Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Implemente modelos con Amazon SageMaker Serverless Inference
Amazon SageMaker Serverless Inference es una opción de inferencia diseñada específicamente que le permite implementar y escalar modelos de aprendizaje automático sin configurar ni administrar ninguna de las infraestructuras subyacentes. On-demand La inferencia sin servidor es ideal para cargas de trabajo que tienen períodos de inactividad entre picos de tráfico y que pueden tolerar los arranques en frío. Los puntos de conexión sin servidor lanzan automáticamente los recursos informáticos y los amplían y reducen en función del tráfico, lo que elimina la necesidad de elegir tipos de instancias o de gestionar las políticas de escalado. Esto acaba con el trabajo pesado e indiferenciado que supone seleccionar y administrar los servidores. La inferencia sin servidor se integra con AWS Lambda para ofrecerle alta disponibilidad, tolerancia a errores integrada y escalado automático. Con un modelo de pago por uso, la inferencia sin servidor es una opción rentable si tiene un patrón de tráfico poco frecuente o impredecible. Cuando no haya solicitudes, la inferencia sin servidor reduce su punto de conexión a 0, lo que le ayuda a minimizar los costes. Para obtener más información sobre los precios de Serverless Inference bajo demanda, consulta Amazon SageMaker
Si lo desea, también puede utilizar la simultaneidad aprovisionada con la inferencia sin servidor. La inferencia sin servidor con simultaneidad aprovisionada es una opción rentable cuando tiene ráfagas predecibles en su tráfico. La simultaneidad aprovisionada le permite implementar modelos en puntos finales sin servidor con un rendimiento predecible y una alta escalabilidad, ya que mantiene sus puntos de enlace calientes. SageMaker La IA garantiza que, con el número de simultaneidad aprovisionada que asigne, los recursos informáticos se inicialicen y estén listos para responder en cuestión de milisegundos. En el caso de la inferencia sin servidor con simultaneidad aprovisionada, usted paga por la capacidad informática utilizada para procesar las solicitudes de inferencia, facturada por milisegundos, y por la cantidad de datos procesados. También paga por el uso de la simultaneidad aprovisionada, en función de la memoria configurada, la duración aprovisionada y la cantidad de simultaneidad habilitada. Para obtener más información sobre los precios de Serverless Inference with Provisioned Concurrency, consulte Amazon Pricing. SageMaker
Puede integrar la inferencia sin servidor con sus canalizaciones de MLOps para agilizar su flujo de trabajo de machine learning, y puede utilizar un punto de conexión sin servidor para alojar un modelo registrado en el modelo de registro.
La inferencia sin servidor generalmente está disponible en 21 AWS regiones: EE. UU. Este (Norte de Virginia), EE. UU. Este (Ohio), EE. UU. Oeste (Norte de California), EE. UU. Oeste (Oregón), África (Ciudad del Cabo), Asia Pacífico (Hong Kong), Asia Pacífico (Bombay), Asia Pacífico (Tokio), Asia Pacífico (Seúl), Asia Pacífico (Osaka), Asia Pacífico (Singapur), Asia Pacífico (Sídney), Canadá (Central), Europa (Frankfurt), Europa (Irlanda), Europa (Londres), Europa (París), Europa (Estocolmo), Europa (Milán), Oriente Medio (Baréin), Sudamérica (São Paulo). Para obtener más información sobre la disponibilidad regional de Amazon SageMaker AI, consulte la Lista de servicios AWS regionales
Funcionamiento
El siguiente diagrama muestra el flujo de trabajo de la inferencia sin servidor bajo demanda y las ventajas de utilizar un punto de conexión sin servidor.
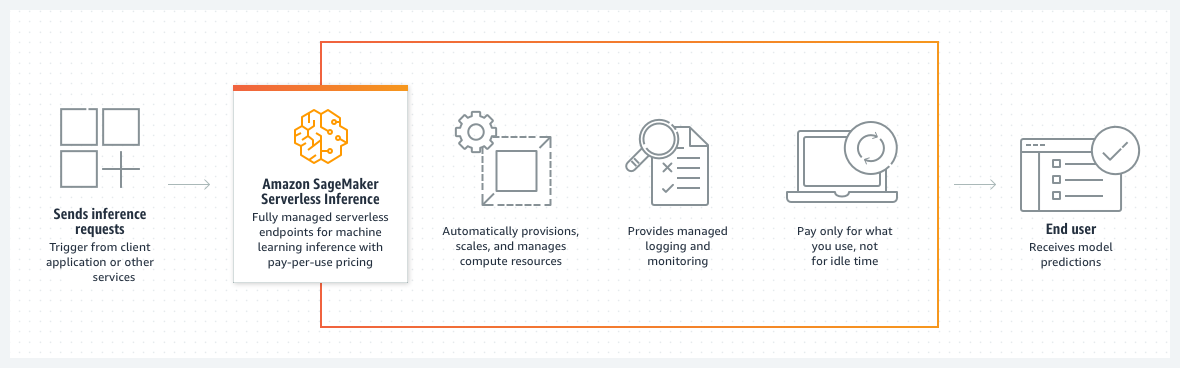
Cuando crea un punto final sin servidor bajo demanda, la SageMaker IA aprovisiona y administra los recursos informáticos por usted. Luego, puede realizar solicitudes de inferencia al punto final y recibir predicciones del modelo en respuesta. SageMaker La IA amplía y reduce los recursos informáticos según sea necesario para gestionar el tráfico de solicitudes, y usted solo paga por lo que utilice.
En el caso de la simultaneidad aprovisionada, la inferencia sin servidor también se integra con Application Auto Scaling, de modo que puede gestionar la simultaneidad aprovisionada en función de una métrica objetiva o de una programación. Para obtener más información, consulte Escalar automáticamente la simultaneidad aprovisionada para un punto de conexión sin servidor.
Las siguientes secciones proporcionan detalles adicionales sobre la inferencia sin servidor y su funcionamiento.
Temas
Compatibilidad con contenedor
Para su contenedor de punto final, puede elegir un SageMaker AI-provided contenedor o traer el suyo propio. SageMaker La IA proporciona contenedores para sus algoritmos integrados e imágenes de Docker prediseñadas para algunos de los marcos de aprendizaje automático más comunes, como Apache MXNet, TensorFlow, PyTorch y Chainer. Para ver una lista de las SageMaker imágenes disponibles, consulte Imágenes disponibles de Deep Learning Containers
El tamaño máximo de la imagen del contenedor que puede utilizar es de 10 GB. Para los puntos de conexión sin servidor, se recomienda crear solo un elemento de trabajo en el contenedor y cargar solo una copia del modelo. Tenga en cuenta que esto es diferente a los puntos de conexión en tiempo real, donde algunos contenedores de SageMaker IA pueden crear un trabajador para cada vCPU a fin de procesar las solicitudes de inferencia y cargar el modelo en cada trabajador.
Si ya dispone de un contenedor para un punto de conexión en tiempo real, puede usar el mismo contenedor para su punto de conexión sin servidor, aunque se excluyen algunas funciones. Para obtener más información sobre las capacidades de los contenedores que no se admiten en inferencia sin servidor, consulte Exclusiones de características. Si eliges usar el mismo contenedor, la SageMaker IA guarda en custodia (conserva) una copia de la imagen del contenedor hasta que elimines todos los puntos finales que usan la imagen. SageMaker La IA cifra la imagen copiada en reposo con una clave. SageMaker AI-owned AWS KMS
Tamaño de memoria
Su punto de conexión sin servidor tiene un tamaño de RAM mínimo de 1024 MB (1 GB) y el tamaño máximo de RAM que puede elegir es de 6144 MB (6 GB). Los tamaños de memoria que puede elegir son 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB o 6144 MB. La inferencia sin servidor asigna automáticamente los recursos de procesamiento proporcionales a la memoria que seleccione. Si elige un tamaño de memoria mayor, su contenedor tendrá acceso a más vCPU. Seleccione el tamaño de memoria de su punto de conexión de acuerdo con el tamaño de su modelo. Por lo general, el tamaño de la memoria debe ser al menos tan grande como el tamaño del modelo. Es posible que deba realizar una evaluación comparativa para elegir la memoria adecuada para su modelo en función de sus SLA de latencia. Para obtener una guía paso a paso sobre la evaluación comparativa, consulte Presentación del kit de herramientas de evaluación comparativa de inferencias de Amazon SageMaker Serverless
Independientemente del tamaño de memoria que elija, su punto de conexión sin servidor dispone de 5 GB de almacenamiento en disco efímero. Para obtener ayuda con los problemas de permisos de los contenedores al trabajar con el almacenamiento, consulte Resolución de problemas.
Invocaciones simultáneas
On-demand Serverless Inference administra políticas y cuotas de escalado predefinidas para la capacidad de su terminal. Los puntos de conexión sin servidor tienen una cuota del número de invocaciones simultáneas que pueden procesarse al mismo tiempo. Si se invoca el punto de conexión antes de que termine de procesar la primera solicitud, gestionará la segunda solicitud de forma simultánea.
La simultaneidad total que puede compartir entre todos los puntos de conexión sin servidor de su cuenta depende de su región:
-
Para las regiones de Este de EE. UU. (Ohio), el Este de EE. UU. (Norte de Virginia), el Oeste de EE. UU. (Oregón), Asia Pacífico (Singapur), Asia Pacífico (Sídney), Asia Pacífico (Tokio), Europa (Fráncfort) y Europa (Irlanda), la simultaneidad total que puede compartir entre todos los puntos de conexión sin servidor por región en su cuenta es 1000.
-
Para las regiones de Oeste de EE. UU. (Norte de California), África (Ciudad del Cabo), Asia Pacífico (Hong Kong), Asia Pacífico (Mumbai), Asia Pacífico (Osaka), Asia Pacífico (Seúl), Canadá (Central), Europa (Londres), Europa (Milán), Europa (París), Europa (Estocolmo), Medio Oriente (Bahréin) y América del Sur (São Paulo), la simultaneidad total por región en su cuenta es de 500.
Puede establecer la simultaneidad máxima para un solo punto de conexión hasta 200, y el número total de puntos de conexión sin servidor que puede alojar en una región es de 50. La simultaneidad máxima de un punto de conexión individual impide que ese punto de conexión acepte todas las invocaciones permitidas para su cuenta, y cualquier invocación de punto de conexión que supere el máximo queda limitada.
nota
La simultaneidad aprovisionada que asigne a un punto de conexión sin servidor siempre debe ser inferior o igual a la simultaneidad máxima que haya asignado a ese punto de conexión.
Para obtener información acerca de cómo configurar la simultaneidad máxima para su punto de conexión, consulte Creación de una configuración de punto de conexión. Para obtener más información sobre las cuotas y los límites, consulte los puntos de enlace y las cuotas de Amazon SageMaker AI en. Referencia general de AWS Para solicitar un aumento del límite de servicio, consulte Soporte de AWS
Minimización del arranque en frío
Si el punto de conexión de inferencia sin servidor bajo demanda no recibe tráfico durante un tiempo y, de repente, el punto de conexión recibe nuevas solicitudes, el punto de conexión puede tardar algún tiempo en activar los recursos informáticos necesarios para procesarlas. Esto se denomina arranque en frío. Dado que los puntos de conexión sin servidor suministran recursos informáticos a pedido, es posible que su punto de conexión sufra interrupciones. También se puede producir un arranque en frío si las solicitudes simultáneas superan el uso actual de solicitudes simultáneas. El tiempo de arranque en frío depende del tamaño del modelo, del tiempo que lleve descargarlo y del tiempo de puesta en marcha del contenedor.
Para controlar cuánto dura el tiempo de arranque en frío, puedes usar la CloudWatch métrica de Amazon OverheadLatency para monitorear tu punto final sin servidor. Esta métrica registra el tiempo que se tarda en lanzar nuevos recursos informáticos para su punto de conexión. Para obtener más información sobre el uso de CloudWatch métricas con puntos de enlace sin servidor, consulte. Alarmas y registros para realizar un seguimiento de las métricas de los puntos de conexión sin servidor
Puede minimizar los arranques en frío mediante la simultaneidad aprovisionada. SageMaker La IA mantiene el punto final caliente y preparado para responder en milisegundos, según el número de simultaneidad aprovisionada que hayas asignado.
Exclusiones de características
Algunas de las funciones disponibles actualmente para la inferencia de SageMaker IA no son compatibles con Real-time la inferencia sin servidor, incluidas las GPU, los paquetes de modelos de AWS mercado, los registros privados de Docker, los Multi-Model puntos finales, la configuración de VPC, el aislamiento de la red, la captura de datos, las múltiples variantes de producción, el monitor de modelos y los canales de inferencia.
No puede convertir un punto de conexión en tiempo real y basado en instancias en un punto de conexión sin servidor. Si intenta actualizar su punto de conexión en tiempo real a uno sin servidor, recibirá un mensaje ValidationError. Puede convertir un punto de conexión sin servidor en un punto de conexión en tiempo real, pero una vez realizada la actualización, no podrá revertirlo a un punto de conexión sin servidor.
Introducción
Puede crear, actualizar, describir y eliminar un punto final sin servidor mediante la consola de SageMaker IA, los AWS SDK, el SDK de Amazon SageMaker Python
nota
Actualmente, no se admite Application Auto Scaling para la inferencia aprovisionada no se admite actualmente en AWS CloudFormation.
Ejemplos de cuadernos y blogs
Para ver ejemplos de cuadernos de Jupyter que muestran flujos de trabajo integrales de puntos de conexión sin servidor, consulte los cuadernos de ejemplo de inferencia sin servidor
