Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de la réplication logique pour effectuer une mise à niveau de version majeure pour Aurora PostgreSQL
Grâce à la réplication logique et au clonage rapide Aurora, vous pouvez effectuer une mise à niveau de version majeure qui utilise la version actuelle de la base de données Aurora PostgreSQL tout en migrant progressivement les données modifiées vers la nouvelle base de données de version majeure. Ce processus de mise à niveau à faible temps d'arrêt est appelé blue/green mise à niveau. La version actuelle de la base de données est appelée l’environnement « bleu » et la nouvelle version de la base de données est appelée l’environnement « vert ».
Le clonage rapide Aurora charge entièrement les données existantes en prenant un instantané de la base de données source. Le clonage rapide utilise un protocole de copie sur écriture construit au-dessus de la couche de stockage Aurora, qui vous permet de créer un clone de la base de données en peu de temps. Cette méthode est très efficace lors de la mise à niveau d’une grande base de données.
La réplication logique dans PostgreSQL suit et transfère les modifications de vos données de l’instance initiale à une nouvelle instance fonctionnant en parallèle jusqu’à ce que vous passiez à la version la plus récente de PostgreSQL. La réplication logique s’appuie sur un modèle publier et s’abonner. Pour plus d’informations sur la réplication logique Aurora PostgreSQL, consultez Réplication avec Amazon Aurora PostgreSQL
Astuce
Vous pouvez minimiser le temps d'arrêt requis pour une mise à niveau de version majeure en utilisant la fonctionnalité de Blue/Green déploiement gérée d'Amazon RDS. Pour de plus amples informations, veuillez consulter Utilisation d' (Amazon Aurora Blue/Green Deployments) pour les mises à jour de bases de données.
Rubriques
Prérequis
Vous devez répondre aux exigences suivantes pour effectuer ce processus de mise à niveau à faible durée d’indisponibilité :
-
Vous devez disposer des autorisations rds_superuser.
-
Le cluster de bases de données Aurora PostgreSQL que vous souhaitez mettre à niveau doit exécuter une version prise en charge capable d’effectuer des mises à niveau de version majeure à l’aide de la réplication logique. Assurez-vous d’appliquer toutes les mises à jour et tous les correctifs de versions mineures à votre cluster de bases de données. La fonction
aurora_volume_logical_start_lsnutilisée dans cette technique est prise en charge dans les versions suivantes d’Aurora PostgreSQL :15.2 et versions 15 ultérieures
14.3 et versions 14 ultérieures
13.6 et versions 13 ultérieures
12.10 et versions 12 ultérieures
11.15 et versions 11 ultérieures
10.20 et versions 10 ultérieures
Pour plus d’informations sur la fonction
aurora_volume_logical_start_lsn, consultez aurora_volume_logical_start_lsn. -
Toutes vos tables doivent comporter une clé primaire ou inclure une colonne d’identité PostgreSQL
. -
Configurez le groupe de sécurité de votre VPC pour autoriser les accès entrants et sortants entre les deux clusters de bases de données Aurora PostgreSQL, anciens et nouveaux. Vous pouvez accorder l’accès à une plage spécifique de routage inter-domaines sans classe (CIDR) ou à un autre groupe de sécurité dans votre VPC ou dans un VPC homologue. (Peer VPC nécessite une connexion d’appairage de VPC).
Note
Pour obtenir des informations détaillées sur les autorisations requises pour configurer et gérer un scénario de réplication logique en cours d’exécution, consultez la documentation principale de PostgreSQL
Limitations
Lorsque vous effectuez une mise à niveau à faible durée d’indisponibilité sur votre cluster de bases de données Aurora PostgreSQL vers une nouvelle version majeure, vous utilisez la fonctionnalité de réplication logique native de PostgreSQL. Elle possède les mêmes capacités et les mêmes limites que la réplication logique de PostgreSQL. Pour plus d’informations, consultez Réplication avec Amazon Aurora PostgreSQL
-
Les commandes du langage de définition des données (DDL) ne sont pas répliquées.
-
La réplication ne prend pas en charge les modifications de schéma dans une base de données active. Le schéma est recréé dans sa forme originale au cours du processus de clonage. Si vous modifiez le schéma après le clonage, mais avant de terminer la mise à niveau, cette modification n’est pas prise en compte dans l’instance mise à niveau.
-
Les objets volumineux ne sont pas répliqués, mais vous pouvez stocker des données dans des tables normales.
-
La réplication n’est prise en charge que par les tables, y compris les tables partitionnées. La réplication vers d’autres types de relations, telles que les vues, les vues matérialisées ou les tables externes, n’est pas prise en charge.
-
Les données des séquences ne sont pas répliquées et nécessitent une mise à jour manuelle après le basculement.
Note
Cette mise à jour ne prend pas en charge le script automatique. Vous devez effectuer toutes les étapes manuellement.
Réglage et vérification des valeurs des paramètres
Avant la mise à niveau, configurez l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL pour qu’elle agisse comme un serveur de publication. L’instance doit utiliser un groupe de paramètres de cluster base de données personnalisé avec les paramètres suivants :
-
rds.logical_replication: définissez ce paramètre sur 1. Le paramètrerds.logical_replicationa la même fonction que le paramètrewal_leveld’un serveur PostgreSQL autonome et d’autres paramètres qui contrôlent la gestion du fichier journal en écriture. -
max_replication_slots: définissez ce paramètre comme le nombre total d’abonnements que vous prévoyez de créer. Si vous en utilisez AWS DMS, définissez ce paramètre sur le nombre de AWS DMS tâches que vous prévoyez d'utiliser pour la capture des données modifiées à partir de ce cluster de bases de données. -
max_wal_senders: définissez le nombre de connexions simultanées, plus quelques connexions supplémentaires, à rendre disponible pour les tâches de gestion et les nouvelles sessions. Si vous utilisez AWS DMS, le nombre de max_wal_senders doit être égal au nombre de sessions simultanées plus le nombre de AWS DMS tâches pouvant être exécutées à un moment donné. -
max_logical_replication_workers: définissez le nombre d’applications de travail de réplication logique et de synchronisation des tables que vous prévoyez. Il est généralement prudent de fixer le nombre d’applications de travail de réplication à la même valeur que celle utilisée pour max_wal_senders. Les application de travail sont extraites du groupe de processus d’arrière-plan (max_worker_processes) alloué au serveur. -
max_worker_processes: définit le nombre de processus d’arrière-plan pour le serveur. Ce nombre doit être suffisant pour allouer des applications de travail pour la réplication, les processus auto-vacuum et les autres processus de maintenance qui peuvent avoir lieu simultanément.
Lorsque vous passez à une version plus récente d’Aurora PostgreSQL, vous devez dupliquer tous les paramètres que vous avez modifiés dans la version précédente du groupe de paramètres. Ces paramètres sont appliqués à la version mise à niveau. Vous pouvez interroger la table pg_settings pour obtenir une liste des paramètres afin de les recréer sur votre nouveau cluster de bases de données Aurora PostgreSQL.
Par exemple, pour obtenir les paramètres de réplication, exécutez la requête suivante :
SELECT name, setting FROM pg_settings WHERE name in ('rds.logical_replication','max_replication_slots','max_wal_senders','max_logical_replication_workers','max_worker_processes');
Mise à niveau d’Aurora PostgreSQL vers une nouvelle version majeure
Pour préparer le serveur de publication (bleu)
-
Dans l’exemple qui suit, l’instance d’enregistreur source (bleue) est un cluster de bases de données Aurora PostgreSQL exécutant PostgreSQL version 11.15. C’est le nœud éditeur dans notre scénario de réplication. Pour cette démonstration, notre instance d’enregistreur source héberge un exemple de table qui contient une série de valeurs :
CREATE TABLEmy_table(a int PRIMARY KEY); INSERT INTOmy_tableVALUES (generate_series(1,100)); -
Pour créer une publication sur l’instance source, connectez-vous au nœud en écriture de l’instance avec psql (la CLI pour PostgreSQL) ou avec le client de votre choix). Entrez la commande suivante dans chaque base de données :
CREATE PUBLICATIONpublication_nameFOR ALL TABLES;L’élément publication_name spécifie le nom de la publication.
-
Vous devez également créer un emplacement de réplication sur l’instance. La commande suivante crée un emplacement de réplication et charge le plug-in
pgoutputde décodage logique. Le plug-in modifie le contenu lu depuis le protocole WAL (Write-Ahead Logging) vers le protocole de réplication logique, et filtre les données selon la spécification de publication. SELECT pg_create_logical_replication_slot('replication_slot_name','pgoutput');
Pour cloner le serveur de publication
-
Utilisez la console Amazon RDS pour créer un clone de l’instance source. Mettez en surbrillance le nom de l’instance dans la console Amazon RDS, puis choisissez Create clone (Créer un clone) dans le menu Actions.
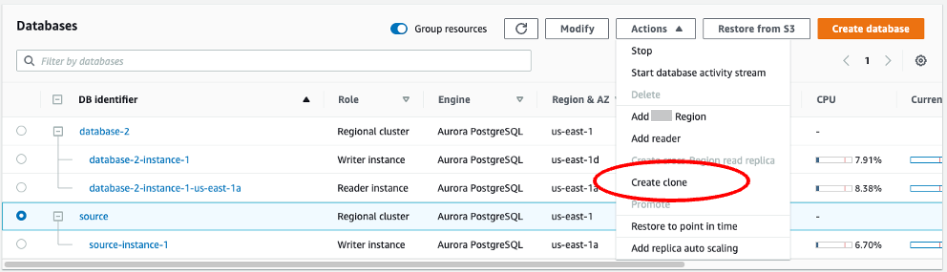
-
Entrez un nom unique pour l’instance. La plupart des paramètres sont des valeurs par défaut de l’instance source. Lorsque vous avez apporté les modifications requises pour la nouvelle instance, choisissez Create clone (Créer un clone).

-
Pendant que l’instance cible est en cours d’initialisation, la colonne Status (État) du nœud en écriture affiche Creating (Création) dans la colonne Status (État). Lorsque l’instance est prête, le statut passe à Available (Disponible).
Pour préparer le clone en vue d’une mise à niveau
-
Le clone est l’instance « verte » du modèle de déploiement. Il s’agit de l’hôte du nœud d’abonnement de réplication. Lorsque le nœud devient disponible, connectez-vous avec psql et interrogez le nouveau nœud en écriture pour obtenir le numéro de séquence du journal (LSN). Le LSN identifie le début d’un enregistrement dans le flux WAL.
SELECT aurora_volume_logical_start_lsn(); -
Dans la réponse à la requête, vous trouvez le numéro LSN. Vous aurez besoin de ce numéro plus tard dans le processus, alors notez-le quelque part.
postgres=>SELECT aurora_volume_logical_start_lsn();aurora_volume_logical_start_lsn --------------- 0/402E2F0 (1 row) -
Avant de mettre à niveau le clone, supprimez l’emplacement de réplication du clone.
SELECT pg_drop_replication_slot('replication_slot_name');
Pour mettre à niveau le cluster vers une nouvelle version majeure
-
Après avoir cloné le nœud fournisseur, utilisez la console Amazon RDS pour lancer une mise à niveau de version majeure sur le nœud d’abonnement. Mettez en surbrillance le nom de l’instance dans la console RDS, puis cliquez sur le bouton Modify (Modifier). Sélectionnez la version mise à jour et vos groupes de paramètres mis à jour, et appliquez les paramètres immédiatement pour mettre à niveau l’instance cible.
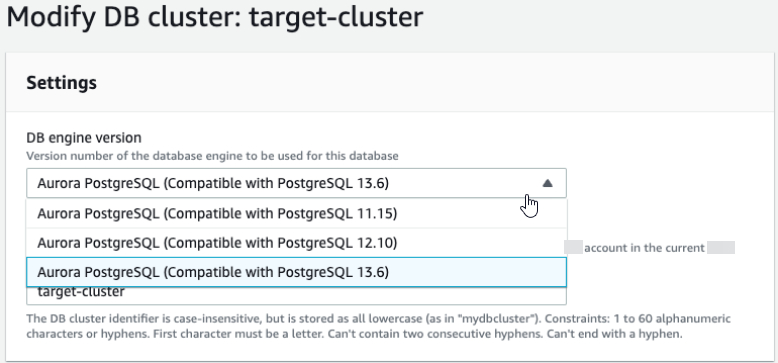
-
Vous pouvez également utiliser la CLI pour effectuer une mise à niveau :
aws rds modify-db-cluster —db-cluster-identifier $TARGET_Aurora_ID —engine-version 13.6 —allow-major-version-upgrade —apply-immediately
Pour préparer l’abonné (vert)
-
Lorsque le clone est disponible après la mise à niveau, connectez-vous à psql et définissez l’abonnement. Pour ce faire, vous devez spécifier les options suivantes dans la commande
CREATE SUBSCRIPTION:-
subscription_name: nom de l’abonnement. -
admin_user_name: nom d’un utilisateur administratif avec les autorisations rds_superuser. -
admin_user_password: mot de passe associé à l’utilisateur administratif. -
source_instance_URL: URL de l’instance du serveur de publication. -
database: base de données à laquelle le serveur d’abonnement se connectera. -
publication_name: nom du serveur de publication. -
replication_slot_name: nom de l’emplacement de réplication.
CREATE SUBSCRIPTIONsubscription_nameCONNECTION'postgres://admin_user_name:admin_user_password@source_instance_URL/database'PUBLICATIONpublication_nameWITH (copy_data = false, create_slot = false, enabled = false, connect = true, slot_name ='replication_slot_name'); -
-
Après avoir créé l’abonnement, interrogez la vue pg_replication_origin
pour récupérer la valeur roname, qui est l’identifiant de l’origine de réplication. Chaque instance possède une valeur roname:SELECT * FROM pg_replication_origin;Par exemple :
postgres=>SELECT * FROM pg_replication_origin;roident | roname ---------+---------- 1 | pg_24586 -
Fournissez le LSN que vous avez enregistré à partir de la requête précédente du nœud éditeur et la valeur
ronamerenvoyée par le nœud abonné [INSTANCE] dans la commande. Cette commande utilise la fonctionpg_replication_origin_advancepour spécifier le point de départ de la séquence de journaux pour la réplication.SELECT pg_replication_origin_advance('roname','log_sequence_number');ronameest l’identifiant renvoyé par la vue pg_replication_origin.log_sequence_numberest la valeur renvoyée par la requête précédente de la fonctionaurora_volume_logical_start_lsn. -
Utilisez ensuite la clause
ALTER SUBSCRIPTION... ENABLEpour activer la réplication logique.ALTER SUBSCRIPTIONsubscription_nameENABLE; -
À ce stade, vous pouvez confirmer que la réplication fonctionne. Ajoutez une valeur à l’instance de publication, puis confirmez que la valeur est répliquée vers le nœud d’abonnement.
Ensuite, utilisez la commande suivante pour surveiller le retard de réplication sur le nœud éditeur :
SELECT now() AS CURRENT_TIME, slot_name, active, active_pid, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS diff_size, pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) AS diff_bytes FROM pg_replication_slots WHERE slot_type = 'logical';Par exemple :
postgres=>SELECT now() AS CURRENT_TIME, slot_name, active, active_pid, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS diff_size, pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) AS diff_bytes FROM pg_replication_slots WHERE slot_type = 'logical';current_time | slot_name | active | active_pid | diff_size | diff_bytes -------------------------------+-----------------------+--------+------------+-----------+------------ 2022-04-13 15:11:00.243401+00 | replication_slot_name | t | 21854 | 136 bytes | 136 (1 row)Vous pouvez contrôler le délai de réplication à l’aide des valeurs
diff_sizeetdiff_bytes. Lorsque ces valeurs atteignent 0, le réplica a rattrapé l’instance de base de données source.
Exécution des tâches après la mise à niveau
Lorsque la mise à niveau est terminée, l’état de l’instance s’affiche comme Available (Disponible) dans la colonne Status (État) du tableau de bord de la console. Sur la nouvelle instance, nous vous recommandons de procéder comme suit :
-
Redirigez vos applications pour qu’elles pointent vers le nœud en écriture.
-
Ajoutez des nœuds en lecture pour gérer la charge de travail et assurer une haute disponibilité en cas de problème avec le nœud en écriture.
-
Les clusters de bases de données Aurora PostgreSQL nécessitent parfois des mises à jour du système d’exploitation. Ces mises à jour peuvent inclure une version plus récente de la bibliothèque glibc. Lors de ces mises à jour, nous vous recommandons de suivre les directives décrites dans Collations prises en charge dans Aurora PostgreSQL RDS pour .
-
Mettez à jour les autorisations des utilisateurs sur la nouvelle instance pour garantir l’accès.
Après avoir testé votre application et vos données sur la nouvelle instance, nous vous recommandons de faire une dernière sauvegarde de votre instance initiale avant de la supprimer. Pour plus d’informations sur l’utilisation de la réplication logique sur un hôte Aurora, consultez Configuration de la réplication logique pour votre cluster de bases de données Aurora PostgreSQL.
