Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Errores grises
Los errores grises se definen por la característica de observabilidad diferencial
Observabilidad diferencial
Las cargas de trabajo que utiliza suelen tener dependencias. Por ejemplo, estas pueden ser los servicios de nube de AWS que se utilizan para crear la carga de trabajo o un proveedor de identidades (IdP) externo que se utiliza para la federación. Esas dependencias casi siempre implementan su propia observabilidad, y registran métricas sobre los errores, la disponibilidad y la latencia, entre otras cosas, que se generan por el uso de los clientes. Cuando se supera un umbral para alguna de estas métricas, la dependencia suele realizar alguna acción para corregirlo.
Estas dependencias suelen tener varios consumidores de sus servicios. Los consumidores también implementan su propia observabilidad y registran métricas y registros sobre sus interacciones con las dependencias, por ejemplo, cuánta latencia hay en las lecturas del disco, cuántas solicitudes de API han fallado o cuánto ha tardado una consulta de base de datos.
Estas interacciones y mediciones se muestran en un modelo abstracto en la siguiente figura.
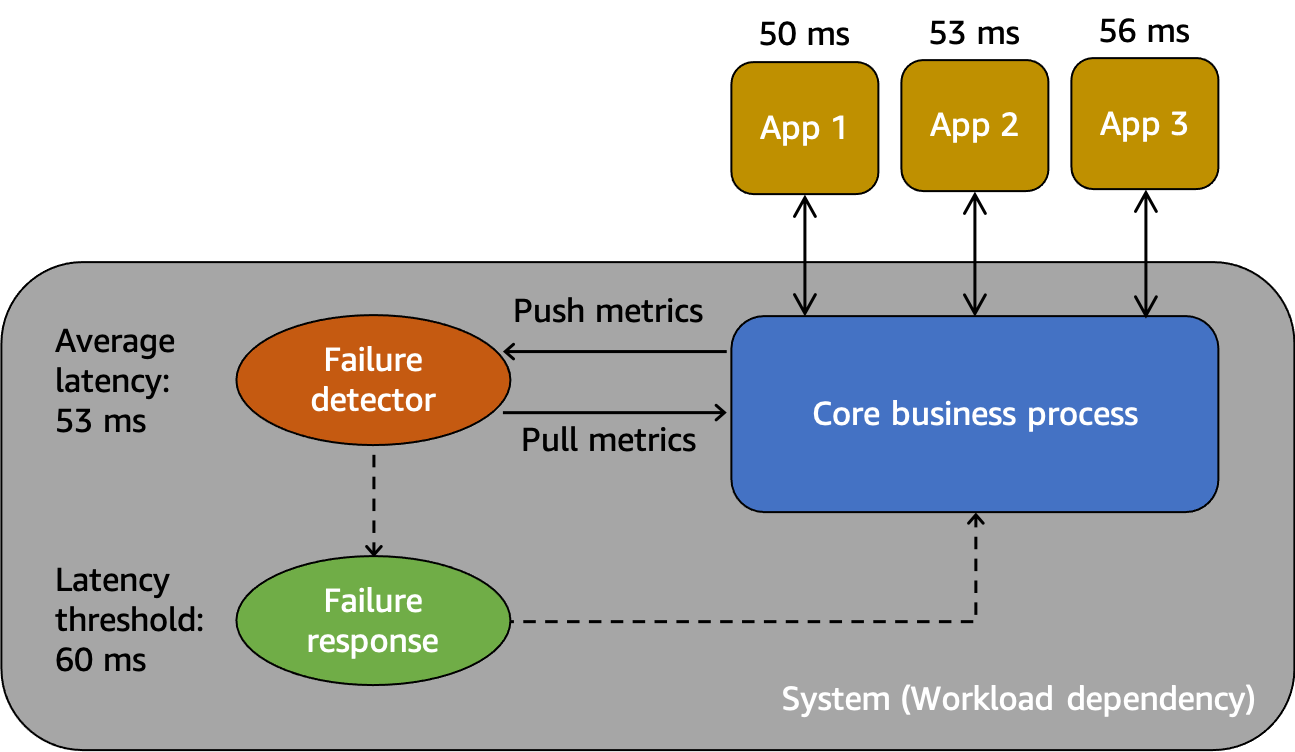
Un modelo abstracto para entender los errores grises
En primer lugar, tenemos el sistema, que es una dependencia de los consumidores Aplicación 1, Aplicación 2 y Aplicación 3 en este escenario. El sistema tiene un detector de errores que examina las métricas creadas a partir del proceso empresarial principal. También cuenta con un mecanismo de respuesta a los errores para mitigar o corregir los problemas observados por el detector de errores. El sistema detecta una latencia media general de 53 ms y ha establecido un umbral para invocar el mecanismo de respuesta a errores cuando la latencia media supera los 60 ms. La Aplicación 1, la Aplicación 2 y la Aplicación 3 también están realizando sus propias observaciones sobre su interacción con el sistema, y registran una latencia media de 50 ms, 53 ms y 56 ms, respectivamente.
La observabilidad diferencial es la situación en la que uno de los usuarios del sistema detecta que el sistema no está funcionando correctamente, pero la propia supervisión del sistema no detecta el problema o el impacto no supera el umbral de alarma. Supongamos que la Aplicación 1 comienza a experimentar una latencia media de 70 ms en lugar de 50 ms. La Aplicación 2 y la Aplicación 3 no ven ningún cambio en sus latencias medias. Esto aumenta la latencia media del sistema subyacente a 59,66 ms, pero no supera el umbral de latencia para activar el mecanismo de respuesta a errores. Sin embargo, la latencia de la Aplicación 1 aumenta un 40 %. Esto podría afectar a su disponibilidad al superar el tiempo de espera del cliente configurado para la Aplicación 1, o puede provocar impactos en cascada en una cadena de interacciones más larga. Desde el punto de vista de la Aplicación 1, el sistema subyacente del que depende no funciona correctamente, pero desde el punto de vista del propio sistema, así como de la Aplicación 2 y la Aplicación 3, el sistema funciona correctamente. En la siguiente figura, se resumen estas diferentes perspectivas.
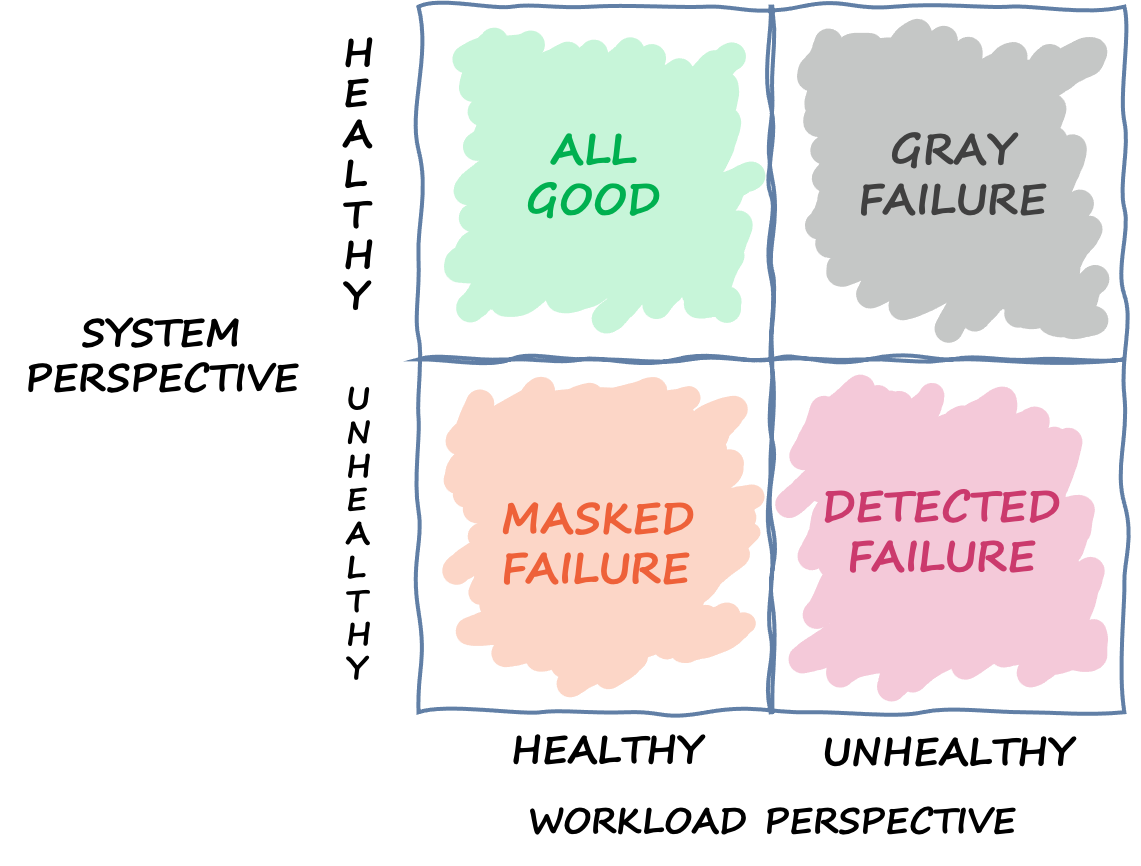
Un cuadrante que define los diferentes estados en los que puede encontrarse un sistema en función de diferentes perspectivas
Un error también puede atravesar este cuadrante. Un evento puede comenzar como un error gris y convertirse después en un error detectado, cambiar a un error enmascarado y, quizás, volver a un error gris. No hay un ciclo definido y casi siempre existe la posibilidad de que se repita el error hasta que se aborde su causa raíz.
La conclusión que sacamos es que las cargas de trabajo no siempre pueden confiar en el sistema subyacente para detectar y mitigar el error. Por muy sofisticado y resiliente que sea el sistema subyacente, siempre existe la posibilidad de que un error pase desapercibido o se quede por debajo del umbral de reacción. Los usuarios de ese sistema, como la Aplicación 1, deben estar preparados para detectar y mitigar rápidamente el impacto que provoca un error gris. Esto requiere crear mecanismos de observabilidad y recuperación para estas situaciones.
Ejemplo de errores grises
Los errores grises pueden afectar a los sistemas Multi-AZ en AWS. Por ejemplo, supongamos una flota de instancias de Amazon EC2
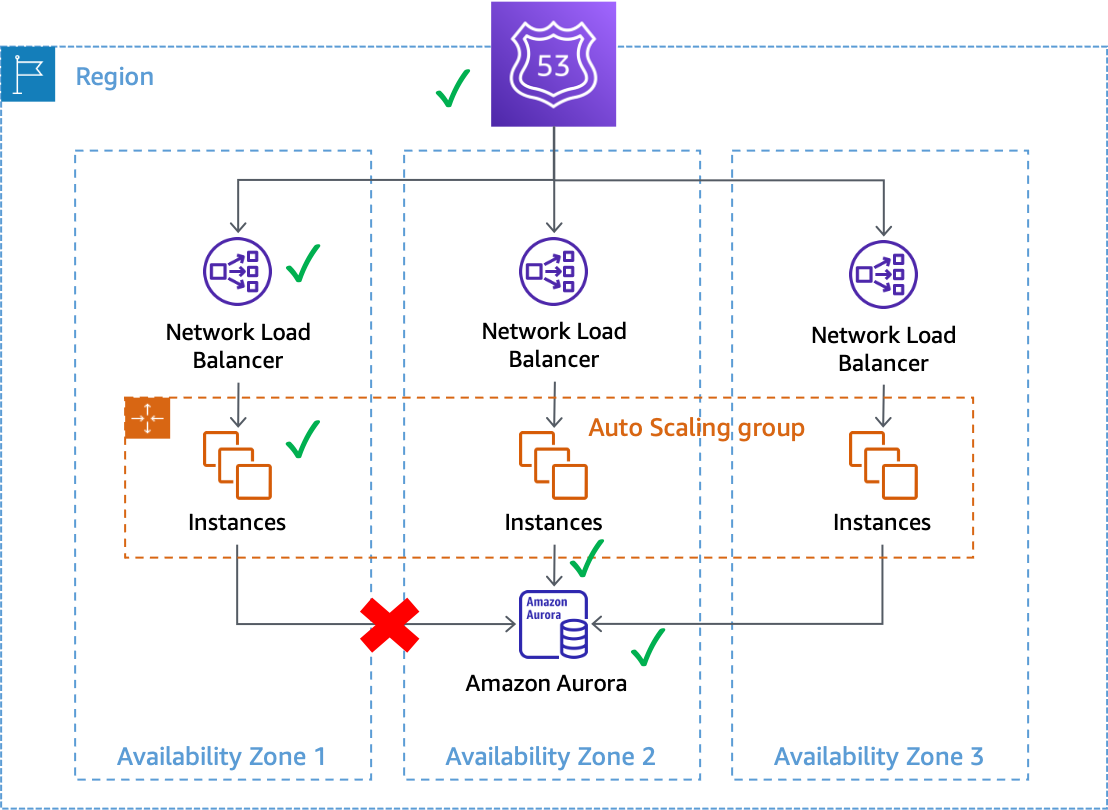
Un error gris que afecta a las conexiones de bases de datos desde las instancias de la Zona de disponibilidad 1
En este ejemplo, Amazon EC2 considera que las instancias de la Zona de disponibilidad 1 tienen un estado correcto porque siguen pasando las comprobaciones de estado del sistema y de las instancias. Amazon EC2 Auto Scaling tampoco detecta un impacto directo en ninguna zona de disponibilidad y continúa lanzando capacidad en las zonas de disponibilidad configuradas. El Equilibrador de carga de red (NLB) también considera que las instancias subyacentes tienen un estado correcto, al igual que las comprobaciones de estado de Route 53 que se realizan en el punto de conexión de NLB. Del mismo modo, Amazon Relational Database Service (Amazon RDS) considera que el clúster de base de datos tiene un estado correcto y no desencadena una conmutación por error automática. Tenemos muchos servicios diferentes y todos consideran que sus servicios y recursos están en buen estado, pero la carga de trabajo detecta un error que afecta a su disponibilidad. Se trata de un error gris.
Respuesta a los errores grises
Cuando se produce un error gris en su entorno de AWS, por lo general tiene tres opciones:
-
No haga nada y espere a que el deterioro desaparezca.
-
Si el deterioro está aislado en una sola zona de disponibilidad, evacue esa zona de disponibilidad.
-
Realice una conmutación por error a otra Región de AWS y aproveche las ventajas del aislamiento regional de AWS para mitigar el impacto.
Muchos clientes de AWS están de acuerdo con la primera opción para la mayoría de sus cargas de trabajo. Aceptan tener un objetivo de tiempo de recuperación (RTO) posiblemente ampliado con la compensación de no haber tenido que desarrollar soluciones adicionales de observabilidad o resiliencia. Otros clientes optan por implementar la tercera opción, la Recuperación de desastres (DR) multirregional
En primer lugar, crear y operar una arquitectura multirregional puede ser una tarea difícil, compleja y potencialmente costosa. Las arquitecturas multirregionales requieren una cuidadosa consideración de la estrategia de recuperación de desastres que se elija. Puede que no sea viable desde el punto de vista fiscal implementar una solución de DR activa-activa multirregional solo para manejar deterioros zonales, mientras que una estrategia de respaldo y restauración puede que no cumpla sus requisitos de resiliencia. Además, las conmutaciones por error multirregionales deben practicarse de forma continua en la producción para tener la seguridad de que funcionarán cuando sea necesario. Todo esto requiere una gran cantidad de tiempo y recursos dedicados a la creación, el funcionamiento y las pruebas.
En segundo lugar, la replicación de datos en distintas Regiones de AWS utilizando servicios de AWS en la actualidad se realiza de forma asíncrona. La replicación asíncrona puede provocar la pérdida de datos. Esto significa que, durante una conmutación por error regional, existe la posibilidad de que se pierdan algunos datos o se produzcan incoherencias. Su tolerancia a la cantidad de pérdida de datos se define como su Objetivo de punto de recuperación (RPO). Los clientes, para los que se exige una sólida coherencia de datos, deberán crear sistemas de conciliación para solucionar estos problemas de coherencia cuando la región principal vuelva a estar disponible. O bien, deberán crear sus propios sistemas de replicación sincrónica o de escritura doble, lo que puede tener un impacto significativo en la latencia, el costo y la complejidad de la respuesta. También hacen que la región secundaria sea una fuerte dependencia para cada transacción, lo que puede reducir la disponibilidad del sistema en general.
Por último, para muchas cargas de trabajo que utilizan un enfoque activo/en espera, se necesita un tiempo distinto de cero para realizar la conmutación por error a otra región. Es posible que su cartera de cargas de trabajo deba reducirse en la región principal en un orden específico, agotar las conexiones o detener procesos específicos. Posteriormente, puede que sea necesario volver a activar los servicios en un orden específico. Es posible que también haya que aprovisionar nuevos recursos o que necesiten tiempo para pasar las comprobaciones de estado pertinentes antes de entrar en servicio. Este proceso de conmutación por error se puede experimentar como un período de completa falta de disponibilidad. Esto es lo que preocupa a los RTO.
Dentro de una región, muchos servicios de AWS ofrecen una persistencia de datos muy uniforme. Las implementaciones de Amazon RDS Multi-AZ utilizan la replicación sincrónica. Amazon Simple Storage Service
La evacuación de una zona de disponibilidad puede tener un RTO más bajo que una estrategia multirregional, ya que la infraestructura y los recursos ya están aprovisionados en todas las zonas de disponibilidad. Las arquitecturas Multi-AZ pueden seguir funcionando de forma estática cuando una zona de disponibilidad se ve afectada, en lugar de tener que ordenar cuidadosamente los servicios que se activan y desactivan, o bien agotar las conexiones. En lugar de pasar por un período de total falta de disponibilidad como el que puede producirse durante una conmutación por error regional, durante la evacuación de una zona de disponibilidad, es posible que muchos sistemas solo sufran una ligera degradación, ya que el trabajo se traslada a las zonas de disponibilidad restantes. Si el sistema se ha diseñado para mantener una estabilidad estática
Es posible que el deterioro de una sola zona de disponibilidad afecte a uno o varios servicios regionales de AWS, además de a la carga de trabajo. Si observa un impacto regional, debe tratar el evento como un deterioro del servicio regional, aunque el origen de ese impacto provenga de una sola zona de disponibilidad. La evacuación de una zona de disponibilidad no mitigará este tipo de problema. Utilice los planes de respuesta que tenga establecidos para responder a un deterioro del servicio regional cuando esto ocurra.
El resto de este documento se centra en la segunda opción, la evacuación de la zona de disponibilidad, como forma de reducir los RTO y los RPO en caso de errores grises en zonas de disponibilidad individuales. Estos patrones pueden ayudar a mejorar el rendimiento de las arquitecturas Multi-AZ y, para la mayoría de las clases de cargas de trabajo, pueden reducir la necesidad de crear arquitecturas multirregionales para manejar este tipo de eventos.
