Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
io/aurora_redo_log_flush
L'événement io/aurora_redo_log_flush se produit lorsqu'une session écrit des données persistantes sur un stockage Amazon Aurora.
Rubriques
Versions de moteur prises en charge
Ces informations relatives aux événements d'attente sont prises en charge pour les versions de moteur suivantes :
-
Aurora MySQL version 2
Contexte
L'événement io/aurora_redo_log_flush est destiné à une opération d'entrée/sortie (I/O) dans Aurora MySQL.
Note
Dans Aurora MySQL version 3, cet événement d'attente est nommé io/redo_log_flush.
Causes probables de l'allongement des temps d'attente
Pour assurer la persistance des données, les validations nécessitent une écriture durable dans un stockage stable. Si la base de données effectue trop de validations, un événement d'attente se produit lors de l'opération I/O en écriture, l'événement d'attente io/aurora_redo_log_flush.
Dans les exemples suivants, 50 000 enregistrements sont insérés dans un cluster de base de données Aurora MySQL à l'aide de la classe d'instance de base de données db.r5.xlarge :
-
Dans le premier exemple, chaque session insère 10 000 enregistrements ligne par ligne. Par défaut, en l'absence de commande de langage de manipulation de données (DML) dans une transaction, Aurora MySQL utilise des validations implicites. La validation automatique est activée. Cela signifie qu'une validation accompagne chaque insertion de ligne. Performance Insights montre que les connexions passent l'essentiel de leur temps à attendre sur l'événement d'attente
io/aurora_redo_log_flush.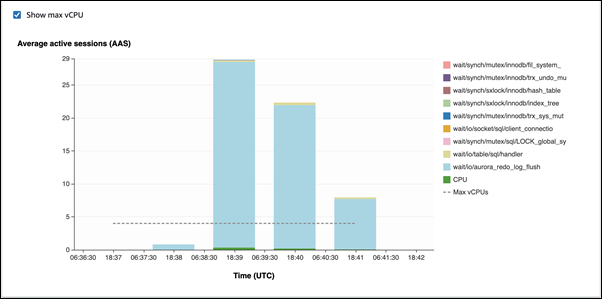
Cela est dû aux simples instructions d'insertion utilisées.
L'insertion des 50 000 enregistrements requiert 3,5 minutes.
-
Dans le deuxième exemple, les insertions sont réalisées par lots de 1 000 lots, ce qui signifie que chaque connexion effectue 10 validations au lieu de 10 000. Performance Insights montre que les connexions ne passent pas l'essentiel de leur temps à attendre sur l'événement d'attente
io/aurora_redo_log_flush.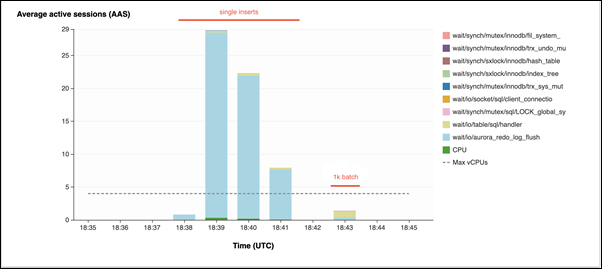
L'insertion des 50 000 enregistrements requiert 4 secondes.
Actions
Nous recommandons différentes actions selon les causes de l'événement d'attente.
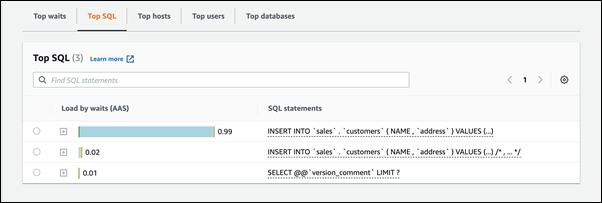
Identifier les sessions et requêtes problématiques
Si votre instance de base de données se heure à un goulet d'étranglement, votre première tâche consiste à rechercher les sessions et les requêtes qui en sont à l'origine. Pour un billet de blog AWS Database particulièrement utile, consultez Analyze Amazon Aurora MySQL Workloads with Performance Insights
Pour identifier les sessions et les requêtes à l'origine d'un goulet d'étranglement
Connectez-vous à la AWS Management Console et ouvrez la console Amazon RDS à l'adresse https://console.aws.amazon.com/rds/
. -
Dans le volet de navigation, choisissez Performance Insights.
-
Sélectionnez votre instance DB.
-
Dans Database load (Charge de base de données), choisissez Slice by wait (Tranche par attente).
-
Au bas de la page, choisissez Top SQL (Principaux éléments SQL).
Les requêtes situées en haut de la liste imposent la charge la plus élevée sur la base de données.
Regrouper vos opérations d'écriture
Les exemples suivants déclenchent l'événement d'attente io/aurora_redo_log_flush. (La validation automatique est activée.)
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
Pour réduire le temps passé à attendre sur l'événement d'attente io/aurora_redo_log_flush, regroupez logiquement vos opérations d'écriture dans une seule validation et limitez ainsi les appels persistants vers le stockage.
Désactiver la validation automatique
Désactivez la validation automatique avant d'effectuer d'importantes modifications en dehors d'une transaction, comme le montre l'exemple suivant.
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
Utiliser des transactions
Vous pouvez utiliser des transactions comme le montre l'exemple suivant.
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
Utiliser des lots
Vous pouvez apporter des modifications par lots, comme le montre l'exemple suivant. Cependant, l'utilisation de lots trop volumineux peut entraîner des problèmes de performances, en particulier lors de la lecture des répliques ou lors de la point-in-time restauration (PITR).
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;
