Configuración de un trabajo de entrenamiento con un clúster heterogéneo en Amazon SageMaker
En esta sección se proporcionan instrucciones sobre cómo ejecutar un trabajo de entrenamiento con un clúster heterogéneo que consta de varios tipos de instancias.
Antes de empezar, tenga en cuenta lo siguiente:
-
Todos los grupos de instancias comparten la misma imagen de Docker y el mismo script de entrenamiento. Por lo tanto, debe modificar su script de entrenamiento para detectar a qué grupo de instancias pertenece y bifurcar la ejecución en consecuencia.
-
La característica de clúster heterogéneo no es compatible con el modo local de SageMaker.
-
Los flujos de registro de Amazon CloudWatch de un trabajo de entrenamiento en clústeres heterogéneos no se agrupan por grupos de instancias. Tiene que averiguar a partir de los registros qué nodos están en cada grupo.
Opción 1: uso de SageMaker Python SDK
Siga las instrucciones sobre cómo configurar grupos de instancias para un clúster heterogéneo mediante el SDK de Python de SageMaker.
-
Para configurar grupos de instancias de un clúster heterogéneo para un trabajo de entrenamiento, utilice la clase
sagemaker.instance_group.InstanceGroup. Puede especificar un nombre personalizado para cada grupo de instancias, el tipo de instancia y la cantidad de instancias para cada grupo de instancias. Para obtener más información, consulte Sagemaker.instance_group.instanceGroupen la documentación del SDK de Python de SageMaker. nota
Para obtener más información sobre los tipos de instancias disponibles y el número máximo de grupos de instancias que puede configurar en un clúster heterogéneo, consulte la referencia de la API InstanceGroup.
En el siguiente ejemplo de código, se muestra cómo configurar dos grupos de instancias que constan de dos instancias
ml.c5.18xlargeque solo utilizan CPU denominadasinstance_group_1y una instancia de GPU deml.p3dn.24xlargedenominadainstance_group_2, tal y como se muestra en el siguiente diagrama.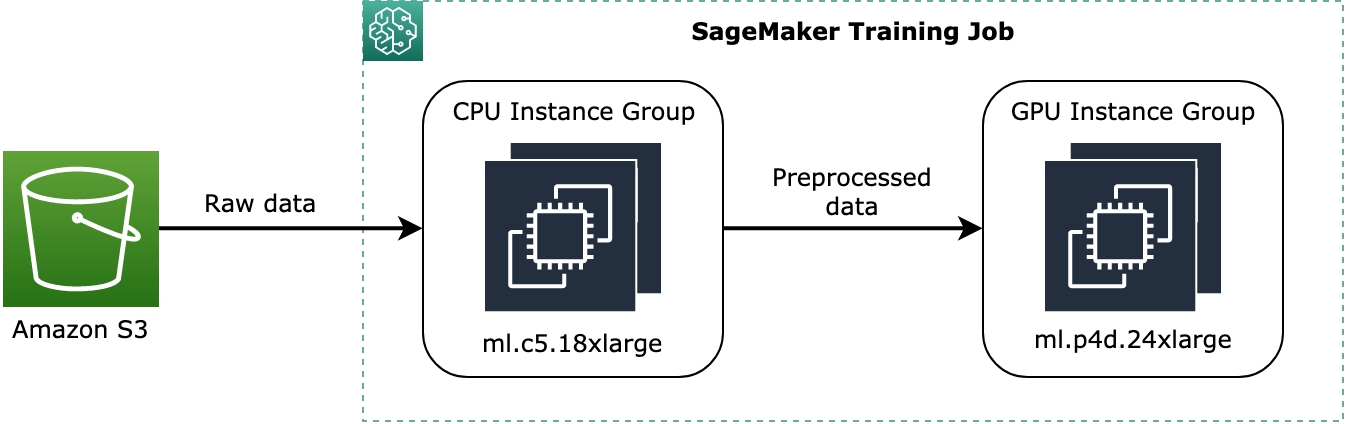
El diagrama anterior muestra un ejemplo conceptual de cómo los procesos previos al entrenamiento, como el preprocesamiento de datos, se pueden asignar al grupo de instancias de la CPU y transmitir los datos preprocesados al grupo de instancias de la GPU.
from sagemaker.instance_group import InstanceGroup instance_group_1 = InstanceGroup( "instance_group_1", "ml.c5.18xlarge",2) instance_group_2 = InstanceGroup( "instance_group_2", "ml.p3dn.24xlarge",1) -
Con los objetos del grupo de instancias, configure los canales de entrada de entrenamiento y asigne grupos de instancias a los canales mediante el argumento
instance_group_namesde la clase SageMaker.Inputs.TrainingInput. El argumento instance_group_namesacepta una lista de cadenas de nombres de grupos de instancias.En el siguiente ejemplo, se muestra cómo configurar dos canales de entrada de entrenamiento y cómo asignar los grupos de instancias creados en el ejemplo del paso anterior. También puedes especificar las rutas de los buckets de Amazon S3 al argumento
s3_datapara que los grupos de instancias procesen los datos para sus fines de uso.from sagemaker.inputs import TrainingInput training_input_channel_1 = TrainingInput( s3_data_type='S3Prefix', # Available Options: S3Prefix | ManifestFile | AugmentedManifestFile s3_data='s3://your-training-data-storage/folder1', distribution='FullyReplicated', # Available Options: FullyReplicated | ShardedByS3Key input_mode='File', # Available Options: File | Pipe | FastFile instance_groups=["instance_group_1"] ) training_input_channel_2 = TrainingInput( s3_data_type='S3Prefix', s3_data='s3://your-training-data-storage/folder2', distribution='FullyReplicated', input_mode='File', instance_groups=["instance_group_2"] )Para obtener más información sobre los argumentos de
TrainingInput, consulte los siguientes enlaces.-
La clase sagemaker.inputs.TrainingInput
de la documentación del SDK de Python de SageMaker -
La API S3DataSource en la Referencia de la API de Sagemaker
-
-
Configure un estimador de SageMaker con el argumento
instance_groups, tal y como se muestra en el siguiente ejemplo de código. El argumentoinstance_groupsacepta una lista de objetosInstanceGroupnota
La característica de clúster heterogéneo está disponible a través de las clases de estimadores de marco de PyTorch
y TensorFlow de SageMaker. Los marcos compatibles son PyTorch v1.10 o posterior y TensorFlow v2.6 o posterior. Para encontrar una lista completa de los contenedores de marco, las versiones de marco y las versiones de Python disponibles, consulte SageMaker Framework Containers en el repositorio de GitHub de contenedores de aprendizaje profundo AWS. nota
El par de argumentos
instance_typeyinstance_county el argumentoinstance_groupsde la clase de estimadores de SageMaker se excluyen mutuamente. Para el entrenamiento de clústeres homogéneos, utilice el par de argumentosinstance_typeyinstance_count. Para el entrenamiento de clústeres heterogéneos, utiliceinstance_groups.nota
Para encontrar una lista completa de los contenedores de marco, las versiones de marco y las versiones de Python disponibles, consulte SageMaker Framework Containers
en el repositorio de GitHub de contenedores de aprendizaje profundo AWS. -
Configure el método
estimator.fitcon los canales de entrada de entrenamiento configurados con los grupos de instancias e inicie el trabajo de entrenamiento.estimator.fit( inputs={ 'training':training_input_channel_1, 'dummy-input-channel':training_input_channel_2} )
Opción 2: uso de las API de SageMaker de bajo nivel
Si utiliza la AWS Command Line Interface o el AWS SDK for Python (Boto3) y quiere utilizar las API de SageMaker de bajo nivel para enviar una solicitud de trabajo de entrenamiento con un clúster heterogéneo, consulte las siguientes referencias de API.
