Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Clusters Auto Scaling Valkey et Redis OSS
Conditions préalables
ElastiCache Auto Scaling se limite aux éléments suivants :
-
Clusters Valkey ou Redis OSS (mode cluster activé) exécutant Valkey 7.2 et versions ultérieures, ou Redis OSS 6.0 et versions ultérieures
-
Hiérarchisation des données (mode cluster activé) clusters exécutant Valkey 7.2 ou version ultérieure de Redis OSS 7.0.7
-
Tailles d'instance : Large, XLarge, 2xLarge
-
Familles de types d’instances : R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
Auto Scaling in n' ElastiCache est pas pris en charge pour les clusters exécutés dans des banques de données mondiales, des Outposts ou des Zones Locales.
Gestion automatique de la capacité avec ElastiCache Auto Scaling avec Valkey ou Redis OSS
ElastiCache la mise à l'échelle automatique avec Valkey ou Redis OSS permet d'augmenter ou de diminuer automatiquement les partitions ou les répliques souhaitées dans votre service. ElastiCache ElastiCache utilise le service Application Auto Scaling pour fournir cette fonctionnalité. Pour en savoir plus, veuillez consulter Application Auto Scaling. Pour utiliser le dimensionnement automatique, vous définissez et appliquez une politique de dimensionnement qui utilise CloudWatch les métriques et les valeurs cibles que vous attribuez. ElastiCache Auto Scaling utilise la politique pour augmenter ou diminuer le nombre d'instances en réponse aux charges de travail réelles.
Vous pouvez utiliser le AWS Management Console pour appliquer une politique de dimensionnement basée sur une métrique prédéfinie. Une métrique predefined metric est définie dans une énumération de telle sorte que vous pouvez la spécifier par son nom dans le code ou l'utiliser dans la AWS Management Console. Les métriques personnalisées ne sont pas disponibles pour la sélection à l'aide de la AWS Management Console. Vous pouvez également utiliser l'API Application Auto Scaling AWS CLI ou l'API Application Auto Scaling pour appliquer une politique de dimensionnement basée sur une métrique prédéfinie ou personnalisée.
ElastiCache pour Valkey et Redis, OSS prend en charge le dimensionnement pour les dimensions suivantes :
-
Partitions : add/removepartitions automatiques dans le cluster, de la même manière que le repartage manuel en ligne. Dans ce cas, le dimensionnement ElastiCache automatique déclenche le dimensionnement en votre nom.
-
Répliques : add/removerépliques automatiques dans le cluster, de la même manière que les opérations de Increase/Decrease réplication manuelles. ElastiCache mise à l'échelle automatique des adds/removes répliques Valkey et Redis OSS de manière uniforme sur toutes les partitions du cluster.
ElastiCache pour Valkey et Redis OSS prend en charge les types de politiques de dimensionnement automatique suivants :
-
Politiques de dimensionnement Suivi de la cible— Augmentez ou diminuez le nombre shards/replicas d'exécutions de votre service en fonction d'une valeur cible pour une métrique spécifique. Cette option est similaire à la façon dont votre thermostat maintient la température de votre domicile. Vous sélectionnez une température et le thermostat se charge du reste.
-
Dimensionnement planifié pour votre application. — ElastiCache pour Valkey et Redis OSS, le dimensionnement automatique peut augmenter ou diminuer le nombre d'exécutions de shards/replicas votre service en fonction de la date et de l'heure.
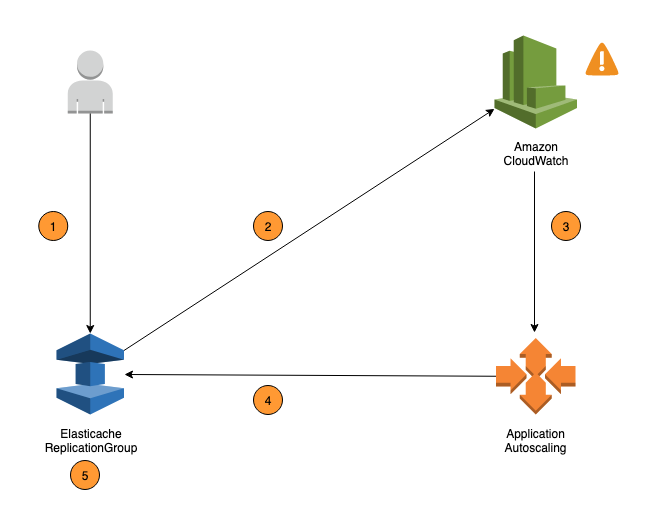
Les étapes suivantes résument le processus de mise à l'échelle automatique ElastiCache pour Valkey et Redis OSS, comme indiqué dans le schéma précédent :
-
Vous créez une politique de dimensionnement ElastiCache automatique pour votre groupe de réplication.
-
ElastiCache Auto Scaling crée une paire d' CloudWatch alarmes en votre nom. Chaque paire représente vos limites supérieure et inférieure pour les métriques. Ces CloudWatch alarmes sont déclenchées lorsque l'utilisation réelle du cluster s'écarte de votre utilisation cible pendant une période prolongée. Vous pouvez afficher les alarmes dans la console.
-
Si la valeur de mesure configurée dépasse votre objectif d'utilisation (ou tombe en dessous de l'objectif) pendant une période donnée, CloudWatch déclenche une alarme qui déclenche le dimensionnement automatique pour évaluer votre politique de dimensionnement.
-
ElastiCache Auto Scaling émet une demande de modification pour ajuster la capacité de votre cluster.
-
ElastiCache traite la demande de modification en augmentant (ou en diminuant) dynamiquement la Shards/Replicas capacité du cluster afin qu'elle se rapproche de votre objectif d'utilisation.
Pour comprendre le fonctionnement d' ElastiCache Auto Scaling, supposons que vous ayez un cluster nomméUsersCluster. En surveillant les CloudWatch métriquesUsersCluster, vous déterminez le nombre maximum de partitions dont le cluster a besoin lorsque le trafic est à son maximum et le nombre minimal de partitions lorsque le trafic est à son point le plus bas. Vous définissez également une valeur cible pour l'utilisation du processeur pour le UsersCluster cluster. ElastiCache auto scaling utilise son algorithme de suivi des cibles pour s'assurer que les partitions provisionnées UsersCluster sont ajustées selon les besoins afin que l'utilisation reste égale ou proche de la valeur cible.
Note
La mise à l'échelle peut prendre un certain temps et nécessitera des ressources de cluster supplémentaires pour que les partitions puissent être rééquilibrées. ElastiCache Auto Scaling modifie les paramètres des ressources uniquement lorsque la charge de travail réelle reste élevée (ou diminuée) pendant une période prolongée de plusieurs minutes. L'algorithme de suivi des cibles à mise à l'échelle automatique vise à maintenir l'utilisation de la cible à la valeur que vous avez choisie ou à un niveau proche de celle-ci sur le long terme.
Autorisations IAM requises pour Auto Scaling
ElastiCache pour Valkey et Redis OSS Auto Scaling est rendu possible par une combinaison des API Application Auto Scaling et Application Auto Scaling. ElastiCache CloudWatch Les clusters sont créés et mis à jour avec ElastiCache, les alarmes sont créées avec CloudWatch et les politiques de dimensionnement sont créées avec Application Auto Scaling. Outre les autorisations IAM standard pour créer et mettre à jour des clusters, l'utilisateur IAM qui accède aux paramètres d' ElastiCache Auto Scaling doit disposer des autorisations appropriées pour les services qui prennent en charge le dimensionnement dynamique. Dans cette politique la plus récente, nous avons ajouté la prise en charge de la mise à l'échelle verticale de Memcached, avec l'action. elasticache:ModifyCacheCluster Les utilisateurs IAM doivent disposer des autorisations nécessaires pour utiliser les actions indiquées dans l’exemple de politique suivant :
Service-linked rôle
Le service de mise à l'échelle automatique ElastiCache pour Valkey et Redis OSS nécessite également une autorisation pour décrire vos clusters et vos CloudWatch alarmes, ainsi que des autorisations pour modifier votre capacité ElastiCache cible en votre nom. Si vous activez Auto Scaling pour votre cluster, il crée un rôle lié à un service nommé. AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG Ce rôle lié au service accorde à ElastiCache Auto Scaling l'autorisation de décrire les alarmes correspondant à vos politiques, de surveiller la capacité actuelle de la flotte et de modifier la capacité de la flotte. Le rôle lié au service est le rôle par défaut pour le dimensionnement ElastiCache automatique. Pour plus d'informations, consultez la section Service-linked Rôles ElastiCache pour le dimensionnement automatique de Redis OSS dans le Guide de l'utilisateur d'Application Auto Scaling.
Bonnes pratiques pour Auto Scaling
Avant de vous inscrire à Auto Scaling, nous vous recommandons de procéder comme suit :
-
Utiliser une seule métrique de suivi : identifiez si votre cluster a des charges de travail gourmandes en processeur ou en données et utilisez une métrique prédéfinie correspondante pour définir la politique de mise à l'échelle.
-
Processeur du moteur :
ElastiCachePrimaryEngineCPUUtilization(dimension de la partition) ouElastiCacheReplicaEngineCPUUtilization(dimension du réplica) -
Utilisation de la base de données :
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentage. Cette politique de mise à l'échelle fonctionne de manière optimale lorsque maxmemory-policy est définie sur noeviction sur le cluster.
Nous vous recommandons d'éviter d'appliquer plusieurs politiques par dimension sur le cluster. ElastiCache pour Valkey et Redis OSS Auto Scaling augmentera la taille de la cible évolutive si des politiques de suivi des cibles sont prêtes à être étendues, mais elle ne sera étendue que si toutes les politiques de suivi des cibles (avec la partie scale-in activée) sont prêtes à être étendues. Si plusieurs politiques indiquent simultanément à la cible évolutive de procéder à une montée en puissance ou à une diminution de charge, elle effectue la mise à l'échelle en fonction de la politique qui fournit la plus grande capacité à la fois pour la montée et la diminution en charge.
-
-
Mesures personnalisées pour le suivi des cibles : soyez prudent lorsque vous utilisez des mesures personnalisées pour le suivi des cibles, car la mise à l'échelle automatique est mieux adaptée à une échelle out/in proportionnelle à l'évolution des mesures choisies pour la politique. Si ces métriques ne changent pas de manière proportionnelle pour les actions de mise à l'échelle utilisées pour la création de politiques, cela peut entraîner des actions de montée en puissance et de mise à l'échelle horizontale continues pouvant affecter la disponibilité ou le coût.
Pour les clusters avec hiérarchisation des données (types d'instances de la famille r6gd), évitez d'utiliser des métriques basées sur la mémoire pour la mise à l'échelle.
-
Dimensionnement planifié : si vous constatez que votre charge de travail est déterministe ( high/low atteinte à un moment précis), nous vous recommandons d'utiliser le dimensionnement planifié et de configurer votre capacité cible en fonction des besoins. Le suivi de cible est mieux adapté aux charges de travail non déterministes et au cluster pour fonctionner à la métrique cible requise en augmentant la capacité lorsque vous avez besoin de plus de ressources et en la diminuant lorsque vous en avez besoin de moins.
-
Désactiver Scale-In — La mise à l'échelle automatique sur Target Tracking convient parfaitement aux clusters dont les charges increase/decrease de travail sont progressives, car spikes/dip les métriques peuvent déclencher des out/in oscillations d'échelle consécutives. Afin d'éviter de telles oscillations, vous pouvez commencer par désactiver la mise à l'échelle horizontale et, par la suite, vous pouvez toujours adapter manuellement à vos besoins.
-
Testez votre application : nous vous recommandons de tester votre application avec vos Min/Max charges de travail estimées afin de déterminer les valeurs minimales et maximales absolues shards/replicas requises pour le cluster, tout en créant des politiques de dimensionnement pour éviter les problèmes de disponibilité. La scalabilité automatique peut monter en puissance la capacité jusqu'au seuil Max et mettre à l'échelle horizontale la capacité jusqu'au seuil Min configuré pour la cible.
-
Définition de la valeur cible : vous pouvez analyser les CloudWatch mesures correspondantes relatives à l'utilisation du cluster sur une période de quatre semaines afin de déterminer le seuil de valeur cible. Si vous n'êtes toujours pas sûr de la valeur à choisir, nous vous recommandons de commencer par une valeur de métrique prédéfinie minimale prise en charge.
-
AutoScaling sur Target Tracking convient parfaitement aux clusters dotés d'une répartition uniforme des charges de travail entre les shards/replicas dimensions. Une distribution non uniforme peut conduire à :
-
Mise à l'échelle lorsque cela n'est pas nécessaire en raison de spike/dip la charge de travail sur quelques appareils shards/replicas.
-
Pas de mise à l'échelle lorsque cela est nécessaire en raison de la moyenne globale proche de la cible, même en cas de chaleur shards/replicas.
-
Note
Lorsque vous agrandissez votre cluster, les fonctions chargées dans l'un des nœuds existants (sélectionnées au hasard) ElastiCache seront automatiquement répliquées sur le ou les nouveaux nœuds. Si votre cluster utilise Valkey ou Redis OSS 7.0 ou une version ultérieure et que votre application utilise Functions
Après vous être inscrit auprès de AutoScaling, notez ce qui suit :
-
Il existe des limitations sur les configurations de scalabilité automatique prises en charge, nous vous recommandons donc de ne pas modifier la configuration d'un groupe de réplication qui est inscrit pour la scalabilité automatique. Voici quelques exemples :
-
Modifier manuellement le type d'instance vers des types non pris en charge.
-
Association du groupe de réplication à un entrepôt de données global.
-
Modification du paramètre
ReservedMemoryPercent. -
increasing/decreasing shards/replicas Au-delà de la Min/Max capacité configurée manuellement lors de la création de la politique.
-
