Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cola de trabajos
Al utilizar la cola de trabajos, puede enviar más solicitudes de trabajos de transcripción de las que se pueden procesar simultáneamente. Sin colas de trabajos, una vez que alcance el límite de solicitudes simultáneas permitidas, debe esperar a que se completen una o más solicitudes antes de enviar una nueva solicitud.
La cola de trabajos es opcional para ambas solicitudes de trabajos de transcripción y trabajos de análisis posteriores a la llamada.
Si habilita la cola de trabajos, Amazon Transcribe crea una cola que contenga todas las solicitudes que superen su límite. En cuanto se complete una solicitud, se extraerá una nueva de la lista y se procesará. Las solicitudes en la cola se procesan siguiendo el orden primero en entrar, primero en salir (FIFO).
Puede tener hasta 10 000 trabajos en cola. Si supera este límite, se produce un error LimitExceededConcurrentJobException. Para mantener un rendimiento óptimo, Amazon Transcribe solo utiliza hasta el 90 por ciento de su cuota (una relación de ancho de banda de 0,9) para procesar los trabajos en cola. Tenga en cuenta que estos son valores predeterminados que se pueden aumentar previa solicitud.
sugerencia
Puede encontrar una lista de límites y cuotas predeterminados para Amazon Transcribe los recursos en la Referencia AWS general. Algunos de estos valores predeterminados se pueden aumentar previa solicitud.
Si habilita la cola de trabajos pero no supera la cuota de solicitudes simultáneas, todas las solicitudes se procesarán simultáneamente.
Habilitar la cola de trabajos
Puede habilitar la puesta en cola de trabajos mediante Consola de administración de AWS, AWS CLI o los SDK de AWS ; consulte los siguientes ejemplos:
-
Inicie sesión en la Consola de administración de AWS
. -
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
-
En el cuadro Ajustes del trabajo, hay un panel Ajustes adicionales. Si expande este panel, puede seleccionar la casilla Añadir a la cola de trabajos para activar la cola de trabajos.
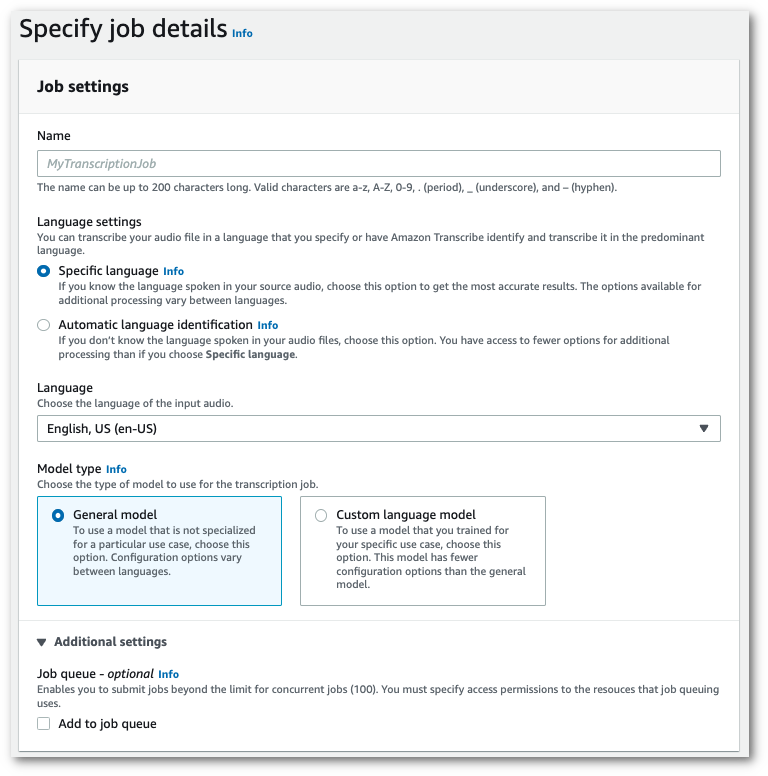
-
Rellene todos los campos que desee incluir en la página Especificar los detalles del trabajo y, a continuación, seleccione Siguiente. Esto lo llevará a la página Configurar trabajo: opcional.
-
Seleccione Crear trabajo para ejecutar su trabajo de transcripción.
En este ejemplo, se utilizan el comando start-transcription-jobjob-execution-settings con el subparámetro AllowDeferredExecution. Tenga en cuenta que cuando incluya AllowDeferredExecution en su solicitud, también debe incluir DataAccessRoleArn.
Para obtener más información, consulte StartTranscriptionJob y JobExecutionSettings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --job-execution-settings AllowDeferredExecution=true,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole
A continuación, se muestra otro ejemplo en el que se utiliza el comando start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-queueing-request.json
El archivo my-first-queueing-request.json contiene el siguiente cuerpo de la solicitud.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "JobExecutionSettings": { "AllowDeferredExecution": true, "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" } }
En este ejemplo, se utiliza AWS SDK para Python (Boto3) para habilitar la puesta en cola de trabajos mediante el AllowDeferredExecution argumento del método start_transcription_job.AllowDeferredExecution en su solicitud, también debe incluir DataAccessRoleArn. Para obtener más información, consulte StartTranscriptionJob y JobExecutionSettings.
Para ver ejemplos adicionales sobre el uso de los AWS SDK, incluidos ejemplos de funciones específicas, escenarios y servicios cruzados, consulte el capítulo. Ejemplos de código para Amazon Transcribe usando AWS SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-queueing-request" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', JobExecutionSettings = { 'AllowDeferredExecution': True, 'DataAccessRoleArn': 'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Puede ver el progreso de un trabajo en cola a través de Consola de administración de AWS o enviando una solicitud. GetTranscriptionJob Cuando un trabajo está en cola, el Status es QUEUED. El estado cambia a IN_PROGRESS una vez que el trabajo comienza a procesarse, luego cambia a COMPLETED o FAILED al finalizar el procesamiento.
