Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Entornos de RL en Amazon SageMaker AI
Amazon SageMaker AI RL utiliza entornos para imitar escenarios del mundo real. Teniendo en cuenta el estado actual del entorno y una acción realizada por el agente o los agentes, el simulador procesa el impacto de la acción y devuelve el siguiente estado y una recompensa. Los simuladores son útiles en los casos en los que no es seguro entrenar a un agente en el mundo real (por ejemplo, pilotar un dron) o si el algoritmo de RL tarda mucho tiempo en converger (por ejemplo, cuando juega al ajedrez).
En el siguiente diagrama se muestra un ejemplo de las interacciones con un simulador para un juego de carreras automovilísticas.
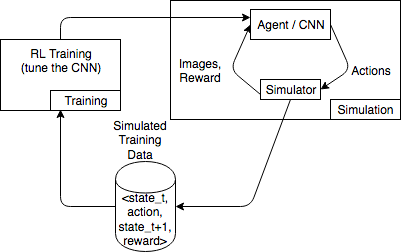
El entorno de simulación se compone de un agente y un simulador. Aquí, una red neuronal convolucional (CNN) consume imágenes del simulador y genera acciones para controlar el mando de juego. Con varias simulaciones, este entorno genera datos de entrenamiento con el formato state_t, action, state_t+1 y reward_t+1. La definición de la recompensa no es una cuestión trivial y repercute en la calidad del modelo de RL. Queremos proporcionar algunos ejemplos de las funciones de recompensa, pero queremos que el usuario las puedas configurar.
Temas
Utilice la interfaz OpenAI Gym para entornos en SageMaker AI RL
Para utilizar los entornos de OpenAI Gym en SageMaker AI RL, utilice los siguientes elementos de la API. Para obtener más información acerca de OpenAI Gym, consulte la Documentación de Ray
-
env.action_space: define las acciones que el agente puede realizar, especifica si cada acción es continua o discreta y especifica el mínimo y el máximo si la acción es continua. -
env.observation_space: define las observaciones que el agente recibe desde el entorno, así como el mínimo y el máximo para observaciones continuas. -
env.reset(): inicializa un episodio de entrenamiento. La funciónreset()devuelve el estado inicial del entorno y el agente utiliza el estado inicial para ejecutar su primera acción. A continuación, la acción se envía astep()repetidamente hasta que el episodio alcanza un estado terminal. Cuandostep()regresadone = True, el episodio finaliza. El conjunto de herramientas de RL reinicializa el entorno llamando areset(). -
step(): toma la acción del agente como entrada y produce el siguiente estado del entorno, la recompensa, si el episodio ha terminado y un diccionario deinfopara comunicar información de depuración. Es responsabilidad del entorno validar las entradas. -
env.render(): se utiliza para entornos que tienen visualización. El conjunto de herramientas de RL llama a esta función para capturar visualizaciones del entorno después de cada llamada a la funciónstep().
Usa entornos Open-Source
Puedes usar entornos de código abierto, como EnergyPlus y RoboSchool, en SageMaker AI RL, creando tu propio contenedor. Para obtener más información al respecto EnergyPlus, consulte https://energyplus.net/
Utilizar entornos comerciales
Puede utilizar entornos comerciales, como MATLAB y Simulink, en SageMaker AI RL creando su propio contenedor. Debe administrar sus propias licencias.
