Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Multi-AZ Déploiements de clusters de bases de données pour Amazon RDS
Le déploiement d'un Multi-AZ cluster de bases de données est un mode de déploiement semi-synchrone à haute disponibilité d'Amazon RDS avec deux instances de base de données répliques lisibles. Un Multi-AZ cluster de base de données possède une instance de base de données d'écriture et deux instances de base de données de lecteur réparties dans trois zones de disponibilité distinctes Région AWS. Multi-AZ Les clusters de base de données offrent une haute disponibilité, une capacité accrue pour les charges de travail de lecture et une latence d'écriture plus faible par rapport aux déploiements d' Multi-AZ instances de base de données.
Vous pouvez importer des données d'une base de données locale vers un Multi-AZ cluster de bases de données en suivant les instructions de. Importation de données vers une base de données Amazon RDS for MySQL avec une durée d’indisponibilité réduite
Vous pouvez acheter des instances de base de données réservées pour un Multi-AZ cluster de base de données. Pour de plus amples informations, veuillez consulter Instances de base de données réservées pour un cluster de Multi-AZ bases de données.
La disponibilité et la prise en charge des fonctionnalités varient selon les versions spécifiques de chaque moteur de base de données, et selon les Régions AWS. Pour plus d'informations sur la version et la disponibilité par région d'Amazon RDS avec des clusters de Multi-AZ base de données, consultezRégions et moteurs de base de données pris en charge pour les clusters de Multi-AZ bases de données dans Amazon RDS.
Rubriques
Disponibilité des classes d'instance pour les clusters de Multi-AZ bases de données
Groupes de paramètres pour les clusters de Multi-AZ bases de données
Retard de réplication et clusters de Multi-AZ bases de données
Création d'un Multi-AZ cluster de base de données pour Amazon RDS
Connexion à un Multi-AZ cluster de base de données pour Amazon RDS
Modification d'un Multi-AZ cluster de base de données pour Amazon RDS
Mise à niveau de la version du moteur d'un Multi-AZ cluster de base de données pour Amazon RDS
Modification du nom d'un Multi-AZ cluster de base de données pour Amazon RDS
Défaillance d'un Multi-AZ cluster de base de données pour Amazon RDS
Utilisation des répliques de lecture de clusters de Multi-AZ bases de données pour Amazon RDS
Suppression d'un Multi-AZ cluster de base de données pour Amazon RDS
Limites des clusters de Multi-AZ bases de données pour Amazon RDS
Important
Multi-AZ Les clusters de base de données ne sont pas les mêmes que les clusters de base de données Aurora. Pour en savoir plus sur les clusters de base de données Aurora, consultez le Guide de l'utilisateur Amazon Aurora.
Disponibilité des classes d'instance pour les clusters de Multi-AZ bases de données
Multi-AZ Les déploiements de clusters de bases de données sont pris en charge pour les classes d'instances de base de données suivantes : db.c6gd db.m5d db.m6gd db.m6id db.m6idn db.m8gddb.r5d,,db.r6gd,db.r6id,db.r6idn,db.r8gd, etdb.x2iedn.
Note
Les classes d’instance c6gd sont les seules à prendre en charge la taille de l’instance medium.
Pour plus d’informations sur les classes d’instance de base de données, consultez Classes d'instances de base de données.
Multi-AZ Architecture de cluster de bases de données
Avec un Multi-AZ cluster de base de données, Amazon RDS réplique les données de l'instance de base de données du rédacteur vers les deux instances de base de données du lecteur en utilisant les capacités de réplication natives du moteur de base de données. Lorsqu'une modification est apportée à l'instance de base de données d'écriture, elle est transmise à chaque instance de base de données de lecture.
Multi-AZ Les déploiements de clusters de bases de données utilisent la réplication semi-synchrone, qui nécessite un accusé de réception d'au moins une instance de base de données de lecteur pour qu'une modification soit validée. Il n'est pas nécessaire de confirmer que les événements ont été entièrement exécutés et validés sur tous les réplicas.
Les instances de base de données d'écriture font office de cibles de basculement automatique et traitent également le trafic en lecture pour accroître le débit de lecture des applications. En cas de panne sur votre instance de base de données de rédacteur, RDS gère laquelle des instances de base de données de lecteur devient la cible de basculement. RDS procède en fonction de l'instance de base de données de lecteur qui a l'enregistrement de changement le plus récent.
Le schéma suivant montre un Multi-AZ cluster de base de données.
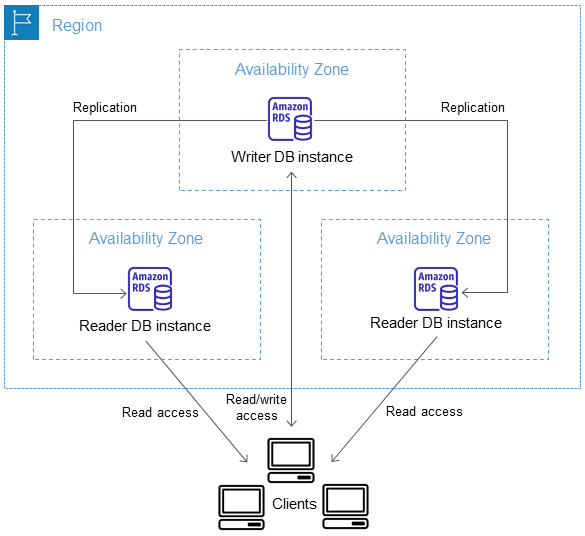
Multi-AZ Les clusters de base de données ont généralement une latence d'écriture inférieure à celle des déploiements d' Multi-AZ instances de base de données. Ils permettent également d'exécuter des charges de travail en lecture seule sur des instances de base de données de lecteurs. La console RDS affiche la zone de disponibilité de l'instance de base de données d'écriture et les zones de disponibilité des instances de base de données de lecture. Vous pouvez également utiliser la commande CLI describe-db-clusters ou l'opération d'API DescribeDBClusters pour rechercher ces informations.
Important
Pour éviter les erreurs de réplication dans les clusters de bases de données RDS for Multi-AZ MySQL, nous recommandons vivement que toutes les tables possèdent une clé primaire.
Groupes de paramètres pour les clusters de Multi-AZ bases de données
Dans un Multi-AZ cluster de base de données, un groupe de paramètres de cluster de base de données agit comme un conteneur pour les valeurs de configuration du moteur qui sont appliquées à chaque instance de base de données du Multi-AZ cluster de base de données.
Dans un Multi-AZ cluster de base de données, un groupe de paramètres de base de données est défini sur le groupe de paramètres de base de données par défaut pour le moteur de base de données et la version du moteur de base de données. Les paramètres du groupe de paramètres de cluster de base de données s'appliquent à toutes les instances de base de données du cluster.
Pour plus d’informations sur les groupes de paramètres, consultez Utilisation des groupes de paramètres de cluster de base de Multi-AZ données pour les clusters de base de données.
Proxy RDS avec clusters de Multi-AZ base de données
Vous pouvez utiliser Amazon RDS Proxy pour créer un proxy pour vos clusters de Multi-AZ bases de données. En utilisant RDS Proxy, vos applications peuvent grouper et partager des connexions de bases de données pour améliorer leur capacité de mise à l’échelle. Chaque proxy effectue le multiplexage de connexion, également connu sous le nom de réutilisation de connexion. Grâce au multiplexage, RDS Proxy exécute toutes les opérations d’une transaction à l’aide d’une connexion de base de données sous-jacente. Le proxy RDS peut également réduire à une seconde ou moins le temps d'arrêt lié à une mise à niveau de version mineure d'un Multi-AZ cluster de base de données. Pour plus d'informations sur les avantages de RDS Proxy, consultez Proxy Amazon RDS.
Pour configurer un proxy pour un Multi-AZ cluster de base de données, choisissez Create an RDS Proxy lors de la création du cluster. Pour obtenir des instructions sur la création et la gestion des points de terminaison RDS Proxy, consultez Utilisation des points de terminaison du proxy Amazon RDS.
Retard de réplication et clusters de Multi-AZ bases de données
Le retard de réplica est la différence de temps entre la dernière transaction au niveau de l'instance de base de données d'enregistreur et la dernière transaction appliquée sur une instance de base de données de lecteur. La CloudWatch métrique Amazon ReplicaLag représente ce décalage horaire. Pour plus d'informations sur CloudWatch les métriques, consultezContrôle Amazon RDS statistiques avec Amazon CloudWatch.
Bien que Multi-AZ les clusters de base de données permettent des performances d'écriture élevées, un retard de réplication peut toujours se produire en raison de la nature de la réplication basée sur le moteur. Étant donné que tout basculement doit d'abord résoudre le retard du réplica avant de promouvoir une nouvelle instance de base de données d'enregistreur, la surveillance et la gestion de ce retard de réplica sont à prendre en compte.
Pour les clusters de base de données RDS pour Multi-AZ MySQL, le temps de basculement dépend du délai de réplication des deux instances de base de données de lecteur restantes. Les deux instances de base de données de lecteur doivent appliquer des transactions non appliquées avant que l'une d'elles ne soit promue vers la nouvelle instance de base de données de rédacteur.
Pour les clusters de base de données RDS pour Multi-AZ PostgreSQL, le temps de basculement dépend du délai de réplication le plus faible des deux instances de base de données de lecteur restantes. L'instance de base de données de lecteur ayant le plus faible décalage de réplica doit appliquer les transactions non appliquées avant d'être promue en tant que nouvelle instance de base de données de rédacteur.
Pour consulter un didacticiel expliquant comment créer une CloudWatch alarme lorsque le délai de réplication dépasse une durée définie, voirTutoriel : Création d'une CloudWatch alarme Amazon pour le retard de réplication du Multi-AZ cluster de bases de données pour Amazon RDS.
Causes courantes du retard de réplica
En général, le retard de réplica se produit lorsque la charge de travail en écriture est trop élevée pour que les instances de base de données du lecteur puissent appliquer efficacement les transactions. Diverses charges de travail peuvent entraîner un retard de réplica temporaire ou continu. Voici quelques exemples de causes courantes :
-
Une concurrence d'écriture élevée ou une mise à jour par lots lourde sur l'instance de base de données de l'enregistreur, ce qui entraîne un retard du processus d'application sur les instances de base de données du lecteur.
-
Une charge de travail de lecture lourde qui utilise des ressources sur une ou plusieurs instances de base de données du lecteur. L'exécution de requêtes lentes ou volumineuses peut affecter le processus d'application et entraîner un retard de réplica.
-
Les transactions qui modifient de grandes quantités de données ou d'instructions DDL peuvent parfois entraîner une augmentation temporaire du retard de réplica, car la base de données doit préserver l'ordre de validation.
Atténuation du retard de réplica
Pour les clusters de Multi-AZ bases de données pour RDS pour MySQL et RDS pour PostgreSQL, vous pouvez atténuer le délai de réplication en réduisant la charge sur votre instance de base de données d'écriture. Vous pouvez également utiliser le contrôle de flux pour réduire le décalage de réplica. Le contrôle de flux fonctionne en limitant les écritures sur l'instance de base de données d'enregistreur, ce qui garantit que le retard de réplica ne continue pas à augmenter sans limite. La limitation des écritures est obtenue en ajoutant un délai à la fin d'une transaction, ce qui réduit le débit d'écriture sur l'instance de base de données d'enregistreur. Bien que le contrôle de flux ne garantit pas l'élimination du retard, il peut contribuer à réduire le retard global pour de nombreuses charges de travail. Les sections suivantes fournissent des informations sur l’utilisation du contrôle de flux avec RDS for MySQL et RDS pour PostgreSQL.
Atténuation du décalage de réplica avec le contrôle de flux pour RDS for MySQL
Lorsque vous utilisez RDS pour des clusters de bases de Multi-AZ données MySQL, le contrôle de flux est activé par défaut à l'aide du paramètre rpl_semi_sync_master_target_apply_lag dynamique. Ce paramètre spécifie la limite supérieure souhaitée pour le décalage du réplica. À mesure que le décalage de réplica approche cette limite configurée, le contrôle de flux limite les transactions d’écriture sur l’instance de base de données de rédacteur pour tenter de contenir le décalage du réplica en dessous de la valeur spécifiée. Dans certains cas, le décalage de réplica peut dépasser la limite spécifiée. Par défaut, ce paramètre est défini à 120 secondes. Pour désactiver le contrôle de flux, définissez ce paramètre sur sa valeur maximale de 86 400 secondes (un jour).
Pour afficher le délai de courant injecté par le contrôle de flux, affichez le paramètre Rpl_semi_sync_master_flow_control_current_delay en exécutant la requête suivante.
SHOW GLOBAL STATUS like '%flow_control%';
Votre sortie doit ressembler à ce qui suit :
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)Note
Le délai est affiché en microsecondes.
Lorsque Performance Insights est activé pour un cluster de base de données RDS pour Multi-AZ MySQL, vous pouvez surveiller l'événement d'attente correspondant à une instruction SQL indiquant que les requêtes ont été retardées par un contrôle de flux. Lorsqu'un délai a été introduit par un contrôle de flux, vous pouvez afficher l'événement d'attente /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond correspondant à l'instruction SQL du tableau de bord Performance Insights. Pour afficher ces métriques, assurez-vous que le schéma de performances est activé. Pour plus d’informations sur Performance Insights, consultez Surveillance de la charge de base de données avec Performance Insights sur Amazon RDS.
Atténuation du décalage de réplica avec le contrôle de flux pour RDS pour PostgreSQL
Lorsque vous utilisez RDS pour des clusters de bases de données Multi-AZ PostgreSQL, le contrôle de flux est déployé sous forme d'extension. Il active un processus de travail en arrière-plan pour toutes les instances de base de données du cluster de base de données. Par défaut, les processus de travail en arrière-plan sur les instances de base de données de lecteur communiquent le retard actuel du réplica avec le processus de travail en arrière-plan sur l'instance de base de données d'enregistreur. Si le retard dépasse deux minutes sur n'importe quelle instance de base de données de lecteur, le processus de travail en arrière-plan de l'instance de base de données d'enregistreur ajoute un délai à la fin d'une transaction. Pour contrôler le seuil de retard, utilisez le paramètre flow_control.target_standby_apply_lag.
Lorsqu'un contrôle de flux limite un processus PostgreSQL, l'événement d'attente Extension dans pg_stat_activity et Performance Insights l'indique. La fonction get_flow_control_stats affiche des détails sur le délai actuellement ajouté.
Le contrôle de flux peut bénéficier à la plupart des charges de travail de traitement transactionnel en ligne (OLTP) ayant des transactions courtes mais très concurrentes. Si le retard est causé par des transactions de longue durée, telles que des opérations par lots, le contrôle de flux n'offre pas un avantage aussi important.
Vous pouvez désactiver le contrôle de flux en supprimant l'extension de shared_preload_libraries et en redémarrant votre instance de base de données.
Multi-AZ Instantanés du cluster de base de données
Amazon RDS crée et enregistre des sauvegardes automatisées de votre Multi-AZ cluster de bases de données pendant la fenêtre de sauvegarde configurée. RDS crée un instantané du volume de stockage de votre cluster de bases de données en sauvegardant l’intégralité de ce dernier, et pas seulement les instances.
Vous pouvez également effectuer des sauvegardes manuelles de votre Multi-AZ cluster de base de données. Pour les sauvegardes à très long terme, envisagez d’exporter les données d’instantané vers Amazon S3. Pour de plus amples informations, veuillez consulter Création d'un instantané de Multi-AZ cluster de base de données pour Amazon RDS.
Vous pouvez restaurer un Multi-AZ cluster de bases de données à un moment précis, en créant un nouveau Multi-AZ cluster de base de données. Pour obtenir des instructions, veuillez consulter Restauration d'un Multi-AZ cluster de base de données à une heure spécifiée.
Vous pouvez également restaurer un instantané de Multi-AZ cluster de base de données dans le cadre d'un Single-AZ déploiement ou d'un déploiement d' Multi-AZ instance de base de données. Pour obtenir des instructions, veuillez consulter Restauration à partir d'un instantané de Multi-AZ cluster de base de données vers une instance de base de données.
