Administración de datos distribuidos
Las aplicaciones monolíticas generalmente están respaldadas por una gran base de datos relacional, que define un único modelo de datos común a todos los componentes de la aplicación. En un enfoque de microservicios, una base de datos central así evitaría el objetivo de crear componentes descentralizados e independientes. Cada componente del microservicio debe tener su propia capa de persistencia de datos.
La administración de datos distribuidos, sin embargo, plantea nuevos retos. Como consecuencia del Teorema CAP, las arquitecturas de microservicios distribuidos intercambian la consistencia por el rendimiento y necesitan adoptar la consistencia final.
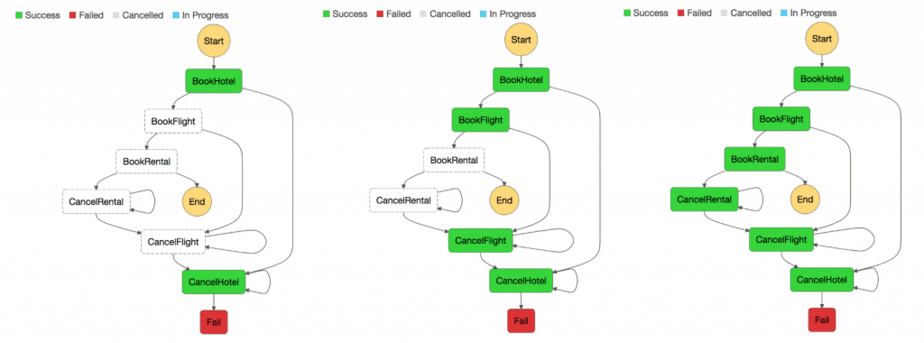
En un sistema distribuido, las transacciones empresariales pueden abarcar varios microservicios. Como no pueden utilizar una transacción ACID única, puede terminar con ejecuciones parciales. En este caso, necesitaríamos algún tipo de lógica de control para volver a realizar las transacciones que ya fueron procesadas. Para este fin, normalmente se utiliza el patrón Saga distribuido. Cuando ocurre un error en una transacción comercial, Saga orquesta una serie de transacciones de compensación para anular los cambios que fueron realizados por las transacciones anteriores. AWS Step Functions facilita la implementación de un coordinador de ejecución de Saga, como se muestra en la siguiente figura.
Coordinador de ejecución de Saga
La creación de un almacén centralizado de datos de referencia clave que se depuran mediante herramientas y procedimientos de administración de datos básicos proporciona un medio para que los microservicios puedan sincronizar sus datos clave y posiblemente restaurar el estado anterior. El uso de Lambda con eventos programados de Amazon CloudWatch Events puede crear un mecanismo simple de limpieza y desduplicación.
Es muy común que los cambios de estado afecten a más de un microservicio. En esos casos, el abastecimiento de eventos ha demostrado ser un patrón útil. La idea central detrás del abastecimiento de eventos es representar y mantener cada cambio de la aplicación como un registro de eventos. En lugar de mantener el estado de la aplicación, los datos se almacenan como un stream de eventos. Los sistemas de control de versiones y registro de transacciones de la base de datos son dos ejemplos bien conocidos para el abastecimiento de eventos. El abastecimiento de eventos tiene un par de beneficios: el estado puede determinarse y reconstruirse en cualquier momento. Naturalmente produce una pista de auditoría persistente y también facilita la depuración.
En el contexto de las arquitecturas de microservicios, el abastecimiento de eventos permite desacoplar diferentes partes de una aplicación mediante el uso de un patrón de publicación o suscripción, y alimenta los mismos datos de eventos en diferentes modelos de datos para microservicios separados. El abastecimiento de eventos se usa con frecuencia junto con el patrón Comando, Consulta, Responsabilidad, Segregación (CQRS) para desacoplar la lectura de las cargas de trabajo de escritura y optimizar tanto el rendimiento como la escalabilidad y la seguridad. En los sistemas de administración de datos tradicionales, los comandos y las consultas se ejecutan en el mismo repositorio de datos.
En la siguiente figura se muestra cómo se puede implementar el patrón de abastecimiento de eventos en AWS. Amazon Kinesis Data Streams es el componente principal del almacén central de eventos que registra los cambios de las aplicaciones como eventos y los conserva en Amazon S3. La figura representa tres microservicios diferentes compuestos por Amazon API Gateway, AWS Lambda y Amazon DynamoDB. Las flechas indican el flujo de los eventos: cuando el Microservicio 1 experimenta un cambio de estado de evento, escribe un mensaje en Kinesis Data Streams para publicar un evento. Todos los microservicios ejecutan su propia aplicación de Kinesis Data Streams en AWS Lambda, que lee una copia del mensaje, la filtra según la relevancia para el microservicio y, posiblemente, la reenvía para su procesamiento posterior. Si la función devuelve un error, Lambda volverá a intentar ejecutar el lote hasta que el procesamiento se realice correctamente o los datos caduquen. Para evitar particiones detenidas, puede configurar la asignación del origen de eventos para que vuelva a intentarlo con un tamaño de lote menor, para que limite el número de reintentos o para que se descarten los registros que sean muy antiguos. Si desea conservar los eventos descartados, puede configurar la asignación del origen de eventos para que envíe información sobre los lotes con errores a una cola de Amazon Simple Queue Service (Amazon SQS) o a un tema de Amazon Simple Notification Service (Amazon SNS).
Patrón de abastecimiento de eventos en AWS
Amazon S3 almacena de forma duradera todos los eventos en todos los microservicios y es la única fuente de la verdad cuando se trata de depurar, recuperar el estado de la aplicación o auditar los cambios de la aplicación. Hay dos principales razones por las que registros podrían entregarse más de una vez en su aplicación Kinesis Data Streams: reintentos de los productores y reintentos de los consumidores. Su aplicación debe prever y administrar de forma adecuada el procesamiento de registros individuales varias veces.