide implementar modelos en puntos de conexión no compatibles de las siguientes maneras:
-
Si intentas implementar un modelo en un nuevo punto final, la SageMaker IA configura el punto final con una configuración inicial que sea compatible. Si crea incompatibilidad al cambiar estos ajustes, Studio mostrará una alerta e impedirá la implementación.
-
Si intenta realizar la implementación en un dispositivo de punto de conexión existente y ese punto de conexión no es compatible, Studio mostrará una alerta e impedirá la implementación.
-
Si intenta añadir varios modelos a una implementación, Studio le impedirá implementar modelos que no sean compatibles entre sí.
Si Studio muestra la alerta sobre la incompatibilidad entre el modelo y el punto de conexión, puede seleccionar Ver detalles en la alerta para ver los ajustes que no son compatibles.
Una forma de implementar un modelo es hacer lo siguiente en Studio:
-
Abra la aplicación SageMaker Studio.
-
En el panel de navegación izquierdo, elija Models (Modelos).
-
En la página de modelos, seleccione uno o más modelos de la lista de modelos de SageMaker IA.
-
Elija Implementar.
-
En Nombre de punto de conexión, abra el menú desplegable. Puede seleccionar un punto de conexión existente o puede crear un nuevo punto de conexión en el que implementar el modelo.
-
En Tipo de instancia, seleccione el tipo de instancia que desea utilizar para el punto de conexión. Si anteriormente ha realizado un trabajo de Recomendador de inferencias para el modelo, los tipos de instancias recomendados aparecerán en la lista en el título Recomendado. De lo contrario, se mostrarán algunas Instancias potenciales que podrían ser adecuadas para el modelo.
Compatibilidad de tipos de instancia para JumpStart
Si vas a implementar un JumpStart modelo, Studio solo muestra los tipos de instancias compatibles con el modelo.
-
En Recuento inicial de instancias, introduzca el número inicial de instancias que le gustaría aprovisionar para el punto de conexión.
-
En Recuento máximo de instancias, especifique el número máximo de instancias que el punto de conexión puede aprovisionar cuando se escale verticalmente para adaptarse a un aumento del tráfico.
-
Si el modelo que vas a implementar es uno de los JumpStart LLM más utilizados en Model Hub, aparecerá la opción Configuraciones alternativas después de los campos tipo de instancia y recuento de instancias.
Para los JumpStart LLM más populares, AWS tiene tipos de instancias previamente evaluados para optimizar el costo o el rendimiento. Estos datos pueden ayudarle a decidir el tipo de instancia que desea usar para implementar el LLM. Elija Configuraciones alternativas para abrir un cuadro de diálogo que incluya los datos previamente evaluados. El panel tiene un aspecto similar al de la captura de pantalla siguiente:
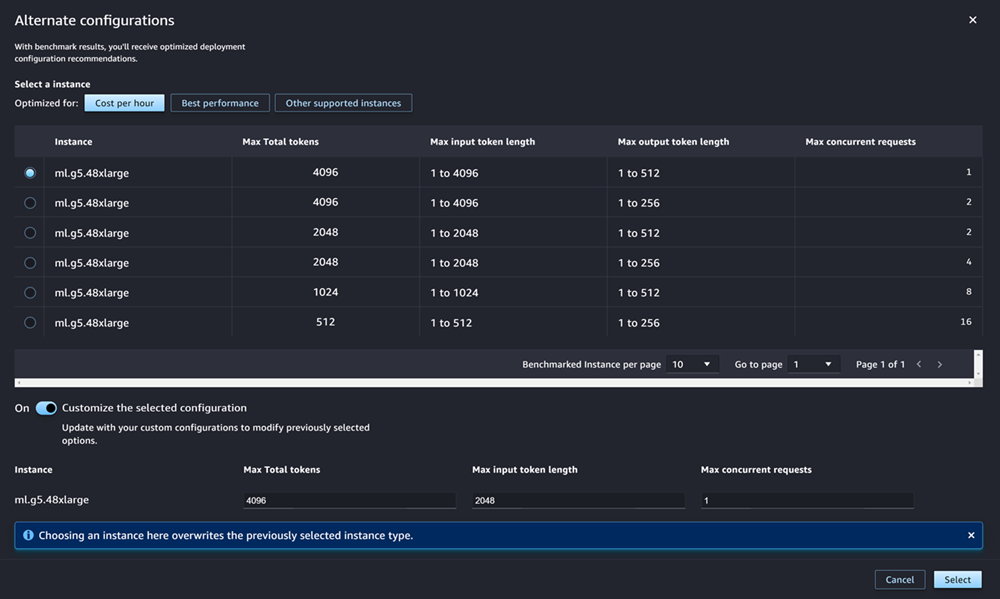
En el cuadro Configuraciones alternativas, haga lo siguiente:
-
Seleccione un tipo de instancia. Puede elegir Costo por hora o Mejor rendimiento para ver los tipos de instancias que optimizan el costo o el rendimiento para el modelo especificado. También puede seleccionar Otras instancias compatibles para ver una lista de otros tipos de instancias que son compatibles con el JumpStart modelo. Tenga en cuenta que al seleccionar aquí un tipo de instancia se sobrescribirá cualquier selección de instancia anterior especificada en el paso 6.
-
(Opcional) Active el conmutador de Personalizar la configuración seleccionada para especificar las opciones Número total máximo de tokens (el número máximo de tokens que desea permitir, que es la suma de los tokens de entrada y la salida generada por el modelo), Longitud máxima del token de entrada (el número máximo de tokens que desea permitir para la entrada de cada solicitud) y Número máximo de solicitudes simultáneas (el número máximo de solicitudes que el modelo puede procesar a la vez).
-
Elija Seleccionar para confirmar el tipo de instancia y los ajustes de configuración.
-
-
El campo Modelo ya debería estar completado con el nombre del modelo o los modelos que va a implementar. Puede elegir Añadir modelo para añadir más modelos a la implementación. En cada modelo que añada, complete los siguientes campos:
-
En Número de núcleos de CPU, introduzca los núcleos de CPU que desea dedicar al uso del modelo.
-
En Número mínimo de copias, introduzca el número mínimo de copias del modelo que desee alojar en el punto de conexión en un momento determinado.
-
En Memoria mínima de CPU (MB), introduzca la cantidad mínima de memoria (en MB) que requiere el modelo.
-
En Memoria máxima de CPU (MB), introduzca la cantidad máxima de memoria (en MB) que desea permitir que utilice el modelo.
-
-
(Opcional) En Opciones avanzadas, realice lo siguiente:
-
Para el rol de IAM, usa el rol de ejecución de IAM de SageMaker IA predeterminado o especifica tu propio rol con los permisos que necesitas. Tenga en cuenta que este rol de IAM debe ser el mismo que el que ha especificado al crear el modelo implementable.
-
En Nube privada virtual (VPC), puede especificar una VPC en la que desee alojar el punto de conexión.
-
En la clave KMS de cifrado, seleccione una AWS KMS clave para cifrar los datos del volumen de almacenamiento adjunto a la instancia de procesamiento de aprendizaje automático que aloja el punto final.
-
Active el conmutador de Habilitar el aislamiento de red para restringir el acceso a Internet por parte del contenedor.
-
En Configuración de tiempo de espera, introduzca los valores de los campos Tiempo de espera de descarga de datos del modelo (segundos) y Tiempo de espera de comprobación de estado de inicio del contenedor (segundos). Estos valores determinan el tiempo máximo que permite la SageMaker IA para descargar el modelo en el contenedor y ponerlo en marcha, respectivamente.
-
En Etiquetas, introduzca cualquier etiqueta como pares clave-valor.
nota
SageMaker La IA configura la función de IAM, la VPC y los ajustes de aislamiento de la red con valores iniciales que son compatibles con el modelo que se está implementando. Si crea incompatibilidad al cambiar estos ajustes, Studio mostrará una alerta e impedirá la implementación.
-
Tras configurar las opciones, la página tendrá un aspecto similar al de la captura de pantalla siguiente.
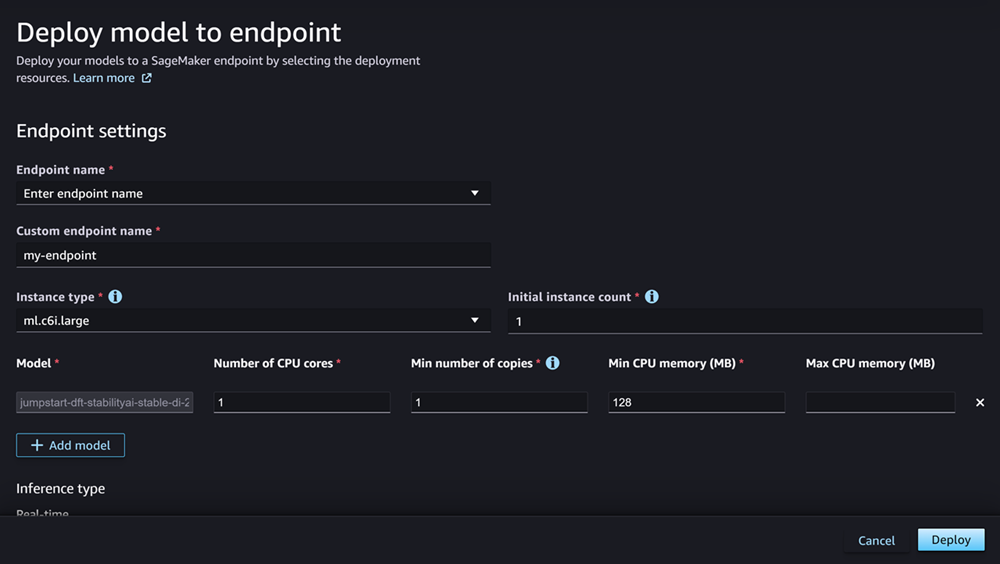
Tras configurar la implementación, elija Implementar para crear el punto de conexión e implementar el modelo.
Implementación de modelos con los Python SDK
Con el SDK de SageMaker Python, puede crear su modelo de dos maneras. La primera consiste en crear un objeto de modelo a partir de la clase Model o ModelBuilder. Si utiliza la clase Model para crear el objeto Model, debe especificar el paquete del modelo o el código de inferencia (según el servidor del modelo), los scripts para administrar la serialización y deserialización de los datos entre el cliente y el servidor y cualquier dependencia que deba cargarse en Amazon S3 para su consumo. La segunda manera de crear el modelo consiste en utilizar ModelBuilder para el que proporciona los artefactos del modelo o el código de inferencia. ModelBuilder captura automáticamente las dependencias, infiere las funciones de serialización y deserialización necesarias y empaqueta las dependencias para crear el objeto Model. Para obtener más información acerca de ModelBuilder, consulte Cree un modelo en Amazon SageMaker AI con ModelBuilder.
En la siguiente sección se describen ambos métodos para crear el modelo e implementar el objeto de modelo.
Configuración
En los siguientes ejemplos se prepara el proceso de implementación de un modelo. Importan las bibliotecas necesarias y definen la URL de S3 que localiza los artefactos del modelo.
ejemplo URL de artefactos del modelo
El siguiente código crea un ejemplo de URL de Amazon S3. La URL localiza los artefactos del modelo de un modelo previamente entrenado en un bucket de Amazon S3.
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
La URL completa de Amazon S3 se almacena en la variable model_url, que se utiliza en los ejemplos siguientes.
Descripción general de
Existen varias formas de implementar modelos con el SDK de SageMaker Python o el SDK para Python (Boto3). En las siguientes secciones se resumen los pasos que debe seguir para varios métodos posibles. Estos pasos se muestran en los ejemplos siguientes.
Configuración
En los siguientes ejemplos se configuran los recursos que necesita para implementar un modelo en un punto de conexión.
Implementación
En los siguientes ejemplos se implementa un modelo en un punto de conexión.
Implemente modelos con AWS CLI
Puede implementar un modelo en un punto final mediante el AWS CLI.
Descripción general de
Al implementar un modelo con AWS CLI, puede implementarlo con o sin un componente de inferencia. En las secciones siguientes se resumen los comandos que se ejecutan en ambos métodos. Estos comandos se muestran en los ejemplos siguientes.
Configuración
En los siguientes ejemplos se configuran los recursos que necesita para implementar un modelo en un punto de conexión.
Implementación
En los siguientes ejemplos se implementa un modelo en un punto de conexión.
