Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Utilice pasos predefinidos
Al crear un flujo de trabajo, puede optar por añadir uno de los siguientes pasos predefinidos que se describen en este tema. También puede optar por agregar sus propios pasos de procesamiento de archivos personalizados. Para obtener más información, consulte Uso de pasos de procesamiento de archivos personalizados.
Temas
Copiar archivo
El paso de copiar archivo crea una copia del archivo cargado en una nueva ubicación de Amazon S3. Actualmente, solo puede utilizar el paso de copiar archivos con Amazon S3.
En el siguiente paso de copiar archivos, se copian los archivos en la test carpeta de. amzn-s3-demo-destination-bucket
Si el paso de copiar el archivo no es el primer paso del flujo de trabajo, puede especificar la ubicación del archivo. Al especificar la ubicación del archivo, puede copiar el archivo que se utilizó en el paso anterior o el archivo original que se cargó. Puede utilizar esta característica para realizar varias copias del archivo original y, al mismo tiempo, mantener intacto el archivo de origen para archivarlos y conservar los registros. Para ver un ejemplo, consulta Ejemplo de flujo de trabajo de etiquetado y eliminación.

Proporcione el bucket y los detalles de la clave
Debe proporcionar el nombre del bucket y una clave para el destino del paso de copiar el archivo. La clave puede ser un nombre de ruta o un nombre de archivo. El hecho de que la clave se trate como un nombre de ruta o como un nombre de archivo depende de si termina la clave con la barra inclinada (/).
Si el último carácter es /, el archivo se copia en la carpeta, y su nombre no cambia. Si el último carácter es alfanumérico, se cambiará el nombre del archivo cargado al valor clave. En este caso, si ya existe un archivo con ese nombre, el comportamiento depende de la configuración del campo Sobrescribir existente.
-
Si se selecciona Sobrescribir existente, el archivo existente se reemplaza por el archivo que se está procesando.
-
Si no se selecciona Sobrescribir existente, no ocurre nada, y el procesamiento del flujo de trabajo se detiene.
sugerencia
Si se ejecutan escrituras simultáneas en la misma ruta de archivo, es posible que se produzca un comportamiento inesperado al sobrescribir los archivos.
Por ejemplo, si el valor de la clave es test/, los archivos cargados se copian en la carpeta test. Si el valor de la clave es test/today (y la opción Sobrescribir existente está seleccionada), todos los archivos que cargue se copiarán en un archivo llamado today en la carpeta test y cada archivo posterior sobrescribirá al anterior.
nota
Amazon S3 admite buckets y objetos y no existe jerarquía. Sin embargo, puede usar prefijos y delimitadores en los nombres de las claves de los objetos para establecer una jerarquía y organizar sus datos de forma similar a las carpetas.
Utilizar una variable con nombre en el paso de copiar un archivo
En el paso de copiar un archivo, puede utilizar una variable para copiar, dinámicamente, los archivos en carpetas específicas del usuario. Actualmente, puede usar ${transfer:UserName} o ${transfer:UploadDate} como una variable para copiar archivos a una ubicación de destino para el usuario en concreto que carga los archivos o según la fecha actual.
En el siguiente ejemplo, si el usuario richard-roe carga un archivo, se copia en la carpeta amzn-s3-demo-destination-bucket/richard-roe/processed/. En el siguiente ejemplo, si el usuario mary-major carga un archivo, queda copiado en la carpeta amzn-s3-demo-destination-bucket/mary-major/processed/.

Del mismo modo, se puede utilizar ${transfer:UploadDate} como variable para copiar los archivos a una ubicación de destino con el nombre de la fecha actual. En el siguiente ejemplo, si establece el destino ${transfer:UploadDate}/processed en el 1 de febrero de 2022, los archivos cargados se copiarán en la carpeta amzn-s3-demo-destination-bucket/2022-02-01/processed/.

También puede utilizar estas dos variables juntas al combinar sus funciones. Por ejemplo, puede establecer el prefijo de la clave de destino enfolder/${transfer:UserName}/${transfer:UploadDate}/, lo que crearía carpetas anidadas, por ejemplo. folder/marymajor/2023-01-05/
Permisos de IAM para el paso de copiado
Para permitir que un paso de copiado se realice correctamente, asegúrese de que el rol de ejecución de su flujo de trabajo contenga los siguientes permisos.
{ "Sid": "ListBucket", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": [ "arn:aws:s3:::amzn-s3-demo-destination-bucket" ] }, { "Sid": "HomeDirObjectAccess", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObjectVersion", "s3:DeleteObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::amzn-s3-demo-destination-bucket/*" }
nota
El permiso s3:ListBucket solo es necesario si no selecciona Sobrescribir existente. Este permiso comprueba el bucket para verificar si ya existe un archivo con el mismo nombre. Si ha seleccionado Sobrescribir existente, el flujo de trabajo no necesita comprobar el archivo y puede escribirlo sin más.
Si sus archivos de Amazon S3 tienen etiquetas, debe añadir uno o dos permisos a su política de IAM.
-
Añada
s3:GetObjectTaggingpara un archivo de Amazon S3 que no tenga versiones. -
Añada
s3:GetObjectVersionTaggingpara un archivo de Amazon S3 que tenga versiones.
Descifrar el archivo
El blog sobre AWS almacenamiento tiene una entrada que describe cómo descifrar archivos de forma sencilla sin escribir ningún código mediante los flujos de trabajo gestionados por Transfer Family, cifrar y descifrar archivos con PGP
Algoritmos de cifrado simétrico compatibles
Para el descifrado PGP, Transfer Family admite algoritmos de cifrado simétrico que se utilizan para cifrar los datos reales de los archivos dentro de los archivos PGP.
-
Para obtener información detallada sobre los algoritmos de cifrado simétrico compatibles, consulte. Algoritmos de cifrado simétrico PGP
-
Para obtener información sobre los algoritmos de key pair de PGP que se utilizan con estos algoritmos simétricos, consulte. Algoritmos de key pair PGP
Utilizar el descifrado PGP en su flujo de trabajo
Transfer Family cuenta con compatibilidad integrada para el descifrado Pretty Good Privacy (PGP). Puede utilizar el descifrado PGP en los archivos que se carguen mediante SFTP, FTPS o FTP a Amazon Simple Storage Service (Amazon S3) o Amazon Elastic File System (Amazon EFS).
Para utilizar el descifrado PGP, debe crear y almacenar las claves privadas de PGP que se utilizarán para descifrar sus archivos. Por ello, los usuarios pueden cifrar los archivos mediante las claves de cifrado PGP correspondientes antes de cargarlos en el servidor de Transfer Family. Después de recibir los archivos cifrados, puede descifrarlos en su flujo de trabajo. Para ver un tutorial detallado, consulte Configuración de un flujo de trabajo gestionado para descifrar un archivo.
Para obtener información sobre los algoritmos y recomendaciones de PGP compatibles, consulte. Algoritmos de cifrado y descifrado PGP
Uso del descifrado PGP en su flujo de trabajo
-
Identifique un servidor de Transfer Family para alojar su flujo de trabajo o cree uno nuevo. Debe tener el ID del servidor antes de poder almacenar sus claves PGP en AWS Secrets Manager con el nombre secreto correcto.
-
Guarde su clave PGP AWS Secrets Manager con el nombre secreto requerido. Para obtener más información, consulte Administración de claves PGP. Los flujos de trabajo pueden localizar, automáticamente, la clave PGP correcta que se utilizará para el descifrado en función del nombre secreto en Secrets Manager.
nota
Cuando guardas secretos en Secrets Manager, Cuenta de AWS incurres en cargos. Para obtener más información acerca de los precios, consulte AWS Secrets Manager Precios
. -
Cifre un archivo con su par de claves PGP. (Si desea obtener una lista de los clientes compatibles, consulte Clientes PGP admitidos.) Si está utilizando la línea de comando, utilice el siguiente comando. Para usar este comando, reemplace
username@example.comtestfile.txtgpg -e -rusername@example.comtestfile.txtimportante
Al cifrar archivos para usarlos con AWS Transfer Family flujos de trabajo, asegúrese siempre de especificar un destinatario no anónimo mediante el parámetro.
-rEl cifrado anónimo (sin especificar un destinatario) puede provocar errores de descifrado en el flujo de trabajo, ya que el sistema no podrá identificar qué clave utilizar para el descifrado. La información sobre la depuración de este problema está disponible en. Solucione problemas de cifrado de destinatarios anónimos -
Suba el archivo cifrado a su servidor de Transfer Family.
-
Configure un paso de descifrado en su flujo de trabajo. Para obtener más información, consulte Añada un paso de descifrado.
Añada un paso de descifrado
Un paso de descifrado descifra un archivo cifrado que se cargó en Amazon S3 o Amazon EFS como parte de su flujo de trabajo. Para obtener información detallada sobre la configuración del cifrado, consulte Utilizar el descifrado PGP en su flujo de trabajo.
Al crear el paso de descifrado para un flujo de trabajo, debe especificar el destino de los archivos descifrados. También debe seleccionar si desea sobrescribir los archivos existentes si ya existe un archivo en la ubicación de destino. Puede supervisar los resultados del flujo de trabajo de descifrado y obtener los registros de auditoría de cada archivo en tiempo real mediante Amazon CloudWatch Logs.
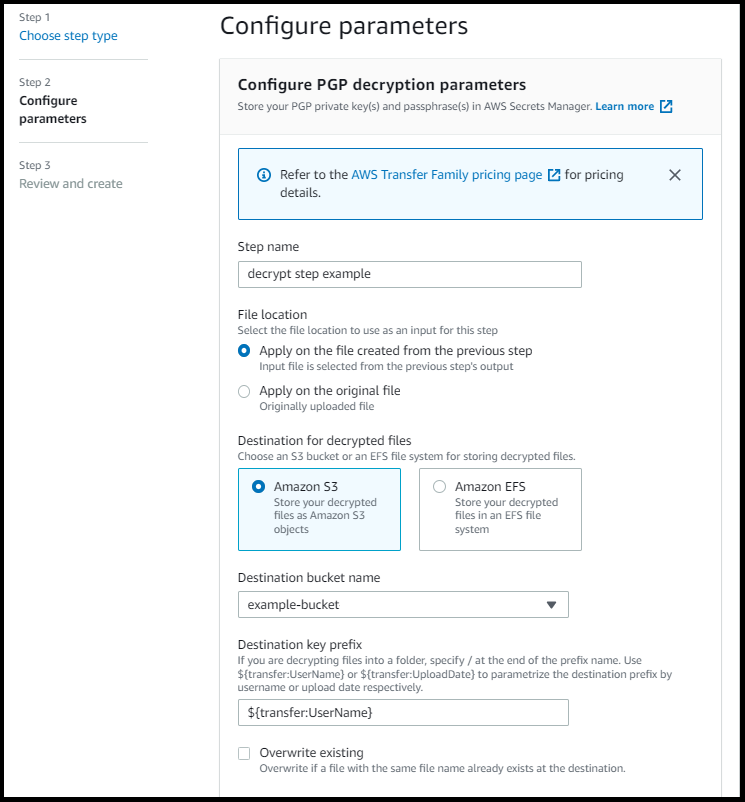
Tras elegir el tipo de archivo de descifrado para el paso, aparecerá la página de configuración de parámetros. Complete los valores de la sección Configuración de parámetros de descifrado de PGP.
Las opciones disponibles son las siguientes:
-
Nombre del paso: escriba un nombre descriptivo para el paso.
-
Ubicación del archivo: al especificar la ubicación del archivo, puede cifrar el archivo utilizado en el paso anterior o el archivo original que se cargó.
nota
Este parámetro no está disponible si este paso es el primero del flujo de trabajo.
-
Destino de los archivos descifrados: elija un bucket de Amazon S3 o un sistema de archivos Amazon EFS como destino del archivo descifrado.
-
Si elige Amazon S3, debe proporcionar un nombre de bucket de destino y un prefijo de clave. Para establecer los parámetros del prefijo de la clave de destino por nombre de usuario, introduzca
${transfer:UserName}como el prefijo de la clave de destino. De igual manera, para establecer los parámetros del prefijo de la clave de destino por fecha de carga, introduzca${Transfer:UploadDate}para el prefijo de la clave de destino. -
Si elige Amazon EFS, debe proporcionar una ruta y un sistema de archivos de destino.
nota
La opción de almacenamiento que elija aquí debe coincidir con el sistema de almacenamiento que utilice el servidor de Transfer Family al que está asociado este flujo de trabajo. De lo contrario, se producirá un error al intentar ejecutar este flujo de trabajo.
-
-
Sobrescribir existente: si carga un archivo y ya existe un archivo con el mismo nombre de archivo en el destino, el comportamiento depende de la configuración de este parámetro:
-
Si se selecciona Sobrescribir existente, el archivo existente se reemplaza por el archivo que se está procesando.
-
Si no se selecciona Sobrescribir existente, no ocurre nada, y el procesamiento del flujo de trabajo se detiene.
sugerencia
Si se ejecutan escrituras simultáneas en la misma ruta de archivo, es posible que se produzca un comportamiento inesperado al sobrescribir los archivos.
-
La siguiente captura de pantalla muestra un ejemplo de las opciones que puede elegir para el paso de descifrado del archivo.
Permisos de IAM para el paso de cifrado
Para permitir que un paso de descifrado se realice correctamente, asegúrese de que el rol de ejecución de su flujo de trabajo contenga los siguientes permisos.
{ "Sid": "ListBucket", "Effect": "Allow", "Action": "s3:ListBucket", "Resource": [ "arn:aws:s3:::amzn-s3-demo-destination-bucket" ] }, { "Sid": "HomeDirObjectAccess", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObjectVersion", "s3:DeleteObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::amzn-s3-demo-destination-bucket/*" }, { "Sid": "Decrypt", "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue", ], "Resource": "arn:aws:secretsmanager:region:account-id:secret:aws/transfer/*" }
nota
El permiso s3:ListBucket solo es necesario si no selecciona Sobrescribir existente. Este permiso comprueba el bucket para verificar si ya existe un archivo con el mismo nombre. Si ha seleccionado Sobrescribir existente, el flujo de trabajo no necesita comprobar el archivo y puede escribirlo sin más.
Si sus archivos de Amazon S3 tienen etiquetas, debe añadir uno o dos permisos a su política de IAM.
-
Añada
s3:GetObjectTaggingpara un archivo de Amazon S3 que no tenga versiones. -
Añada
s3:GetObjectVersionTaggingpara un archivo de Amazon S3 que tenga versiones.
Etiquetado de archivos
Para etiquetar los archivos entrantes para su posterior procesamiento, utilice un paso de etiquetado. Introduzca el valor de la etiqueta que desea asignar a los archivos entrantes. Actualmente, la operación de etiquetado solo se admite si utiliza Amazon S3 para el almacenamiento de su servidor de Transfer Family.
El siguiente ejemplo de paso de etiquetado asigna scan_outcome y clean como la clave y el valor de la etiqueta respectivamente.

Para permitir que un paso de etiquetado se realice correctamente, asegúrese de que el rol de ejecución de su flujo de trabajo contenga los siguientes permisos.
{ "Sid": "Tag", "Effect": "Allow", "Action": [ "s3:PutObjectTagging", "s3:PutObjectVersionTagging" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/*" ] }
nota
Si su flujo de trabajo contiene un paso de etiquetado que se ejecuta antes de un paso de copiado o descifrado, debe añadir uno o dos permisos a su política de IAM.
-
Añada
s3:GetObjectTaggingpara un archivo de Amazon S3 que no tenga versiones. -
Añada
s3:GetObjectVersionTaggingpara un archivo de Amazon S3 que tenga versiones.
Eliminar archivo
Para eliminar un archivo procesado de un paso anterior del flujo de trabajo o para eliminar el archivo cargado originalmente, utilice un paso de eliminación de archivo.

Para permitir que un paso de eliminación se realice correctamente, asegúrese de que el rol de ejecución de su flujo de trabajo contenga los siguientes permisos.
{ "Sid": "Delete", "Effect": "Allow", "Action": [ "s3:DeleteObjectVersion", "s3:DeleteObject" ], "Resource": "arn:aws:secretsmanager:region:account-ID:secret:aws/transfer/*" }
Variables con nombre para los flujos de trabajo
Para los pasos de copiado y descifrado, puede utilizar una variable para realizar acciones de forma dinámica. Actualmente, AWS Transfer Family admite las siguientes variables con nombre.
-
Se utiliza
${transfer:UserName}para copiar o descifrar archivos a un destino en función del usuario que los carga. -
Se utiliza
${transfer:UploadDate}para copiar o descifrar archivos a una ubicación de destino en función de la fecha actual.
Ejemplo de flujo de trabajo de etiquetado y eliminación
El siguiente ejemplo ilustra un flujo de trabajo que etiqueta los archivos entrantes que deben ser procesados por una aplicación secundaria, como una plataforma de análisis de datos. Tras etiquetar el archivo entrante, el flujo de trabajo elimina el archivo cargado originalmente para ahorrar costos de almacenamiento.

