Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso del estado Map en modo distribuido para cargas de trabajo paralelas a gran escala en Step Functions
Administración del estado y transformación de los datos
Obtenga información sobre la Transmisión de datos entre estados con variables y la Transformación de datos con JSONata.
Con Step Functions, puede orquestar cargas de trabajo paralelas a gran escala para realizar tareas, como el procesamiento bajo demanda de datos semiestructurados. Estas cargas de trabajo paralelas permiten procesar simultáneamente orígenes de datos a gran escala almacenados en Amazon S3. Por ejemplo, puede procesar un único archivo JSON o CSV que contenga grandes cantidades de datos. O bien, puede procesar un conjunto grande de objetos de Amazon S3.
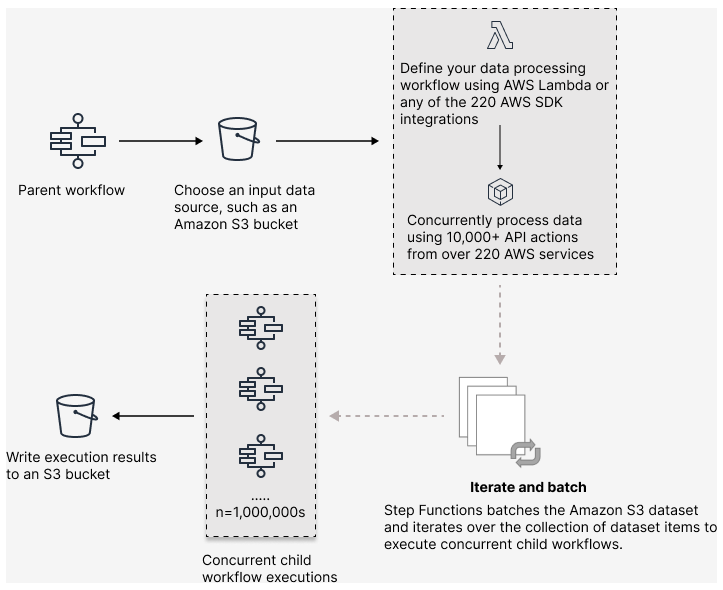
Para configurar una carga de trabajo paralela a gran escala en los flujos de trabajo, incluya un estado Map en modo distribuido. El estado Map procesa los elementos de un conjunto de datos de forma simultánea. Un estado Map establecido en Distributed se conoce como estado Map Distributed. En el modo Distribuido, el estado Map permite un procesamiento de alta simultaneidad. En el modo Distribuido, el estado Map procesa los elementos del conjunto de datos en iteraciones llamadas ejecuciones de flujos de trabajo secundarios. Puede especificar el número de ejecuciones de flujo de trabajo secundario que se pueden ejecutar en paralelo. Cada ejecución de flujo de trabajo secundario tiene su propio historial de ejecución independiente del flujo de trabajo principal. Si no se especifica, Step Functions ejecuta 10 000 ejecuciones de flujos de trabajo secundarios en paralelo.
La siguiente ilustración explica cómo puede configurar cargas de trabajo paralelas a gran escala en los flujos de trabajo.
Obtenga más información en el taller
Descubra cómo las tecnologías sin servidor, como Step Functions y Lambda, pueden simplificar la administración y el escalado, reducir la carga de tareas indiferenciadas y abordar los desafíos del procesamiento de datos distribuido a gran escala. A lo largo del camino, trabajará con mapas distribuidos para un procesamiento de alta simultaneidad. El taller también presenta las prácticas recomendadas para optimizar sus flujos de trabajo y casos de uso prácticos para el procesamiento de reclamaciones, el escaneo de vulnerabilidades y la simulación de Monte Carlo.
Taller: Procesamiento Large-scale de datos con Step Functions
En este tema
Términos clave
- Modo distribuido
-
Un modo de procesamiento del estado Map. En este modo, cada iteración del estado
Mapse ejecuta como una ejecución de flujo de trabajo secundario que permite una alta simultaneidad. Cada ejecución de flujo de trabajo secundario tiene su propio historial de ejecución, independiente del historial de ejecución del flujo de trabajo principal. Este modo admite la lectura de orígenes de datos de Amazon S3 a gran escala. - Estado Map Distributed
-
Un estado de Map establecido en modo de procesamiento distribuido.
- Flujo de trabajo de Map
Un conjunto de pasos que ejecuta un estado
Map.- Flujo de trabajo principal
-
Un flujo de trabajo que contiene uno o más estados Map Distributed.
- Ejecución de flujo de trabajo secundario
-
Una iteración del estado Map Distributed. La ejecución de un flujo de trabajo secundario tiene su propio historial de ejecución, que es independiente del historial de ejecución del flujo de trabajo principal.
- Map Run
-
Cuando se ejecuta un estado
Mapen modo distribuido, Step Functions crea un recurso Map Run. Map Run hace referencia a un conjunto de ejecuciones de flujos de trabajo secundarios que inicia un estado Map Distributed y a la configuración de tiempo de ejecución que controla estas ejecuciones. Step Functions asigna un nombre de recurso de Amazon (ARN) al Map Run. Puede examinar un Map Run en la consola de Step Functions. También puede invocar la acción de la APIDescribeMapRun.Las ejecuciones secundarias del flujo de trabajo de un Map Run emiten métricas a CloudWatch;. Estas métricas tendrán un ARN de máquina de estado etiquetado con el siguiente formato:
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUIDPara obtener más información, consulte Visualización de ejecuciones de Map.
Ejemplo de definición de estado Distributed Map (JSONPath)
Utilice el estado Map en modo Distribuido cuando necesite orquestar cargas de trabajo paralelas a gran escala que cumplan cualquier combinación de las siguientes condiciones:
El tamaño del conjunto de datos supera los 256 KiB.
El historial de eventos de ejecución del flujo de trabajo superaría las 25 000 entradas.
Necesita una simultaneidad de más de 40 iteraciones simultáneas.
En el siguiente ejemplo de definición de estado Map Distributed, se especifica el conjunto de datos como un archivo CSV almacenado en un bucket de Amazon S3. También especifica una función de Lambda que procesa los datos de cada fila del archivo CSV. Como en este ejemplo se utiliza un archivo CSV, también se especifica la ubicación de los encabezados de las columnas CSV. Para ver la definición completa de la máquina de estado de este ejemplo, consulte el tutorial Copia de datos CSV a gran escala mediante Map Distributed.
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}Permisos para ejecutar Map Distributed
Cuando se incluye un estado Map Distributed en los flujos de trabajo, Step Functions necesita los permisos adecuados para permitir que el rol de la máquina de estado invoque la acción de la API StartExecution para el estado Map Distributed.
El siguiente ejemplo de política de IAM otorga los privilegios mínimos necesarios al rol de la máquina de estado para ejecutar el estado Map Distributed.
nota
No olvide reemplazar stateMachineNamearn:aws:states:.region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
Además, debe asegurarse de tener los privilegios mínimos necesarios para acceder a los AWS recursos utilizados en el estado del mapa distribuido, como los buckets de Amazon S3. Para obtener información, consulte Políticas de IAM para usar estados Map Distributed.
Campos de estado de Map Distributed
Para usar el estado Map Distributed en los flujos de trabajo, especifique uno o más de estos campos. Estos campos se especifican además de los campos de estado comunes.
Type(Obligatorio)-
Establece el tipo de estado, por ejemplo
Map. ItemProcessor(Obligatorio)-
Contiene los siguientes objetos JSON que especifican el modo y la definición de procesamiento del estado
Map.-
ProcessorConfig: objeto JSON que especifica el modo de procesamiento de los elementos, con los siguientes subcampos:-
Mode: configurado enDISTRIBUTEDpara usar el estadoMapen modo distribuido.aviso
El modo distribuido se admite en los flujos de trabajo estándar, pero no en los flujos de trabajo rápidos.
-
ExecutionType– Especifica el tipo de ejecución del flujo de trabajo de Map como STANDARD o EXPRESS. Debe proporcionar este campo si especificóDISTRIBUTEDpara el subcampoMode. Para obtener más información acerca de los tipos de flujo de trabajo, consulte Elegir el tipo de flujo de trabajo en Step Functions.
-
StartAt: especifica una cadena que indica el primer estado de un flujo de trabajo. Esta cadena debe coincidir exactamente (mayúsculas y minúsculas) con el nombre de uno de los objetos de estado. Este estado se ejecuta primero para cada elemento del conjunto de datos. Cualquier entrada de ejecución que se proporcione al estadoMappasará primero al estadoStartAt.States– Objeto JSON que contiene un conjunto de estados delimitados por comas. En este objeto, se define el Map workflow.
-
ItemReader-
Especifica un conjunto de datos y su ubicación. El estado
Maprecibe sus datos de entrada del conjunto de datos especificado.En el modo distribuido, puede utilizar como conjunto de datos una carga JSON transferida desde un estado anterior o un origen de datos de Amazon S3 a gran escala. Para obtener más información, consulte ItemReader (Mapa).
Items(Opcional, solo JSONata)-
Una matriz JSON, un objeto JSON o una expresión JSonata que debe dar como resultado una matriz u objeto.
ItemsPath(Opcional, solo JSONPath)-
Especifica una ruta de referencia mediante la JsonPath
sintaxis para seleccionar el nodo JSON que contiene una matriz de elementos o un objeto con pares clave-valor dentro de la entrada de estado. En el modo distribuido, solo se especifica este campo cuando se utiliza una matriz o un objeto JSON de un paso anterior como entrada de estado. Para obtener más información, consulte ItemsPath ( JSONPath Solo mapa).
ItemSelector(Opcional, solo JSONPath)-
Anula los valores de los elementos individuales del conjunto de datos antes de pasarlos a cada iteración del estado
Map.En este campo, se especifica una entrada JSON válida que contiene un conjunto de pares clave-valor. Estos pares pueden ser valores estáticos que se establezcan en la definición de la máquina de estado, valores seleccionados de la entrada de estado mediante una ruta o valores a los que se accede desde el objeto de contexto. Para obtener más información, consulte ItemSelector (Map).
ItemBatcher(opcional)-
Especifica el procesamiento de los elementos del conjunto de datos por lotes. Cada ejecución de flujo de trabajo secundario recibe entonces un lote de estos elementos como entrada. Para obtener más información, consulte ItemBatcher (Map).
MaxConcurrency(opcional)-
Especifica el número de ejecuciones de flujo de trabajo secundario que se pueden ejecutar en paralelo. El intérprete solo permite el número especificado de ejecuciones de flujos de trabajo secundarios paralelos. Si no se especifica un valor de simultaneidad o se establece en cero, Step Functions no limita la simultaneidad y realiza 10 000 ejecuciones paralelas de flujos de trabajo secundarios. En los estados de JSONata, puede especificar una expresión de JSONata que se evalúe como un número entero.
nota
Si bien puede especificar un límite de simultaneidad superior para las ejecuciones de flujos de trabajo secundarios en paralelo, le recomendamos que no exceda la capacidad de un AWS servicio descendente, como. AWS Lambda
MaxConcurrencyPath(Opcional, solo JSONPath)-
Si desea proporcionar un valor máximo de simultaneidad de forma dinámica a partir de la entrada de estado mediante una ruta de referencia, utilice
MaxConcurrencyPath. Una vez resuelta, la ruta de referencia debe seleccionar un campo cuyo valor sea un entero no negativo.nota
Un estado
Mapno puede incluir tantoMaxConcurrencycomoMaxConcurrencyPath. ToleratedFailurePercentage(opcional)-
Define el porcentaje de elementos con error que se toleran en un Map Run. El Map Run genera automáticamente un error si se supera este porcentaje. Step Functions calcula el porcentaje de elementos con error como resultado del número total de elementos con error o con tiempo de espera agotado dividido por el número total de elementos. Debe especificar un valor comprendido entre cero y 100. Para obtener más información, consulte Establecimiento de umbrales de error para los estados de los mapas distribuidos en Step Functions.
En los estados de JSONata, puede especificar una expresión de JSONata que se evalúe como un número entero.
ToleratedFailurePercentagePath(Opcional, solo JSONPath)-
Si desea proporcionar un valor de porcentaje de error tolerado de forma dinámica a partir de la entrada de estado con una ruta de referencia, utilice
ToleratedFailurePercentagePath. Una vez resuelta, la ruta de referencia debe seleccionar un campo cuyo valor esté entre cero y 100. ToleratedFailureCount(opcional)-
Define el número de elementos con error que se toleran en un Map Run. El Map Run genera automáticamente un error si se supera este porcentaje. Para obtener más información, consulte Establecimiento de umbrales de error para los estados de los mapas distribuidos en Step Functions.
En los estados de JSONata, puede especificar una expresión de JSONata que se evalúe como un número entero.
ToleratedFailureCountPath(Opcional, solo JSONPath)-
Si desea proporcionar un valor de recuento de error tolerado de forma dinámica a partir de la entrada de estado con una ruta de referencia, utilice
ToleratedFailureCountPath. Una vez resuelta, la ruta de referencia debe seleccionar un campo cuyo valor sea un entero no negativo. Label(opcional)-
Una cadena que identifica de forma exclusiva un estado
Map. Para cada Map Run, Step Functions añade la etiqueta al ARN de Map Run. A continuación se muestra un ejemplo de un ARN de Map Run con una etiqueta personalizada denominadademoLabel:arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0bSi no especifica una etiqueta, Step Functions genera automáticamente una etiqueta única.
nota
Las etiquetas no pueden tener más de 40 caracteres de longitud, deben ser únicas dentro de una definición de máquina de estado y no pueden contener ninguno de los siguientes caracteres:
-
Espacios en blanco
-
Caracteres comodín (
? *) -
Caracteres entre corchetes (
< > { } [ ]) -
Caracteres especiales (
: ; , \ | ^ ~ $ # % & ` ") -
Caracteres de control (
\\u0000-\\u001fo\\u007f-\\u009f).
Step Functions acepta nombres para máquinas de estado, ejecuciones, actividades y etiquetas que contengan caracteres no ASCII. Dado que estos caracteres impedirán que Amazon registre CloudWatch datos, te recomendamos que utilices únicamente caracteres ASCII para poder realizar un seguimiento de las métricas de Step Functions.
-
ResultWriter(opcional)-
Especifica la ubicación de Amazon S3 en la que Step Functions escribe todos los resultados de ejecución de flujo de trabajo secundario.
Step Functions consolida todos los datos de ejecución del flujo de trabajo secundario, como la entrada y salida de la ejecución, el ARN y el estado de ejecución. A continuación, exporta las ejecuciones con el mismo estado a sus archivos respectivos en la ubicación de Amazon S3 especificada. Para obtener más información, consulte ResultWriter (Mapa).
Si no se exportan los resultados del estado
Map, devolverá una matriz con todos los resultados de la ejecución del flujo de trabajo secundario. Por ejemplo:[1, 2, 3, 4, 5] ResultPath(Opcional, solo JSONPath)-
Especifica en qué lugar de la entrada se va a situar la salida de las iteraciones. La entrada se filtra entonces según el contenido del campo OutputPath, si está presente, antes de que se pase como salida del estado. Para obtener más información, consulte Procesamiento de entrada y salida.
ResultSelector(opcional)-
Pase un conjunto de pares clave-valor, donde los valores sean estáticos o se seleccionen del resultado. Para obtener más información, consulte ResultSelector.
sugerencia
Si el estado Parallel o Map que utiliza en sus máquinas de estado devuelve una matriz de matrices, puede transformarlas en una matriz plana con el campo ResultSelector. Para obtener más información, consulte Aplanamiento de una matriz de matrices.
Retry(opcional)-
Una matriz de objetos, denominados "reintentadores", que definen una política de reintentos. Una ejecución utiliza la política de reintento si el estado encuentra errores en tiempo de ejecución. Para obtener más información, consulte Ejemplos de máquina de estado que usan Retry y Catch.
nota
Si define "reintentadores" para el estado Map Distributed, la política de reintentos se aplica a todas las ejecuciones de flujo de trabajo secundario que haya iniciado el estado
Map. Por ejemplo, imagine que el estadoMapha iniciado tres ejecuciones de flujos de trabajo secundarios, de las cuales una genera un error. Cuando se produce el error, la ejecución utiliza el campoRetry, si está definido, para el estadoMap. La política de reintentos se aplica a todas las ejecuciones del flujo de trabajo secundario y no solo a las ejecuciones con error. Si se produce un error en la ejecución de uno o más flujos de trabajo secundarios, se produce un error en el Map Run.Al reintentar un estado
Map, se crea un nuevo Map Run. Catch(opcional)-
Una matriz de objetos, denominados "receptores", que definen un estado alternativo. Step Functions usa los "receptores" definidos en
Catchsi el estado encuentra errores en tiempo de ejecución. Cuando se produce un error, la ejecución utiliza primero los "reintentadores" definidos enRetry. Si la política de reintentos no está definida o está agotada, la ejecución utiliza sus "receptores", si están definidos. Para obtener más información, consulte Estados alternativos. Output(Opcional, solo JSONata)-
Se utiliza para especificar y transformar la salida del estado. Cuando se especifica, el valor anula el valor predeterminado de salida del estado.
El campo de salida acepta cualquier valor JSON (objeto, matriz, cadena, número, booleano, nulo). Cualquier valor de cadena, incluidos los que estén dentro de objetos o matrices, se evaluará como JSONata si está rodeado por caracteres {% %}.
La salida también acepta directamente una expresión de JSONata, por ejemplo: “Output”: “{% jsonata expression%}”
Para obtener más información, consulte Transformación de datos con JSONata en Step Functions.
-
Assign(opcional) -
Se utiliza para almacenar variables. El
Assigncampo acepta un objeto JSON con key/value pares que definen los nombres de las variables y sus valores asignados. Cualquier valor de cadena, incluidos los que estén dentro de objetos o matrices, se evaluará como JSONata si está rodeado por caracteres{% %}.Para obtener más información, consulte Transmisión de datos entre estados con variables.
Establecimiento de umbrales de error para los estados de los mapas distribuidos en Step Functions
Al orquestar cargas de trabajo paralelas a gran escala, también puede definir un umbral de error tolerado. Este valor permite especificar el número máximo o el porcentaje de elementos con error como umbral de error para Map Run. Según el valor que especifique, su Map Run generará un error automáticamente si supera el umbral. Si especifica ambos valores, el flujo de trabajo genera un error cuando supera alguno de los valores.
La especificación de un umbral contribuye a que se produzca un error en un número específico de elementos antes de que lo haga en toda la Map Run. Step Functions devuelve un error States.ExceedToleratedFailureThreshold cuando la Map Run genera un error porque se ha superado el umbral especificado.
nota
Step Functions puede seguir ejecutando flujos de trabajo secundarios en una Map Run incluso después de superar el umbral de error tolerado, pero antes de que la Map Run genere un error.
Para especificar el valor de umbral en Workflow Studio, seleccione Definir un umbral de error tolerado en Configuración adicional en el campo Configuración del tiempo de ejecución.
- Porcentaje de errores tolerados
-
Define el porcentaje de elementos con error que se van a tolerar. Su Map Run genera un error si se supera este valor. Step Functions calcula el porcentaje de elementos con error como resultado del número total de elementos con error o con tiempo de espera agotado dividido por el número total de elementos. Debe especificar un valor comprendido entre cero y 100. El valor porcentual predeterminado es cero, lo que significa que el flujo de trabajo genera un error si alguna de las ejecuciones de flujos de trabajo secundarios produce un error o se agota el tiempo de espera. Si especifica el porcentaje en 100, el flujo de trabajo no dará error aunque se produzcan errores en todas las ejecuciones de los flujos de trabajos secundarios.
Además, puede especificar el porcentaje como ruta de referencia a un par clave-valor existente en la entrada del estado Distributed Map. Esta ruta debe convertirse en un entero positivo entre 0 y 100 en tiempo de ejecución. La ruta de referencia se especifica en el subcampo
ToleratedFailurePercentagePath.Por ejemplo, en el caso de la entrada siguiente:
{"percentage":15}Puede especificar el porcentaje mediante una ruta de referencia a esa entrada de la siguiente manera:
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }importante
Puede especificar
ToleratedFailurePercentageoToleratedFailurePercentagePath, pero no los dos, en la definición del estado Map Distributed. - Recuento de errores tolerados
-
Define el número de elementos con error que se van a tolerar. Su Map Run genera un error si se supera este valor.
Además, puede especificar el recuento como ruta de referencia a un par clave-valor existente en la entrada del estado Distributed Map. Esta ruta debe convertirse en un número entero positivo en tiempo de ejecución. La ruta de referencia se especifica en el subcampo
ToleratedFailureCountPath.Por ejemplo, en el caso de la entrada siguiente:
{"count":10}Puede especificar el número mediante una ruta de referencia a esa entrada de la siguiente manera:
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }importante
Puede especificar
ToleratedFailureCountoToleratedFailureCountPath, pero no los dos, en la definición del estado Distributed Map.
Más información sobre los mapas Distribuidos
Para obtener más información acerca del estado Map Distributed, consulte los siguientes recursos:
-
Procesamiento de entrada y salida
Para configurar la entrada que recibe un estado Map Distributed y la salida que genera, Step Functions proporciona los siguientes campos:
Además de estos campos, Step Functions también permite definir un umbral de error tolerado para Map Distributed. Este valor permite especificar el número máximo o el porcentaje de elementos con error como umbral de error para Map Run. Para obtener más información acerca de la configuración del umbral de error tolerado, consulte Establecimiento de umbrales de error para los estados de los mapas distribuidos en Step Functions.
-
Uso del estado Map Distributed
Consulte los siguientes tutoriales y proyectos de muestra para empezar a utilizar el estado Map Distributed.
-
Procesamiento de datos de lotes con una función de Lambda en Step Functions
-
Procesamiento de elementos individuales con una función de Lambda en Step Functions
-
Proyecto de ejemplo: procesar un archivo CSV con Map Distributed
-
Proyecto de ejemplo: procesar datos de un bucket de Amazon S3 con Map Distributed
-
Examen de la ejecución del estado Map Distributed
La consola de Step Functions proporciona una página Detalles de Map Run que muestra toda la información relacionada con la ejecución de un estado Map Distributed. Para obtener información sobre cómo examinar la información que se muestra en esta página, consulte Visualización de ejecuciones de Map.
