REL09-BP04 Recuperación periódica de los datos para verificar la integridad de la copia de seguridad y los procesos
Valide que su implementación del proceso de copia de seguridad cumpla con los objetivos de tiempo de recuperación (RTO) y los objetivos de punto de recuperación (RPO) mediante una prueba de recuperación.
Resultado deseado: los datos de las copias de seguridad se recuperan periódicamente mediante mecanismos bien definidos para verificar que la recuperación sea posible dentro del objetivo de tiempo de recuperación (RTO) establecido para la carga de trabajo. Verifique que la restauración a partir de una copia de seguridad dé como resultado un recurso que contenga los datos originales sin que ninguno de ellos resulte dañado o inaccesible, y una pérdida de datos coherente con el objetivo de punto de recuperación (RPO).
Patrones comunes de uso no recomendados:
-
Restaurar una copia de seguridad, pero no consultar ni recuperar ningún dato para comprobar que la restauración sea posible.
-
Suponer que existe una copia de seguridad.
-
Suponer que la copia de seguridad de un sistema está plenamente operativa y que es posible recuperar datos de ella.
-
Suponer que el tiempo de restauración o recuperación de datos de una copia de seguridad entra dentro del RTO para la carga de trabajo.
-
Suponer que los datos que contiene la copia de seguridad están dentro del RPO para la carga de trabajo
-
Restaurar cuando sea necesario, sin usar un manual de procedimientos, o fuera de un procedimiento automatizado.
Beneficios de establecer esta práctica recomendada: al probar la recuperación de las copias de seguridad, se comprueba que los datos se pueden restaurar cuando sea necesario sin preocuparse de que falten datos o estén dañados, de que la restauración y la recuperación sean posibles dentro del RTO de la carga de trabajo y que cualquier pérdida de datos recaiga dentro del RPO correspondiente a la carga de trabajo.
Nivel de riesgo expuesto si no se establece esta práctica recomendada: medio
Guía para la implementación
La comprobación de la capacidad de copia de seguridad y restauración aumenta la confianza en la capacidad de llevar a cabo estas acciones durante una interrupción. Restaure periódicamente las copias de seguridad en una nueva ubicación y lleve a cabo pruebas para verificar la integridad de los datos. Algunas de las pruebas habituales que deberían efectuarse consisten en comprobar que todos los datos estén disponibles, no estén dañados, sean accesibles y si la pérdida de datos (si la hay) se ajusta al RPO de la carga de trabajo. Estas pruebas también pueden ayudar a determinar si los mecanismos de recuperación son lo suficientemente rápidos como para tener capacidad para el RTO de la carga de trabajo.
Con AWS, puede crear un entorno de pruebas y restaurar sus copias de seguridad para evaluar las capacidades en cuanto al RTO y al RPO y llevar a cabo pruebas sobre el contenido y la integridad de los datos.
Además, Amazon RDS y Amazon DynamoDB permiten la recuperación en un momento dado (PITR). Mediante la copia de seguridad continua, puede restaurar su conjunto de datos al estado en el que se encontraba en una fecha y hora específicas.
Si todos los datos están disponibles, no están dañados, son accesibles y la pérdida de datos (si la hay) se ajusta al RPO de la carga de trabajo. Estas pruebas también pueden ayudar a determinar si los mecanismos de recuperación son lo suficientemente rápidos como para tener capacidad para el RTO de la carga de trabajo.
AWS Elastic Disaster Recovery ofrece instantáneas de recuperación en un momento dado continuas de volúmenes de Amazon EBS. A medida que se replican los servidores de origen, los estados de un momento dado se cronifican en el tiempo en función de la política configurada. La Recuperación de desastres elástica ayuda a verificar la integridad de estas instantáneas mediante el lanzamiento de instancias con fines de prueba y simulacro sin redirigir el tráfico.
Pasos para la implementación
-
Identifique los orígenes de datos de los que se están haciendo copias de seguridad actualmente y dónde se almacenan dichas copias de seguridad. Para obtener una guía para la implementación, consulte REL09-BP01 Identificación de todos los datos de los que se debe hacer una copia de seguridad, creación de la copia de seguridad o reproducción de los datos a partir de los orígenes.
-
Establezca los criterios de validación de datos para cada origen de datos. Los diferentes tipos de datos tendrán distintas propiedades, lo que podría requerir diferentes mecanismos de validación. Considere cómo se podrían validar estos datos antes de contar con la confianza suficiente para usarlos en producción. Algunas formas habituales de validar los datos son usar las propiedades de datos y copias de seguridad como el tipo de datos, el formato, la suma de comprobación, el tamaño o una combinación de ellas con lógica de validación personalizada. Por ejemplo, podría tratarse de una comparación de los valores de las sumas de comprobación entre el recurso restaurado y el origen de datos en el momento en que se creó la copia de seguridad.
-
Establezca el RTO y el RPO para restaurar los datos según su importancia. Para obtener una guía para la implementación, consulte REL13-BP01 Definición de objetivos de recuperación para el tiempo de inactividad y la pérdida de datos.
-
Evalúe su capacidad de recuperación. Revise su estrategia de copia de seguridad y restauración para comprender si se ajusta a su RTO y RPO y ajuste la estrategia según sea necesario. Con AWS Resilience Hub, puede evaluar la carga de trabajo. La evaluación compara la configuración de su aplicación con la política de resiliencia y notifica si se pueden cumplir los objetivos de RTO y RPO.
-
Ejecute una restauración de prueba con los procesos actualmente establecidos que se utilizan en la producción para la restauración de datos. Estos procesos dependen de cómo se haya creado la copia de seguridad del origen de datos, el formato y la ubicación del almacenamiento de la copia de seguridad, o de si los datos se reproducen desde otros orígenes. Por ejemplo, si utiliza un servicio administrado, como AWS Backup, podría ser tan sencillo como restaurar la copia de seguridad en un nuevo recurso. Si usó AWS Elastic Disaster Recovery, puede iniciar un simulacro de recuperación.
-
Valide la recuperación de datos del recurso restaurado en función de los criterios que estableció previamente para la validación de los datos. ¿Los datos restaurados y recuperados contienen el registro o elemento más reciente en el momento de la copia de seguridad? ¿Estos datos se ajustan al RPO de la carga de trabajo?
-
Calcule el tiempo necesario para la restauración y la recuperación y compárelo con el RTO establecido. ¿Este proceso se ajusta al RTO de la carga de trabajo? Por ejemplo, compare las marcas de tiempo del momento en que se inició el proceso de restauración y de cuando se completó la validación de la recuperación para calcular cuánto tarda este proceso. Todas las llamadas a la API de AWS llevan una marca de tiempo y esta información está disponible en AWS CloudTrail. Aunque esta información puede proporcionar detalles sobre cuándo se inició el proceso de restauración, la marca de tiempo final del momento en que finalizó la validación debería quedar registrada mediante su lógica de validación. Si se utiliza un proceso automatizado, se pueden utilizar servicios como Amazon DynamoDB
para almacenar esta información. Además, muchos servicios de AWS proporcionan un historial de eventos que facilita información con marcas de tiempo cuando ocurren determinadas acciones. En AWS Backup, las acciones de copia de seguridad y restauración se denominan trabajos, y estos trabajos contienen información sobre la marca de tiempo como parte de sus metadatos, que se puede utilizar para medir el tiempo necesario para la restauración y la recuperación. -
Notifique a las partes interesadas si se produce un error en la validación de los datos o si el tiempo necesario para la restauración y la recuperación supera el RTO establecido para la carga de trabajo. Al implementar la automatización para que lo haga, como en este laboratorio
, se pueden utilizar servicios como Amazon Simple Notification Service (Amazon SNS) para enviar notificaciones push, como correos electrónicos o SMS, a las partes interesadas. Estos mensajes también se pueden publicar en aplicaciones de mensajería como Amazon Chime, Slack o Microsoft Teams , o se pueden usar para crear tareas como OpsItems con el Centro de operaciones de AWS Systems Manager. -
Automatice este proceso para que se ejecute periódicamente. Por ejemplo, se pueden usar servicios como AWS Lambda o una máquina de estados en AWS Step Functions para automatizar los procesos de restauración y recuperación, mientras que se puede usar Amazon EventBridge para invocar este flujo de trabajo de automatización periódicamente como se muestra en el siguiente diagrama de arquitectura. Obtenga información sobre cómo automatizar la validación de recuperación de datos con AWS Backup
. Además, en este laboratorio de Well-Architected se ofrece una experiencia práctica sobre una forma de ejecutar la automatización de varios de los pasos que se describen aquí.
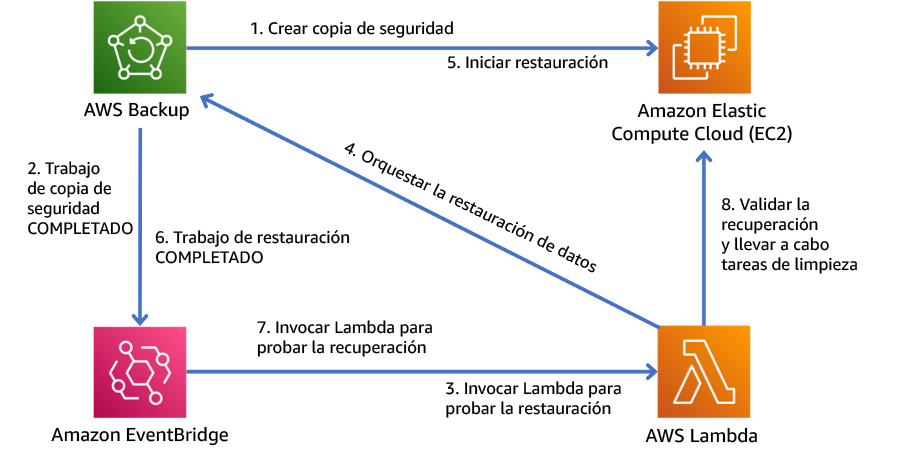
Figura 9. Proceso de copia de seguridad y restauración automatizado
Nivel de esfuerzo para el plan de implementación: de moderado a alto, según la complejidad de los criterios de validación.
Recursos
Documentos relacionados:
Ejemplos relacionados:
