REL13-BP02 Usar estrategias de recuperación definidas para cumplir los objetivos de recuperación
Defina una estrategia de recuperación de desastres (DR) que se ajuste a los objetivos de recuperación de su carga de trabajo. Elija una estrategia como copia de seguridad y restauración, estado de espera (activa/pasiva) o activa/activa.
Resultado deseado: para cada carga de trabajo, existe una estrategia de DR definida e implementada que permite que esa carga de trabajo alcance los objetivos de DR. Las estrategias de DR entre cargas de trabajo emplean patrones reutilizables (como las estrategias descritas anteriormente).
Antipatrones usuales:
-
Implementar procedimientos de recuperación incoherentes para cargas de trabajo con objetivos de DR similares.
-
Dejar la estrategia de DR para implementarla ad hoc cuando se produzca un desastre.
-
No tener un plan de recuperación de desastres.
-
Depender de las operaciones del plano de control durante la recuperación.
Beneficios de establecer esta práctica recomendada:
-
El uso de estrategias de recuperación definidas le permite emplear herramientas y procedimientos de prueba comunes.
-
El uso de estrategias de recuperación definidas mejora el intercambio de conocimiento entre equipos y la implementación de la DR en las cargas de trabajo que se encuentran bajo su responsabilidad.
Nivel de riesgo expuesto si no se establece esta práctica recomendada: alto Sin una estrategia de DR planificada, implementada y probada, es poco probable que consiga sus objetivos de recuperación en caso de desastre.
Guía para la implementación
Una estrategia de DR depende de la capacidad de poner en marcha su carga de trabajo en un sitio de recuperación si su ubicación principal deja de estar disponible para la ejecución de dicha carga de trabajo. Los objetivos de recuperación más comunes son el RTO y el RPO, como explicamos en REL13-BP01 Definir objetivos de recuperación para la inactividad y la pérdida de datos.
Una estrategia de DR en varias zonas de disponibilidad (AZ) dentro de una única Región de AWS puede ofrecer mitigación contra eventos de desastres como incendios, inundaciones y cortes de suministro eléctrico considerables. Si es necesario implementar medidas de protección contra un evento poco probable que evite que su carga de trabajo pueda ejecutarse en una Región de AWS determinada, puede seguir una estrategia de DR que abarque múltiples regiones.
A la hora de diseñar una estrategia de DR en varias regiones, debería elegir una de las siguientes estrategias. Se indican en orden ascendente de coste y complejidad y en orden descendente en cuanto al RTO y RPO. Región de recuperación se refiere a una Región de AWS diferente de la principal que se usa para su carga de trabajo.
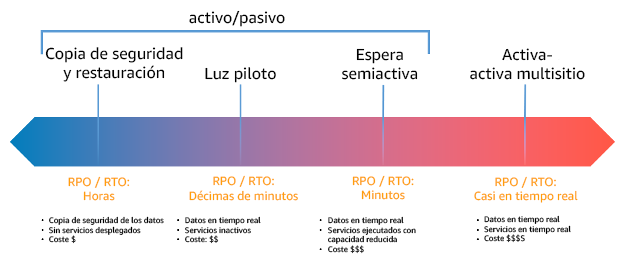
Figura 17: Estrategias de recuperación de desastres (DR)
-
Generación de copias de seguridad y restauración (RPO en horas, RTO en 24 horas o menos): cree una copia de seguridad de sus datos y aplicaciones en la región de recuperación. El uso de copias de seguridad automatizadas o continuas permitirá la recuperación a un momento dado, lo que puede reducir el RPO a hasta 5 minutos en algunos casos. En caso de desastre, desplegará su infraestructura (utilizando la infraestructura como código para reducir el RTO), desplegará su código y restaurará los datos desde la copia de seguridad para recuperarse del desastre en la región de recuperación.
-
Luz piloto (RPO en minutos, RTO en decenas de minutos): aprovisione una copia de la infraestructura principal de su carga de trabajo en la región de recuperación. Replique sus datos en la región de recuperación y cree allí copias de seguridad de estos. Los recursos necesarios para permitir la replicación y copia de seguridad de los datos, como el almacenamiento de bases de datos y objetos, están siempre disponibles. Otros elementos, como los servidores de aplicaciones o la computación sin servidor, no se despliegan, pero pueden crearse cuando sea necesario con la configuración y el código de aplicación pertinentes.
-
Espera semiactiva (RPO en segundos, RTO en minutos): mantenga una versión reducida pero totalmente funcional de su carga de trabajo que se ejecute continuamente en la región de recuperación. Los sistemas críticos se duplican en su totalidad y siempre están activos, pero con una flota reducida. Los datos se replican y están activos en la región de recuperación. Cuando llegue el momento de la recuperación, el sistema se amplía rápidamente para asumir la carga de producción. Cuanto mayor sea la escala de la espera semiactiva, menor será el RTO y la fiabilidad del plano de control. Cuando alcanza su plena escala, la espera pasa a denominarse espera activa.
-
Activa-activa multirregión (multisitio) (RPO próximo a cero, RTO potencial de cero): la carga de trabajo está desplegada en varias Regiones de AWS y entrega tráfico de forma activa desde estas regiones. Esta estrategia requiere que sincronice datos entre regiones. Los posibles conflictos causados por escrituras en el mismo registro en dos diferentes réplicas regionales deben evitarse o gestionarse, lo que puede resultar complejo. La replicación de datos es útil para la sincronización de datos y le protegerá ante algunos tipos de desastres, pero no ante el daño o la destrucción de datos, a no ser que su solución incluya también opciones para una recuperación a un momento dado.
nota
La diferencia entre la luz piloto y la espera semiactiva a veces puede ser difícil de comprender. Ambos métodos incluyen un entorno en su región de recuperación con copias de los activos de su región principal. La distinción es que la luz piloto no puede procesar solicitudes sin tomar primero acciones adicionales, mientras que la espera semiactiva puede gestionar el tráfico (a niveles de capacidad reducidos) inmediatamente. La luz piloto exige que active servidores, posiblemente que despliegue infraestructura adicional (no principal) y que escale verticalmente, mientras que la espera semiactiva solo requiere que escale verticalmente (ya está todo desplegado y en ejecución). Elija una de estas opciones en función de sus necesidades de RTO y RPO.
Cuando el coste sea una preocupación y desee alcanzar unos objetivos de RPO y RTO similares a los definidos en la estrategia de espera semiactiva, podría plantearse soluciones nativas de la nube, como AWS Elastic Disaster Recovery, que adoptan el enfoque de luz piloto y ofrecen objetivos de RPO y RTO mejorados.
Pasos para la implementación
-
Determine una estrategia de DR que satisfaga los requisitos de recuperación de esta carga de trabajo.
La selección de una estrategia de DR requiere alcanzar un punto de equilibrio entre la reducción del tiempo de inactividad y la pérdida de datos (RTO y RPO) y los costes y la complejidad de implementar la estrategia. Debería evitar implementar una estrategia que sea más exigente de lo necesario, ya que esto supone costes innecesarios.
Por ejemplo, en el siguiente diagrama, la empresa ha determinado su RTO máximo permisible y el límite de gasto en su estrategia de restauración del servicio. Dados los objetivos de la empresa, las estrategias de DR de luz piloto o espera semiactiva satisfarán tanto el RTO como los criterios de coste.
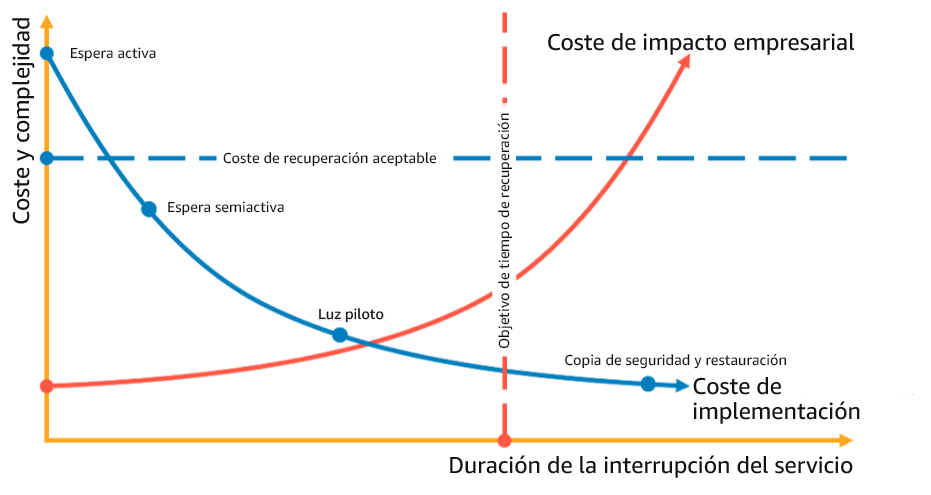
Figura 18: Selección de una estrategia de DR basada en el RTO y el coste
Para obtener más información, consulte Business Continuity Plan (BCP) (Plan de continuidad del negocio [BCP]).
-
Revise los patrones de implementación de la estrategia de DR seleccionada.
Este paso implica comprender cómo implementará la estrategia seleccionada. Las estrategias se explican utilizando Regiones de AWS para determinar un sitio principal y otro de recuperación. Sin embargo, también puede decidir utilizar zonas de disponibilidad en una única región como estrategia de DR, que utiliza los elementos de varias de estas estrategias.
En los siguientes pasos, puede aplicar la estrategia a su carga de trabajo específica.
Generación de copias de seguridad y restauración
Generación de copias de seguridad y restauración es la estrategia menos compleja de implementar, pero requiere más tiempo y esfuerzo para restaurar la carga de trabajo, lo que genera un mayor RTO y RPO. Se recomienda realizar siempre copias de seguridad de los datos y copiarlas en otro sitio (por ejemplo, otra Región de AWS).
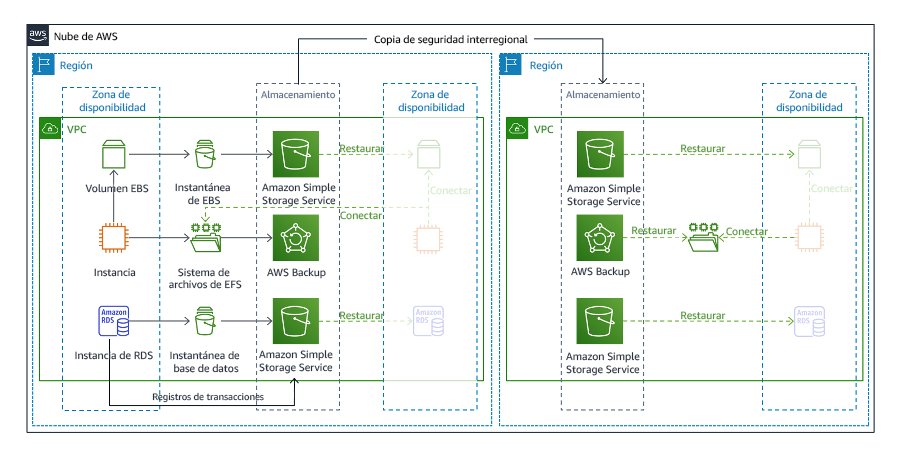
Figura 19: Arquitectura de copia de seguridad y restauración
Para obtener más detalles sobre esta estrategia, consulte Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery
Luz piloto
Con el enfoque luz piloto, replica sus datos de la región principal en la región de recuperación. Los recursos principales utilizados para la infraestructura de la carga de trabajo se despliegan en la región de recuperación; sin embargo, se siguen necesitando recursos adicionales y las dependencias pertinentes para que esta pila sea funcional. Por ejemplo, en la figura 20 no se despliegan instancias de computación.
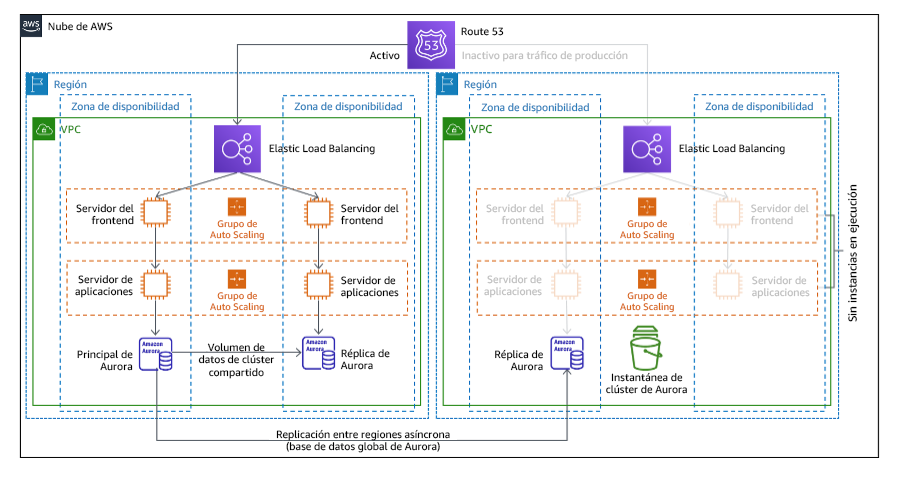
Figura 20: Arquitectura de luz piloto
Para obtener más detalles sobre esta estrategia, consulte Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
Espera semiactiva
El enfoqueespera semiactiva supone garantizar que exista una copia con desescalada vertical pero con plena funcionalidad de su entorno de producción en otra región. Este enfoque extiende el concepto de luz piloto y reduce el tiempo de recuperación, ya que su carga de trabajo tiene disponibilidad permanente en otra región. Si la región de recuperación se despliega a plena capacidad, esto se denomina espera activa.
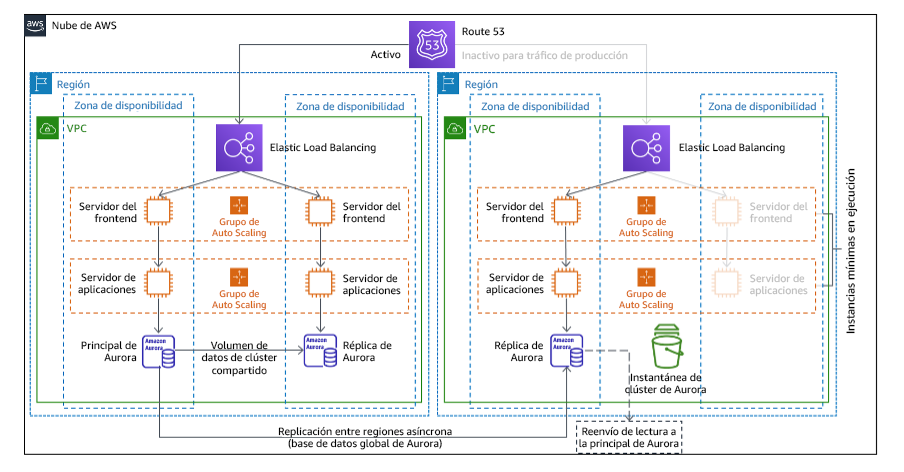
Figura 21: Arquitectura de espera semiactiva
El uso de las estrategias espera semiactiva o luz piloto requiere escalar verticalmente los recursos en la región de recuperación. Para verificar que la capacidad esté disponible cuando se necesita, considere el uso de reservas de capacidad para instancias EC2. Si usa AWS Lambda, entonces la simultaneidad aprovisionada puede proporcionar entornos de ejecución de forma que estén preparados para responder de inmediato a las invocaciones de la función.
Para obtener más detalles sobre esta estrategia, consulte Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
Activa-activa multisitio
Puede ejecutar su carga de trabajo de forma simultánea en varias regiones como parte de una estrategia activa-activa multisitio. La estrategia activa-activa multisitio suministra tráfico desde todas las regiones en las que se despliega. Los clientes podrían seleccionar esta estrategia por motivos ajenos a la DR. Se puede usar para aumentar la disponibilidad o cuando se despliega una carga de trabajo para una audiencia global (para colocar el punto de conexión más cerca de los usuarios o para desplegar pilas localizadas para la audiencia de esa región). Como estrategia de DR, si la carga de trabajo no es compatible en una de las Regiones de AWS en la que esté desplegada, esa región se evacúa y las regiones restantes se usan para mantener la disponibilidad. La estrategia activa-activa multisitio es la más compleja de las estrategias de DR a nivel operativo, y solo debería seleccionarse cuando los requisitos empresariales lo exijan.
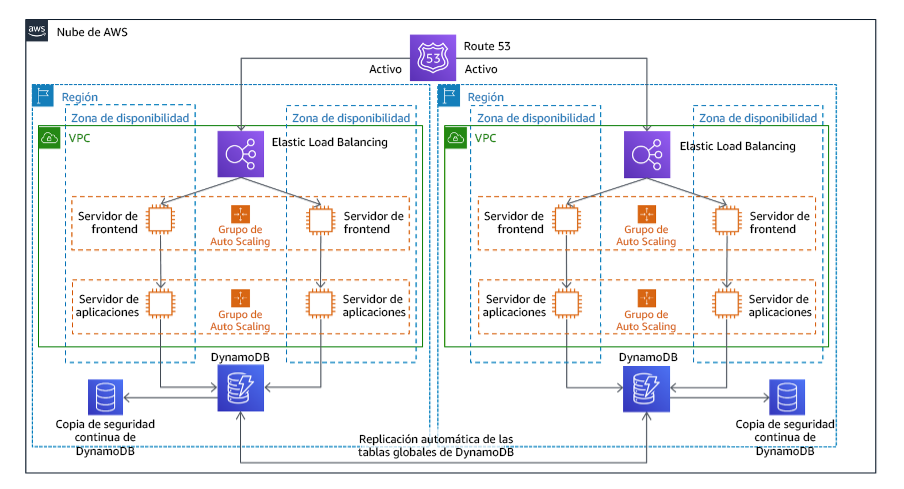
Figura 22: Arquitectura activa-activa multisitio
Para obtener más detalles sobre esta estrategia, consulte Disaster Recovery (DR) Architecture on AWS, Part IV: Multi-site Active/Active
AWS Elastic Disaster Recovery
Si está considerando la estrategia luz piloto o espera semiactiva para la recuperación de desastres, AWS Elastic Disaster Recovery podría ofrecer un enfoque alternativo con mayores ventajas. Elastic Disaster Recovery puede ofrecer un objetivo de RPO y RTO similar al de la estrategia espera semiactiva, pero manteniendo el enfoque de bajo coste de la estrategia luz piloto. Elastic Disaster Recovery replica los datos desde la región primaria a la región de recuperación, utilizando la protección continua de datos para lograr un RPO medido en segundos y un RTO que puede medirse en minutos. En la región de recuperación solo se despliegan los recursos necesarios para replicar los datos, lo que mantiene los costes bajos, de forma similar a la estrategia luz piloto. Cuando se utiliza Elastic Disaster Recovery, el servicio coordina y organiza la recuperación de los recursos de computación cuando se inicia como parte de una conmutación por error o un simulacro.
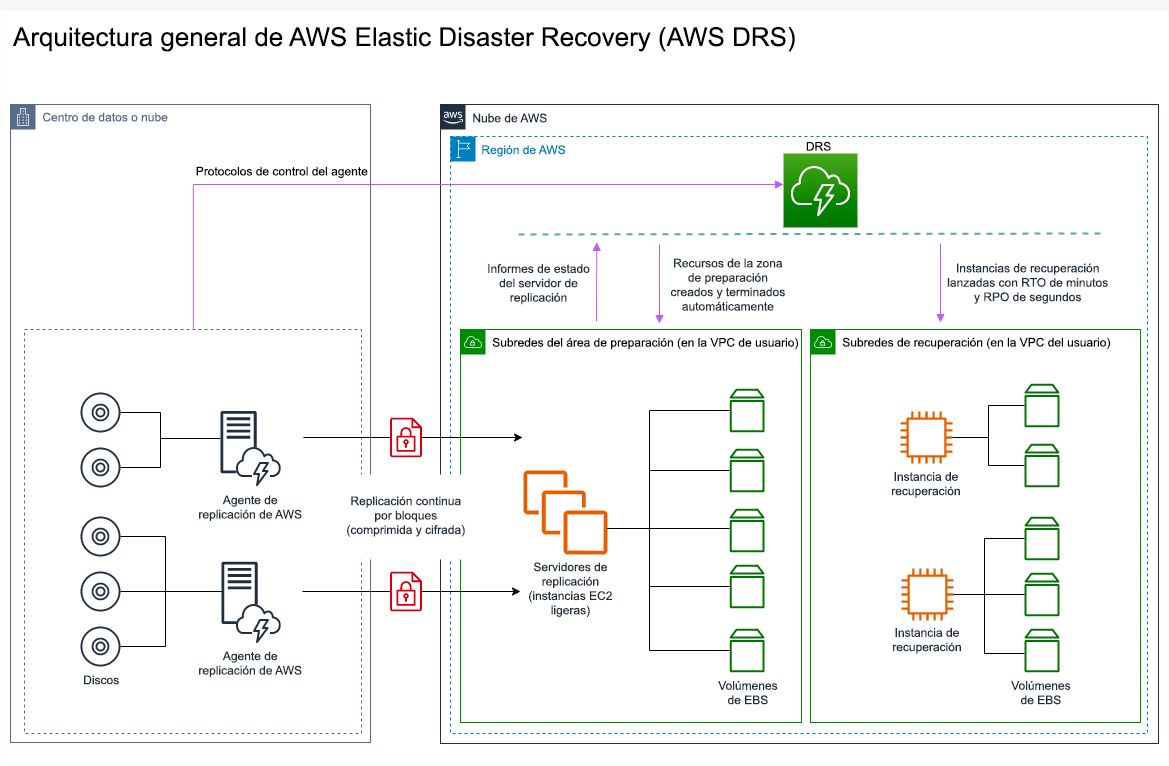
Figura 23: Arquitectura de AWS Elastic Disaster Recovery
Prácticas adicionales para la protección de datos
Con todas las estrategias, también debe mitigar los posibles desastres de datos. La replicación de datos continua le protegerá ante algunos tipos de desastres, pero no ante el daño o la destrucción de datos, a no ser que su estrategia incluya también control de versiones para una recuperación a un momento dado. También debe realizar una copia de seguridad de los datos replicados en el sitio de recuperación para crear copias de seguridad a un momento dado además de las réplicas.
Uso de varias zonas de disponibilidad (AZ) en una únicaRegión de AWS
Al usar varias AZ en una única región, su implementación de DR utiliza varios elementos de las estrategias anteriores. Primero, debe crear una arquitectura de alta disponibilidad utilizando varias AZ, como se muestra en la figura 23. Esta arquitectura hace uso de un enfoque activo-activo multisitio, ya que las instancias Amazon EC2 y el equilibrador de carga elástico tienen recursos desplegados en varias AZ, que gestionan las solicitudes de forma activa. La arquitectura también dispone de espera activa, en la que si la instancia principal de Amazon RDS produce un error (o la propia AZ tiene un error), la instancia en espera pasa a ser la principal.
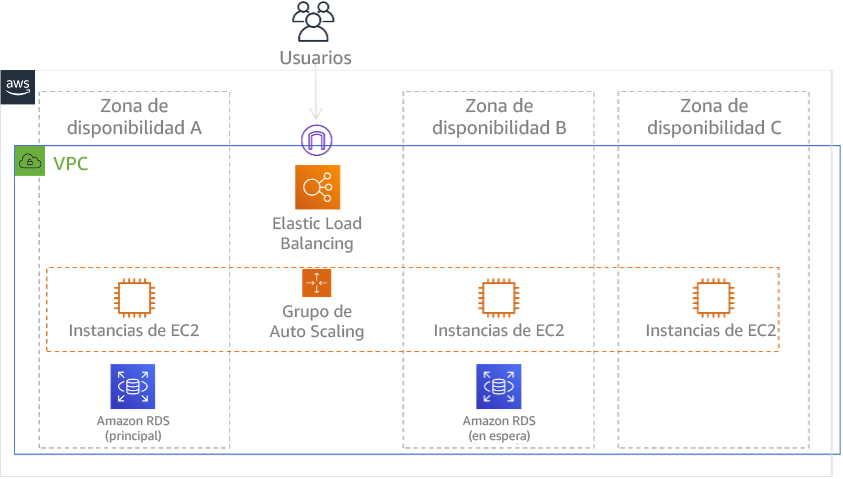
Figura 24: Arquitectura multi-AZ
Además de esta arquitectura de alta disponibilidad, necesita agregar copias de seguridad con todos los datos necesarios para ejecutar su carga de trabajo. Esto es especialmente importante para datos que estén limitados a una única zona, como los volúmenes de Amazon EBS o los clústeres de Amazon Redshift. Si falla una AZ, tendrá que restaurar estos datos en otra AZ. Siempre que sea posible, deberá copiar las copias de seguridad de los datos en otra Región de AWS como capa de protección adicional.
En la publicación de blog, Building highly resilient applications using Amazon Route 53 Application Recovery Controller, Part 1: Single-Region stack
nota
Algunas cargas de trabajo tienen requisitos normativos de residencia de los datos. Si esto se aplica a su carga de trabajo en una ubicación que actualmente tenga solo una Región de AWS, el enfoque multirregión no se adaptará a sus necesidades empresariales. Las estrategias multi-AZ ofrecen una buena protección contra la mayor parte de los desastres.
-
Evalúe los recursos de su carga de trabajo y cuál será su configuración en la región de recuperación antes de la conmutación por error (durante la operación normal).
Para la infraestructura y los recursos de AWS, utilice infraestructura como código como AWS CloudFormation
Todas las estrategias de DR requieren que se realicen copias de seguridad de los orígenes de datos en la Región de AWS, y que estas copias de seguridad se copien en la región de recuperación. AWS Backup
Para obtener más información sobre cómo funcionan los servicios de AWS en todas las regiones, consulte esta serie de blogs sobre Creating a Multi-Region Application with AWS Services
-
Determine e implemente cómo preparará su región de recuperación para la conmutación por error cuando sea necesario (durante un evento de desastre).
En el caso de la opción activa-activa multisitio, la conmutación por error implica evacuar una región y recurrir a las regiones activas restantes. En general, esas regiones están listas para aceptar tráfico. En las estrategias luz piloto y espera semiactiva, sus acciones de recuperación tendrán que desplegar los recursos faltantes, como las instancias EC2 en la figura 20, además de otros recursos faltantes.
En todas las estrategias anteriores, es posible que tenga que promover instancias de solo lectura de bases de datos para que se conviertan en la instancia de lectura y escritura principal.
En copias de seguridad y restauración, la restauración de datos desde una copia de seguridad crea recursos para esos datos, como volúmenes EBS, instancias de bases de datos RDS y tablas de DynamoDB. También tiene que restaurar la infraestructura y desplegar el código. Puede usar AWS Backup para restaurar datos en la región de recuperación. Consulte REL09-BP01 Identificar todos los datos de los que se debe hacer una copia de seguridad y crearla o reproducir los datos a partir de los orígenes para obtener más información. La reconstrucción de la infraestructura incluye la creación de recursos como instancias EC2, además de Amazon Virtual Private Cloud (Amazon VPC)
-
Determine e implemente cómo redirigirá su tráfico a la conmutación por error cuando sea necesario (durante un evento de desastre).
Esta operación de conmutación por error se puede iniciar automáticamente o manualmente. La conmutación por error iniciada automáticamente basada en comprobaciones de estado o alarmas se debe usar con cuidado, ya que una conmutación por error innecesaria (falsa alarma) supone ciertos inconvenientes, como la falta de disponibilidad y la pérdida de datos. Por tanto, la conmutación por error iniciada manualmente es la que se suele utilizar. En este caso, debe seguir automatizando los pasos de la conmutación por error, de modo que la iniciación manual sea como pulsar un botón.
Hay varias opciones de administración del tráfico que tener en cuenta al usar servicios de AWS. Una opción es utilizar Amazon Route 53
Para obtener más información sobre esta y otras opciones, consulte esta sección del documento técnico de recuperación de desastres.
-
Diseñe un plan para la recuperación tras error de su carga de trabajo.
La conmutación por recuperación es cuando se devuelve la operación de una carga de trabajo a la región principal una vez que amaina un evento de desastre. El aprovisionamiento de la infraestructura y el código en la región principal generalmente sigue los mismos pasos que se utilizaron inicialmente, recurriendo a la infraestructura como código y las canalizaciones de despliegue del código. El reto que plantea la conmutación por recuperación es restaurar los almacenes de datos y asegurarse de que sean coherentes con la región de recuperación en funcionamiento.
En el estado de conmutación por error, las bases de datos en la región de recuperación están activas y tienen los datos actualizados. El objetivo es resincronizar desde la región de recuperación a la región principal, garantizando así que esté actualizada.
Algunos servicios de AWS harán esto automáticamente. Si utiliza las tablas globales de Amazon DynamoDB
En los casos en los que esto no se haga automáticamente, tendrá que restablecer la base de datos en la región principal como una réplica de la base de datos en la región de recuperación. En muchos casos, esto supondrá eliminar la antigua base de datos principal y crear nuevas réplicas. Por ejemplo, para obtener instrucciones sobre cómo hacer esto con la base de datos global de Amazon Aurora en el caso de una conmutación por error no planificada, consulte este laboratorio: Fail Back a Global Database
Tras una conmutación por error, si puede seguir operando en su región de recuperación, considere convertir esta región en la nueva región principal. Seguiría realizando los pasos anteriores para hacer que la antigua región principal fuera una región de recuperación. Algunas organizaciones llevan a cabo una rotación programada y cambian sus regiones principal y de recuperación periódicamente (por ejemplo, cada tres meses).
Todos los pasos necesarios para la conmutación por error y la restauración tras error deben mantenerse en una guía de estrategias que esté a disposición de todos los miembros del equipo y se revise periódicamente.
Si utiliza Elastic Disaster Recovery, el servicio ayudará a organizar y automatizar el proceso de conmutación por recuperación. Para obtener más información, consulte Performing a failback (Realizar una conmutación por recuperación).
Nivel de esfuerzo para el plan de implementación: alto
Recursos
Prácticas recomendadas relacionadas:
Documentos relacionados:
-
AWS Architecture Blog: Disaster Recovery Series
(Blog de arquitectura de AWS: serie de recuperación de desastres) -
Crear una solución backend activa-activa sin servidor en varias regiones en una hora
-
Route 53: Configuración de la recuperación ante errores a nivel de DNS
-
What Is AWS Backup? (¿Qué es AWS Backup?)
-
What is Route 53 Application Recovery Controller? (¿Qué es el Controlador de recuperación de aplicaciones de Route 53?)
-
HashiCorp Terraform: Get Started - AWS
(HashiCorp Terraform: primeros pasos: AWS) -
Socio de APN: socios que pueden ayudar con la recuperación de desastres
-
AWS Marketplace: products that can be used for disaster recovery
(AWS Marketplace: productos que pueden usarse para la recuperación de desastres)
Vídeos relacionados:
-
Disaster Recovery of Workloads on AWS
(Recuperación de desastres de cargas de trabajo en AWS) -
AWS re:Invent 2018: Architecture Patterns for Multi-Region Active-Active Applications (ARC209-R2)
(AWS re:Invent 2018: Patrones de arquitectura para aplicaciones activas-activas en varias regiones) -
Get Started with AWS Elastic Disaster Recovery | Amazon Web Services
(Introducción a AWS Elastic Disaster Recovery | Amazon Web Services)
Ejemplos relacionados:
-
Well-Architected Lab - Disaster Recovery
- Series of workshops illustrating DR strategies (Laboratorio de Well-Architected: Recuperación de desastres: serie de talleres que ilustran las estrategias de DR)
