Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exécution d’un retour en arrière pour un cluster de bases de données MySQL
Vous pouvez effectuer un retour en arrière pour un cluster de bases de données à un horodatage de retour en arrière spécifié. Si l’horodatage de retour en arrière n’est pas antérieur à l’heure de retour en arrière la plus ancienne possible et ne se situe pas dans le futur, le retour en arrière du cluster de bases de données est effectué à cet horodatage.
Dans le cas contraire, une erreur se produit généralement. Par ailleurs, si vous essayez d’effectuer un retour en arrière sur un cluster de bases de données pour lequel la journalisation binaire est activée, une erreur se produit généralement, sauf si vous avez choisi de forcer l’exécution du retour en arrière. Forcer un retour en arrière peut interférer avec d’autres opérations utilisant la journalisation binaire.
Important
Le retour en arrière ne génère aucune entrée binlog pour les modifications qu’il effectue. Si la journalisation binaire est activée pour le cluster de bases de données, il est possible que le retour en arrière ne soit pas compatible avec votre implémentation binlog.
Note
Pour les clones de base de données, vous ne pouvez pas effectuer un retour en arrière du cluster de bases de données à une heure antérieure à l’heure à laquelle le clone a été créé. Pour plus d’informations sur le clonage de base de données, consultez Clonage d’un volume pour un cluster de bases de données Amazon Aurora.
La procédure suivante explique comment effectuer une opération de retour en arrière pour un cluster de bases de données à l’aide de la console.
Pour effectuer une opération de retour en arrière à l’aide de la console
Connectez-vous à la console Amazon RDS Console de gestion AWS et ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Dans le panneau de navigation, choisissez Instances.
-
Choisissez l’instance principale du cluster de bases de données pour lequel vous souhaitez effectuer un retour en arrière.
-
Pour Actions, choisissez Backtrack DB cluster (Retour en arrière de cluster de bases de données).
-
Sur la page Backtrack DB cluster (Retour en arrière de cluster de bases de données), entrez l’horodatage de retour en arrière à appliquer au retour en arrière de cluster de bases de données.
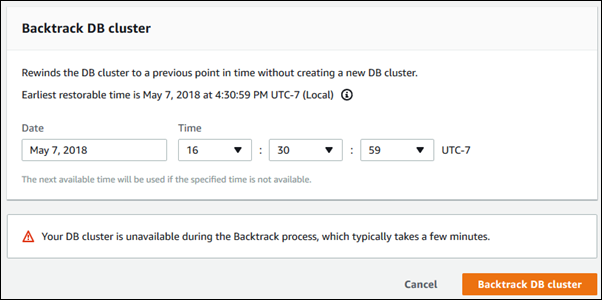
-
Choisissez Backtrack DB cluster (Retour en arrière de cluster de bases de données).
La procédure suivante explique comment effectuer un retour en arrière de cluster de bases de données à l’aide de l AWS CLI.
Pour revenir en arrière sur un cluster de bases de données à l'aide du AWS CLI
-
Appelez la commande backtrack-db-cluster AWS CLI et fournissez les valeurs suivantes :
-
--db-cluster-identifier: nom du cluster de bases de données. -
--backtrack-to: horodatage de retour en arrière de cluster de bases de données, spécifié au format ISO 8601.
L’exemple suivant effectue un retour en arrière du cluster de bases de données
sample-clusterà 10 h, le 19 mars 2018.Pour Linux, macOS ou Unix :
aws rds backtrack-db-cluster \ --db-cluster-identifier sample-cluster \ --backtrack-to 2018-03-19T10:00:00+00:00Pour Windows :
aws rds backtrack-db-cluster ^ --db-cluster-identifier sample-cluster ^ --backtrack-to 2018-03-19T10:00:00+00:00 -
Pour effectuer un retour en arrière de cluster de bases de données à l’aide de l’API Amazon RDS, utilisez l’opération BacktrackDBCluster. Cette opération effectue un retour en arrière du cluster de bases de données spécifié dans la valeur DBClusterIdentifier à l’heure spécifiée.
