Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Instrumentación AWS Lambda funciones
nota
X-Ray SDK/Daemon Aviso de mantenimiento: el 25 de febrero de 2026, AWS X-Ray SDKs/Daemon entrará en modo de mantenimiento, en el que AWS se limitarán las versiones de X-Ray SDK y Daemon para abordar únicamente los problemas de seguridad. Para obtener más información sobre la cronología del soporte, consulte Cronología de X-Ray SDK y Daemon Support. Recomendamos migrar a. OpenTelemetry Para obtener más información sobre la migración a OpenTelemetry, consulte Migración de una X-Ray instrumentación a otra. OpenTelemetry
Scorekeep utiliza dos funciones. AWS Lambda La primera es una Node.js función de la lambda rama que genera nombres aleatorios para los nuevos usuarios. Cuando un usuario crea una sesión sin introducir ningún nombre, la aplicación llama a una función denominada random-name con el AWS SDK para Java. El X-Ray SDK para Java registra la información sobre la llamada a Lambda en un subsegmento, como cualquier otra llamada realizada con un cliente SDK AWS instrumentado.
nota
La ejecución de la función de Lambda random-name requiere la creación de recursos adicionales fuera del entorno de Elastic Beanstalk. Consulte el archivo readme para obtener más información e instrucciones: AWS
Lambda Integration
La segunda función, scorekeep-worker, es una función de Python que se ejecuta de forma independiente de la API de Scorekeep. Cuando un juego termina, la API escribe el ID de sesión y el ID de juego en una cola de SQS. La función de proceso de trabajo lee los elementos de la cola y llama a la API de Scorekeep con el fin de construir registros completos de cada sesión de juego para su almacenamiento en Amazon S3.
Scorekeep incluye CloudFormation plantillas y scripts para crear ambas funciones. Como es necesario empaquetar el X-Ray SDK con el código de la función, las plantillas crean las funciones sin ningún tipo de código. Al implementar Scorekeep, un archivo de configuración incluido en la carpeta .ebextensions crea un paquete de origen que incluye el SDK y actualiza el código de la función y la configuración con el AWS Command Line Interface.
Funciones
Nombre aleatorio
Scorekeep llama a la función de nombre aleatorio cuando un usuario comienza una sesión de juego sin iniciar sesión o especificar un nombre de usuario. Cuando Lambda procesa la llamada arandom-name, lee el encabezado de seguimiento, que contiene el ID de seguimiento y la decisión de muestreo redactados por el X-Ray SDK for Java.
Para cada solicitud muestreada, Lambda ejecuta X-Ray el daemon y escribe dos segmentos. El primer segmento registra información sobre la llamada a Lambda que invoca la función. Este segmento contiene la misma información que el subsegmento registrado por Scorekeep, pero desde el punto de vista de Lambda. El segundo segmento representa el trabajo que hace la función.
Lambda pasa el segmento de función al X-Ray SDK a través del contexto de la función. Cuando instrumente una función de Lambda, no utilice el SDK con el fin de crear un segmento para las solicitudes entrantes. Lambda proporciona el segmento y usted debe utilizar el SDK para instrumentar clientes y escribir subsegmentos.
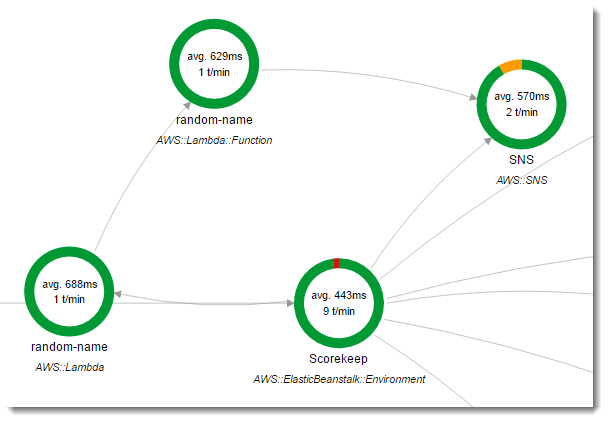
La random-name función se implementa en Node.js. Utiliza el SDK Node.js para JavaScript enviar notificaciones con Amazon SNS y el X-Ray SDK Node.js para instrumentar el cliente del AWS SDK. Para escribir anotaciones, la función crea un subsegmento personalizado con AWSXRay.captureFunc y escribe anotaciones en la función instrumentada. En Lambda, no puede escribir anotaciones directamente en el segmento de la función, únicamente en un subsegmento que cree.
ejemplo function/index.js
var AWSXRay = require('aws-xray-sdk-core');
var AWS = AWSXRay.captureAWS(require('aws-sdk'));
AWS.config.update({region: process.env.AWS_REGION});
var Chance = require('chance');
var myFunction = function(event, context, callback) {
var sns = new AWS.SNS();
var chance = new Chance();
var userid = event.userid;
var name = chance.first();
AWSXRay.captureFunc('annotations', function(subsegment){
subsegment.addAnnotation('Name', name);
subsegment.addAnnotation('UserID', event.userid);
});
// Notify
var params = {
Message: 'Created randon name "' + name + '"" for user "' + userid + '".',
Subject: 'New user: ' + name,
TopicArn: process.env.TOPIC_ARN
};
sns.publish(params, function(err, data) {
if (err) {
console.log(err, err.stack);
callback(err);
}
else {
console.log(data);
callback(null, {"name": name});
}
});
};
exports.handler = myFunction;Esta función se crea automáticamente al implementar la aplicación de ejemplo en Elastic Beanstalk. La ramificación xray incluye un script para crear una función de Lambda en blanco. Los archivos de configuración de la .ebextensions carpeta crean el paquete de funciones npm install durante la implementación y, a continuación, actualizan la función Lambda con la CLI AWS .
Entorno de trabajo
La función de trabajo instrumentada se proporciona en su propia ramificación, xray-worker, ya que no se puede ejecutar a menos que antes cree la función de trabajo y los recursos relacionados. Consulte el archivo readme de la ramificación
La función se activa mediante un paquete de CloudWatch eventos de Amazon Events cada 5 minutos. Cuando se ejecuta, la función extrae un elemento de una cola de Amazon SQS que administra Scorekeep. Cada mensaje contiene información sobre un juego terminado.
El trabajo extrae los documentos y el registro del juego de otras tablas a las que hace referencia el registro de juego. Por ejemplo, el registro del juego en DynamoDB incluye una lista de los movimientos que se han realizado durante el juego. La lista no contiene los movimientos en sí, sino los ID de los movimientos que están almacenados en una tabla distinta.
Las sesiones y los estados también se almacenan como referencias. Esto impide que las entradas de la tabla de juego sean demasiado grandes, pero requiere llamadas adicionales para obtener toda la información sobre el juego. El proceso de trabajo anula las referencias a todas estas entradas y construye un registro completo del juego como un único documento en Amazon S3. Cuando desee realizar el análisis de los datos, podrá ejecutar consultas en él directamente en Amazon S3 con Amazon Athena sin ejecutar migraciones de datos que realizan muchas lecturas para obtener los datos de DynamoDB.
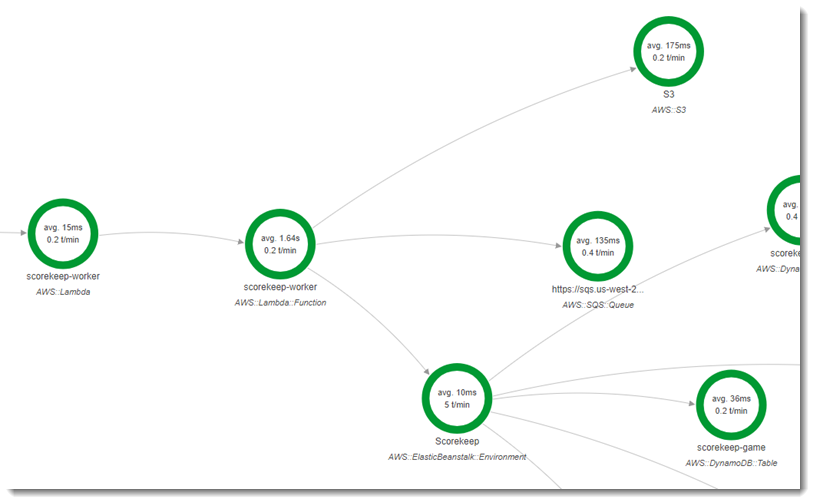
La función de trabajo tiene habilitado el rastreo activo en su configuración en AWS Lambda. A diferencia de la función de nombres aleatorios, el trabajador no recibe una solicitud de una aplicación instrumentada, por lo que AWS Lambda no recibe un encabezado de seguimiento. Con el rastreo activo, Lambda crea el ID de rastro y toma decisiones de muestreo.
El X-Ray SDK para Python está solo unas líneas en la parte superior de la función que importa el SDK y ejecuta su patch_all función para parchear los HttpClients que utiliza para llamar a Amazon SQS AWS SDK para Python (Boto) y Amazon S3. Cuando el trabajo llama a la API de Scorekeep, el SDK añade el encabezado de rastreo a la solicitud para rastrear llamadas a través de la API.
ejemplo_lambda/scorekeep- -worker.py worker/scorekeep
import os
import boto3
import json
import requests
import time
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
patch_all()
queue_url = os.environ['WORKER_QUEUE']
def lambda_handler(event, context):
# Create SQS client
sqs = boto3.client('sqs')
s3client = boto3.client('s3')
# Receive message from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=[
'SentTimestamp'
],
MaxNumberOfMessages=1,
MessageAttributeNames=[
'All'
],
VisibilityTimeout=0,
WaitTimeSeconds=0
)
...