Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillance d'une base de données globale Amazon Aurora
Lorsque vous créez les clusters de bases de données Aurora qui composent votre base de données Aurora globale, vous pouvez choisir de nombreuses options qui vous permettent de surveiller leurs performances. Les options disponibles sont les suivantes :
Amazon RDS Performance Insights : active le schéma de performance dans le moteur de base de données Aurora sous-jacent. Pour en savoir plus sur Performance Insights et les bases de données Aurora globales, consultez Surveillance d'une base de données mondiale Amazon Aurora avec Amazon RDS Performance Insights.
Surveillance améliorée — Génère des métriques pour l'utilisation des processus ou des threads sur leCPU. Pour en savoir plus sur la surveillance améliorée, consultez Surveillance des métriques du système d'exploitation à l'aide de la Surveillance améliorée.
Amazon CloudWatch Logs — Publie les types de journaux spécifiés dans CloudWatch Logs. Les journaux d'erreurs sont publiés par défaut, mais vous pouvez choisir d'autres journaux spécifiques à votre moteur de base de données Aurora.
Pour les clusters de base SQL de données Aurora basés sur Aurora My, vous pouvez exporter le journal d'audit, le journal général et le journal des requêtes lentes.
Pour les clusters de base de SQL données Aurora basés sur Aurora Postgre, vous pouvez exporter le journal SQL Postgre.
Pour les bases de données globales SQL basées sur Aurora My, vous pouvez interroger des
information_schematables spécifiques pour vérifier l'état de votre base de données globale Aurora et de ses instances. Pour savoir comment procéder, veuillez consulter la section Surveillance des bases de données globales SQL basées sur Aurora My.Pour les bases de données globales SQL basées sur Aurora Postgre, vous pouvez utiliser des fonctions spécifiques pour vérifier l'état de votre base de données globale Aurora et de ses instances. Pour savoir comment procéder, consultez Surveillance des bases de données globales SQL basées sur Aurora Postgre.
La capture d'écran suivante montre certaines des options disponibles sous l'onglet Surveillance d'un cluster de base de données Aurora principal dans une base de données Aurora globale.
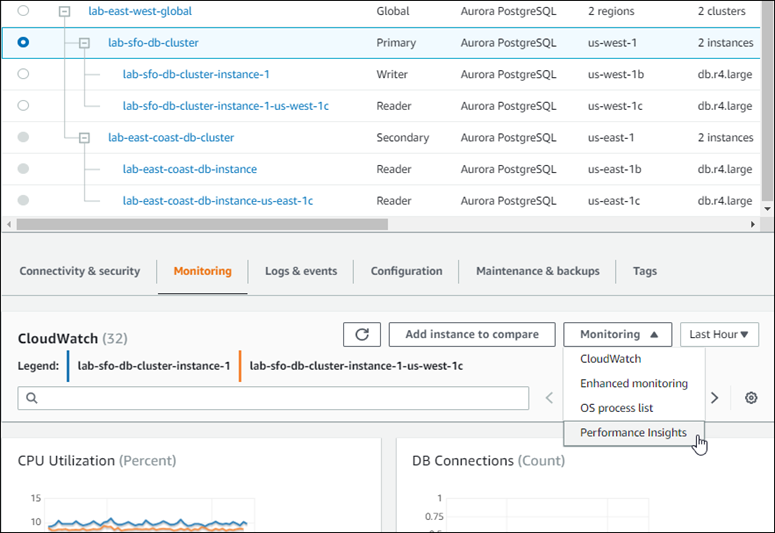
Pour de plus amples informations, veuillez consulter Surveillance des métriques d'un cluster de bases de données Amazon Aurora.
Surveillance d'une base de données mondiale Amazon Aurora avec Amazon RDS Performance Insights
Vous pouvez utiliser Amazon RDS Performance Insights pour vos bases de données globales Aurora. Vous activez cette fonctionnalité à l'échelle individuelle, pour chaque cluster de base de données Aurora de votre base de données Aurora globale. Pour ce faire, Sélectionnez Activer Performance Insights dans la section Configuration supplémentaire de la page Créer une base de données. Vous pouvez également modifier vos clusters de bases de données Aurora pour utiliser cette fonctionnalité une fois qu'ils sont opérationnels. Vous pouvez activer ou désactiver Performance Insights pour chaque cluster qui fait partie de la base de données Aurora globale.
Les rapports créés par Performance Insights s'appliquent à chaque cluster de la base de données globale. Lorsque vous ajoutez un nouveau secondaire Région AWS à une base de données globale Aurora qui utilise déjà Performance Insights, assurez-vous d'activer Performance Insights dans le cluster récemment ajouté. Elle n'hérite pas du paramètre Performance Insights de la base de données globale existante.
Vous pouvez changer Régions AWS tout en consultant la page Performance Insights d'une instance de base de données attachée à une base de données globale. Cependant, il se peut que vous ne voyiez pas les informations de performance immédiatement après le changement Régions AWS. Bien que les instances de base de données puissent avoir des noms identiques dans chacune d'entre elles Région AWS, les Performances Insights associées URL sont différentes pour chaque instance de base de données. Après le changement Régions AWS, choisissez à nouveau le nom de l'instance de base de données dans le volet de navigation Performance Insights.
Pour les instances de base de données associées à une base de données globale, les facteurs affectant les performances peuvent être différents dans chaque Région AWS. Par exemple, les instances de base de données de chacune Région AWS peuvent avoir une capacité différente.
Pour plus d'informations sur l'utilisation de Performance Insights, consultez Surveillance de la charge de base de données avec Performance Insights sur Amazon Aurora.
Surveillance des bases de données mondiales d'Aurora grâce aux flux d'activité des bases de données
En utilisant la fonction de flux d'activité de base de données, vous pouvez surveiller et définir des alarmes pour auditer l'activité dans les clusters de bases de données de votre base de données globale. Vous démarrez un flux d'activité de base de données sur chaque cluster de base de données séparément. Chaque cluster fournit des données d'audit à son propre flux Kinesis au sein de sa propre Région AWS. Pour de plus amples informations, veuillez consulter Surveillance d'Amazon Aurora à l'aide des flux d'activité de base de données.
Surveillance des bases de données globales SQL basées sur Aurora My
Pour consulter l'état d'une base de données globale SQL basée sur Aurora My, interrogez les information_schema.aurora_global_db_instance_status tables information_schema.aurora_global_db_status et.
Note
Les information_schema.aurora_global_db_instance_status tables information_schema.aurora_global_db_status et ne sont disponibles qu'avec les bases de données globales Aurora My SQL version 3.04.0 et supérieures.
Pour surveiller une base de données globale SQL basée sur Aurora My
-
Connectez-vous au point de terminaison du cluster principal de la base de données globale à l'aide d'un SQL client My. Pour plus d'informations sur la connexion, veuillez consulter Connexion à la base de données mondiale Amazon Aurora.
-
Interrogez la table
information_schema.aurora_global_db_statusdans une commande mysql pour répertorier les volumes principal et secondaire. Cette requête renvoie les temps de retard des clusters de bases de données secondaires de la base de données globale, comme dans l'exemple suivant.mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)La sortie inclut une ligne pour chaque cluster de base de données de la base de données globale contenant les colonnes suivantes :
-
AWS_REGION— Le cluster de base de données dans Région AWS lequel se trouve ce cluster de base de données. Pour la liste des tables Régions AWS par moteur, voirDisponibilité dans les Régions.
-
HIGHEST_ LSN _ WRITTEN — Le numéro de séquence de journal (LSN) le plus élevé actuellement écrit sur ce cluster de base de données.
Un numéro de séquence de journal (LSN) est un numéro séquentiel unique qui identifie un enregistrement dans le journal des transactions de la base de données. LSNssont ordonnés de telle sorte qu'un montant plus élevé LSN représente une transaction ultérieure.
-
DURABILITY_ LAG _IN_ MILLISECONDS — Différence entre les valeurs d'horodatage entre celles d'un cluster de
HIGHEST_LSN_WRITTENbase de données secondaire et celles du cluster deHIGHEST_LSN_WRITTENbase de données principal. Cette valeur est toujours égale à 0 sur le cluster de base de données principal de la base de données globale Aurora. -
RPO_ LAG _IN_ MILLISECONDS — Le décalage entre l'objectif du point de récupération (RPO). Le RPO décalage est le temps nécessaire pour que la transaction COMMIT utilisateur la plus récente soit stockée sur un cluster de base de données secondaire après avoir été stockée sur le cluster de base de données principal de la base de données globale Aurora. Cette valeur est toujours égale à 0 sur le cluster de base de données principal de la base de données globale Aurora.
En termes simples, cette métrique calcule l'objectif du point de restauration pour chaque cluster Aurora My SQL DB de la base de données globale Aurora, c'est-à-dire la quantité de données susceptible d'être perdue en cas de panne. Comme pour le décalage, RPO il se mesure dans le temps.
-
LAST_ LAG _ CALCULATION _ TIMESTAMP — L'horodatage qui indique quand les dernières valeurs ont été calculées pour
DURABILITY_LAG_IN_MILLISECONDSet.RPO_LAG_IN_MILLISECONDSUne valeur temporelle telle que1970-01-01 00:00:00+00signifie qu'il s'agit du cluster de base de données principal. -
OLDEST_ _ READ VIEW _ TRX _ID — L'ID de la plus ancienne transaction vers laquelle l'instance de base de données du rédacteur peut effectuer une purge.
-
-
Interrogez la table
information_schema.aurora_global_db_instance_statuspour répertorier toutes les instances de base de données secondaires pour le cluster de base de données principal et les clusters de bases de données secondaires.mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)La sortie inclut une ligne pour chaque instance de base de données de la base de données globale contenant les colonnes suivantes :
-
SERVER_ID — Identifiant du serveur pour l'instance de base de données.
-
SESSION_ID — Identifiant unique pour la session en cours. La valeur
MASTER_SESSION_IDidentifie l'instance de base de données d'enregistreur (principale). -
AWS_REGION— Le dans Région AWS lequel se trouve cette instance de base de données. Pour la liste des tables Régions AWS par moteur, voirDisponibilité dans les Régions.
-
DURABLE_ LSN — Ils LSN sont durables lors du stockage.
-
HIGHEST_ LSN _ RECEIVED — Le montant le plus élevé LSN reçu par l'instance de base de données de la part de l'instance de base de données du rédacteur.
-
OLDEST_ _ READ VIEW _ TRX _ID — L'ID de la plus ancienne transaction vers laquelle l'instance de base de données du rédacteur peut effectuer une purge.
-
OLDEST_ READ _ VIEW _ LSN — La plus ancienne LSN utilisée par l'instance de base de données pour lire depuis le stockage.
-
VISIBILITY_ LAG _IN_ MSEC — Pour les lecteurs du cluster de base de données principal, dans quelle mesure cette instance de base de données est en retard par rapport à l'instance de base de données d'écriture en millisecondes. Pour les lecteurs dans un cluster de base de données secondaire, retard accumulé par cette instance de base de données par rapport au volume secondaire en millisecondes.
-
Pour voir comment ces valeurs changent au fil du temps, examinez le bloc de transaction suivant où une insertion de table prend une heure.
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
Dans certains cas, une déconnexion réseau peut se produire entre le cluster de base de données principal et le cluster de base de données secondaire après l'instruction BEGIN. Si tel est le cas, la MILLISECONDS valeur DURABILITY_ LAG _IN_ du cluster de base de données secondaire commence à augmenter. À la fin de l'INSERTinstruction, la MILLISECONDS valeur DURABILITY_ LAG _IN_ est de 1 heure. Cependant, la MILLISECONDS valeur RPO_ LAG _IN_ est 0 car toutes les données utilisateur validées entre le cluster de base de données principal et le cluster de base de données secondaire sont toujours les mêmes. Dès que l'COMMITinstruction est terminée, la MILLISECONDS valeur RPO_ LAG _IN_ augmente.
Surveillance des bases de données globales SQL basées sur Aurora Postgre
Pour consulter l'état d'une base de données globale SQL basée sur Aurora Postgre, utilisez les aurora_global_db_instance_status fonctions aurora_global_db_status et.
Note
Seule Aurora Postgre SQL prend en charge les aurora_global_db_instance_status fonctions aurora_global_db_status et.
Pour surveiller une base de données globale SQL basée sur Aurora Postgre
-
Connectez-vous au point de terminaison du cluster principal de la base de données globale à l'aide d'un SQL utilitaire Postgre tel que psql. Pour plus d'informations sur la connexion, veuillez consulter Connexion à la base de données mondiale Amazon Aurora.
-
Utilisez la fonction
aurora_global_db_statusd'une commande psql pour répertorier les volumes primaire et secondaire. Ceci affiche les temps de latence des clusters de base de données secondaires de la base de données globale.postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)La sortie inclut une ligne pour chaque cluster de base de données de la base de données globale contenant les colonnes suivantes :
-
aws_region — Le cluster de base de données dans Région AWS lequel se trouve ce cluster de base de données. Pour la liste des tables Régions AWS par moteur, voirDisponibilité dans les Régions.
-
highest_lsn_written — Le numéro de séquence de journal le plus élevé (LSN) actuellement écrit sur ce cluster de base de données.
Un numéro de séquence de journal (LSN) est un numéro séquentiel unique qui identifie un enregistrement dans le journal des transactions de la base de données. LSNssont ordonnés de telle sorte qu'un montant plus élevé LSN représente une transaction ultérieure.
-
durability_lag_in_msec – Différence d'horodatage entre le numéro de séquence de journal le plus élevé écrit sur un cluster de base de données secondaire (
highest_lsn_written) et lehighest_lsn_writtensur le cluster de base de données principal. -
rpo_lag_in_msec — Le décalage de l'objectif du point de récupération (). RPO Cette latence correspond à la différence de temps entre la validation de transaction utilisateur la plus récente stockée sur un cluster de base de données secondaire et la validation de transaction utilisateur la plus récente stockée sur le cluster de base de données principal.
-
last_lag_calculation_time – Horodatage lors du dernier calcul des valeurs pour
durability_lag_in_msecetrpo_lag_in_msec. -
feedback_epoch – Époque utilisée par un cluster de base de données secondaire lorsqu'il génère des informations de veille à chaud.
On appelle veille à chaud le moment où un cluster de base de données peut se connecter et interroger pendant que le serveur est en mode de récupération ou veille. Les commentaires de veille à chaud sont des informations sur le cluster de base de données lorsqu'il est en veille à chaud. Pour plus d'informations, consultez Hot standby
dans la SQL documentation Postgre. -
feedback_xmin – ID de transaction actif minimum (le plus ancien) utilisé par un cluster de base de données secondaire.
-
-
Utilisez la fonction
aurora_global_db_instance_statuspour répertorier toutes les instances de base de données secondaires pour le cluster de base de données principal et les clusters de base de données secondaires.postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)La sortie inclut une ligne pour chaque instance de base de données de la base de données globale contenant les colonnes suivantes :
-
server_id – Identificateur du serveur pour l'instance de base de données.
-
session_id – Identificateur unique pour la session en cours.
-
aws_region — L'instance de base de données dans Région AWS laquelle se trouve cette instance de base de données. Pour la liste des tables Régions AWS par moteur, voirDisponibilité dans les Régions.
-
durable_lsn — Le LSN rendu durable lors du stockage.
-
highest_lsn_rcvd — Le montant le plus élevé LSN reçu par l'instance de base de données de la part de l'instance de base de données du rédacteur.
-
feedback_epoch – L'époque utilisée par l'instance de base de données lorsqu'elle génère des informations de veille à chaud.
On appelle veille à chaud le moment où une instance de base de données peut se connecter et interroger pendant que le serveur est en mode de récupération ou veille. Les commentaires de veille à chaud sont des informations sur l'instance de base de données lorsqu'elle est en veille à chaud. Pour plus d'informations, consultez la SQL documentation Postgre sur Hot standby
. -
feedback_xmin – ID de transaction actif minimum (le plus ancien) utilisé par l'instance de base de données.
-
oldest_read_view_lsn — Le plus ancien LSN utilisé par l'instance de base de données pour lire depuis le stockage.
-
visibility_lag_in_msec – Quelle est la latence de cette instance de base de données par rapport à l'instance de base de données rédacteur.
-
Pour voir comment ces valeurs changent au fil du temps, examinez le bloc de transaction suivant où une insertion de table prend une heure.
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;Dans certains cas, une déconnexion réseau peut se produire entre le cluster de base de données principal et le cluster de base de données secondaire après l'instruction BEGIN. Si c'est le cas, la valeur durability_lag_in_msec du cluster de base de données secondaire commence à augmenter. À la fin de l'instruction INSERT, la valeur durability_lag_in_msec est 1 heure. Toutefois, la valeur rpo_lag_in_msec est 0, car toutes les données utilisateur validées entre le cluster de base de données principal et le cluster de base de données secondaire sont encore les mêmes. Dès que l'instruction COMMIT est terminée, la valeur rpo_lag_in_msec augmente.
