Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'un rapport d'évaluation multiserveur dans AWS Schema Conversion Tool
Pour déterminer la meilleure orientation cible pour votre environnement global, créez un rapport d'évaluation multiserveur.
Un rapport d'évaluation multiserveur évalue plusieurs serveurs en fonction des entrées que vous fournissez pour chaque définition de schéma que vous souhaitez évaluer. La définition de votre schéma contient les paramètres de connexion au serveur de base de données et le nom complet de chaque schéma. Après avoir évalué chaque schéma, AWS SCT produit un rapport d'évaluation récapitulatif et agrégé pour la migration de bases de données sur vos multiples serveurs. Ce rapport indique la complexité estimée pour chaque cible de migration possible.
Vous pouvez l'utiliser AWS SCT pour créer un rapport d'évaluation multiserveur pour les bases de données source et cible suivantes.
| Base de données source | Base de données cible |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Base de données Azure SQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Analyses Azure Synapse |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM DB2 pour z/OS |
Édition compatible avec Amazon Aurora MySQL (Aurora MySQL), édition compatible avec Amazon Aurora PostgreSQL (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish pour Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Réalisation d'une évaluation multiserveur
Utilisez la procédure suivante pour effectuer une évaluation multiserveur avec AWS SCT. Il n'est pas nécessaire de créer un nouveau projet AWS SCT pour effectuer une évaluation multiserveur. Avant de commencer, assurez-vous d'avoir préparé un fichier de valeurs séparées par des virgules (CSV) avec les paramètres de connexion à la base de données. Assurez-vous également d'avoir installé tous les pilotes de base de données requis et de définir l'emplacement des pilotes dans les AWS SCT paramètres. Pour de plus amples informations, veuillez consulter Installation des pilotes JDBC pour AWS Schema Conversion Tool.
Pour effectuer une évaluation multiserveur et créer un rapport de synthèse agrégé
-
Dans AWS SCT, choisissez Fichier, Nouvelle évaluation multiserveur. La boîte de dialogue Nouvelle évaluation multiserveur s'ouvre.
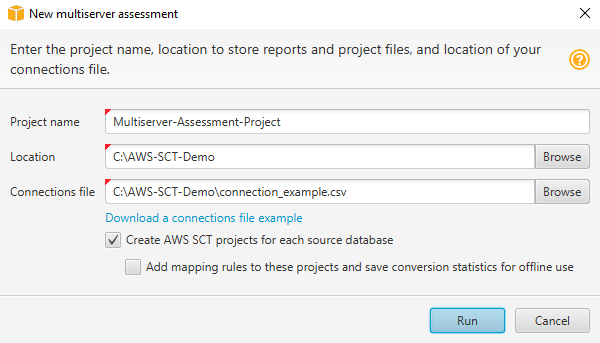
-
Choisissez Télécharger un exemple de fichier de connexions pour télécharger un modèle vide de fichier CSV contenant les paramètres de connexion à la base de données.
-
Entrez des valeurs pour le nom du projet, l'emplacement (pour stocker les rapports) et le fichier de connexions (un fichier CSV).
-
Choisissez Créer des AWS SCT projets pour chaque base de données source afin de créer automatiquement des projets de migration après avoir généré le rapport d'évaluation.
-
Lorsque l'option Créer AWS SCT des projets pour chaque base de données source est activée, vous pouvez choisir Ajouter des règles de mappage à ces projets et enregistrer les statistiques de conversion pour une utilisation hors ligne. Dans ce cas, AWS SCT ajoutera des règles de mappage à chaque projet et enregistrera les métadonnées de la base de données source dans le projet. Pour de plus amples informations, veuillez consulter Utilisation du mode hors ligne dans AWS Schema Conversion Tool.
-
Cliquez sur Exécuter.
Une barre de progression apparaît pour indiquer le rythme d'évaluation de la base de données. Le nombre de moteurs cibles peut affecter le temps d'exécution de l'évaluation.
-
Choisissez Oui si le message suivant s'affiche : L'analyse complète de tous les serveurs de base de données peut prendre un certain temps. Voulez-vous continuer ?
Lorsque le rapport d'évaluation multiserveur est terminé, un écran apparaît pour l'indiquer.
-
Choisissez Ouvrir le rapport pour afficher le rapport d'évaluation récapitulatif agrégé.
AWS SCT Génère par défaut un rapport agrégé pour toutes les bases de données sources et un rapport d'évaluation détaillé pour chaque nom de schéma dans une base de données source. Pour de plus amples informations, veuillez consulter Localisation et affichage des rapports.
Lorsque l'option Créer AWS SCT des projets pour chaque base de données source est activée, AWS SCT crée un projet vide pour chaque base de données source. AWS SCT crée également des rapports d'évaluation comme décrit précédemment. Après avoir analysé ces rapports d'évaluation et choisi la destination de migration pour chaque base de données source, ajoutez des bases de données cibles à ces projets vides.
Lorsque l'option Ajouter des règles de mappage à ces projets et enregistrer les statistiques de conversion pour une utilisation hors ligne est activée, un projet est AWS SCT créé pour chaque base de données source. Ces projets incluent les informations suivantes :
Votre base de données source et une plate-forme de base de données cible virtuelle. Pour de plus amples informations, veuillez consulter Mappage vers des cibles virtuelles dans AWS Schema Conversion Tool.
Une règle de mappage pour cette paire source-cible. Pour de plus amples informations, veuillez consulter Cartographie des types de données.
Rapport d'évaluation de la migration de base de données pour cette paire source-cible.
Les métadonnées du schéma source, qui vous permettent d'utiliser ce AWS SCT projet en mode hors ligne. Pour de plus amples informations, veuillez consulter Utilisation du mode hors ligne dans AWS Schema Conversion Tool.
Préparation d'un fichier CSV d'entrée
Pour fournir des paramètres de connexion en entrée pour le rapport d'évaluation multiserveur, utilisez un fichier CSV comme indiqué dans l'exemple suivant.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
L'exemple précédent utilise un point-virgule pour séparer les deux noms de schéma de la base de données. Sales Il utilise également un point-virgule pour séparer les deux plateformes de migration de base de données cibles pour la base de données. Sales
L'exemple précédent utilise également la connexion AWS Secrets Manager à la Customers base de données et l'authentification Windows pour la connexion à la HR base de données.
Vous pouvez créer un nouveau fichier CSV ou télécharger un modèle de fichier CSV depuis AWS SCT et renseigner les informations requises. Assurez-vous que la première ligne de votre fichier CSV inclut les mêmes noms de colonnes que ceux illustrés dans l'exemple précédent.
Pour télécharger un modèle du fichier CSV d'entrée
Démarrez AWS SCT.
Choisissez Fichier, puis choisissez Nouvelle évaluation multiserveur.
Choisissez Télécharger un exemple de fichier de connexions.
Assurez-vous que votre fichier CSV inclut les valeurs suivantes, fournies par le modèle :
-
Nom : étiquette de texte qui permet d'identifier votre base de données. AWS SCT affiche cette étiquette de texte dans le rapport d'évaluation.
-
Description — Valeur facultative, dans laquelle vous pouvez fournir des informations supplémentaires sur la base de données.
-
Clé de gestion secrète : nom du secret qui stocke les informations d'identification de votre base de données dans le AWS Secrets Manager. Pour utiliser Secrets Manager, assurez-vous de stocker AWS les profils dans AWS SCT. Pour de plus amples informations, veuillez consulter Configuration AWS Secrets Manager dans AWS Schema Conversion Tool.
Important
AWS SCT ignore le paramètre Secret Manager Key si vous incluez les paramètres IP du serveur, port, identifiant et mot de passe dans le fichier d'entrée.
-
IP du serveur : nom ou adresse IP du service de noms de domaine (DNS) de votre serveur de base de données source.
-
Port : port utilisé pour se connecter à votre serveur de base de données source.
-
Nom du service : si vous utilisez un nom de service pour vous connecter à votre base de données Oracle, il s'agit du nom du service Oracle auquel vous souhaitez vous connecter.
-
Nom de la base de données : nom de la base de données. Pour les bases de données Oracle, utilisez l'identifiant système Oracle (SID).
-
BigQuery path : chemin d'accès au fichier clé du compte de service pour votre BigQuery base de données source. Pour plus d'informations sur la création de ce fichier, consultezPrivilèges pour BigQuery en tant que source.
-
Moteur source : type de votre base de données source. Utilisez l'une des valeurs suivantes :
AZURE_MSSQL pour une base de données Azure SQL.
AZURE_SYNAPSE pour une base de données Azure Synapse Analytics.
GOOGLE_BIGQUERY pour une base de données. BigQuery
DB2ZOS pour une base de données IBM Db2 for z/OS .
DB2LUW pour une base de données IBM DB2 LUW.
GREENPLUM pour une base de données Greenplum.
MSSQL pour une base de données Microsoft SQL Server.
MYSQL pour une base de données MySQL.
NETEZZA pour une base de données Netezza.
ORACLE pour une base de données Oracle.
POSTGRESQL pour une base de données PostgreSQL.
REDSHIFT pour une base de données Amazon Redshift.
SNOWFLAKE pour une base de données Snowflake.
SYBASE_ASE pour une base de données SAP ASE.
TERADATA pour une base de données Teradata.
VERTICA pour une base de données Vertica.
-
Noms des schémas : noms des schémas de base de données à inclure dans le rapport d'évaluation.
Pour Azure SQL Database, Azure Synapse Analytics BigQuery, Netezza, SAP ASE, Snowflake et SQL Server, utilisez le format suivant pour le nom du schéma :
db_name.schema_nameRemplacez
db_nameRemplacez
schema_namePlacez les noms de base de données ou de schéma qui incluent un point entre guillemets doubles, comme indiqué ci-dessous :
"database.name"."schema.name".Séparez plusieurs noms de schéma en utilisant des points-virgules comme indiqué ci-dessous :.
Schema1;Schema2Les noms de base de données et de schéma distinguent les majuscules et minuscules.
Utilisez le pourcentage (
%) comme caractère générique pour remplacer un certain nombre de symboles dans le nom de la base de données ou du schéma. L'exemple précédent utilise le pourcentage (%) comme caractère générique pour inclure tous les schémas de laemployeesbase de données dans le rapport d'évaluation. -
Utiliser l'authentification Windows : si vous utilisez l'authentification Windows pour vous connecter à votre base de données Microsoft SQL Server, entrez true. Pour de plus amples informations, veuillez consulter Utilisation de l'authentification Windows lors de l'utilisation de Microsoft SQL Server comme source.
-
Login : nom d'utilisateur permettant de se connecter à votre serveur de base de données source.
-
Mot de passe : mot de passe pour vous connecter à votre serveur de base de données source.
-
Utiliser le protocole SSL : si vous utilisez le protocole SSL (Secure Sockets Layer) pour vous connecter à votre base de données source, entrez true.
-
Trust store : le trust store à utiliser pour votre connexion SSL.
-
Magasin de clés — Le magasin de clés à utiliser pour votre connexion SSL.
-
Authentification SSL — Si vous utilisez l'authentification SSL par certificat, entrez true.
-
Moteurs cibles : plateformes de base de données cibles. Utilisez les valeurs suivantes pour spécifier une ou plusieurs cibles dans le rapport d'évaluation :
AURORA_MYSQL pour une base de données compatible avec Aurora MySQL.
AURORA_POSTGRESQL pour une base de données compatible avec Aurora PostgreSQL.
BABELFISH pour une base de données PostgreSQL Babelfish pour Aurora.
MARIA_DB pour une base de données MariaDB.
MSSQL pour une base de données Microsoft SQL Server.
MYSQL pour une base de données MySQL.
ORACLE pour une base de données Oracle.
POSTGRESQL pour une base de données PostgreSQL.
REDSHIFT pour une base de données Amazon Redshift.
Séparez plusieurs cibles en utilisant des points-virgules comme celui-ci :.
MYSQL;MARIA_DBLe nombre de cibles influe sur le temps nécessaire à l'exécution de l'évaluation.
Localisation et affichage des rapports
L'évaluation multiserveur génère deux types de rapports :
-
Rapport agrégé de toutes les bases de données sources.
-
Rapport d'évaluation détaillé des bases de données cibles pour chaque nom de schéma dans une base de données source.
Les rapports sont stockés dans le répertoire que vous avez choisi comme Emplacement dans la boîte de dialogue Nouvelle évaluation multiserveur.
Pour accéder aux rapports détaillés, vous pouvez parcourir les sous-répertoires organisés par base de données source, nom de schéma et moteur de base de données cible.
Les rapports agrégés présentent des informations sur quatre colonnes concernant la complexité de conversion d'une base de données cible. Les colonnes incluent des informations sur la conversion d'objets de code, d'objets de stockage, d'éléments de syntaxe et de complexité de conversion.
L'exemple suivant montre les informations relatives à la conversion de deux schémas de base de données Oracle en Amazon RDS for PostgreSQL.

Les quatre mêmes colonnes sont ajoutées aux rapports pour chaque moteur de base de données cible supplémentaire spécifié.
Pour plus de détails sur la façon de lire ces informations, reportez-vous à la section suivante.
Résultat pour un rapport d'évaluation agrégé
Le rapport agrégé d'évaluation de la migration des bases de données multiserveurs AWS Schema Conversion Tool est un fichier CSV contenant les colonnes suivantes :
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
Pour recueillir des informations, AWS SCT exécute des rapports d'évaluation complets, puis agrège les rapports par schémas.
Dans le rapport, les trois champs suivants indiquent le pourcentage de conversion automatique possible sur la base de l'évaluation :
- % de conversion d'objets de code
-
Pourcentage d'objets de code du schéma qui AWS SCT peuvent être convertis automatiquement ou avec un minimum de modifications. Les objets de code incluent des procédures, des fonctions, des vues, etc.
- % de conversion des objets de stockage
-
Pourcentage d'objets de stockage que le SCT peut convertir automatiquement ou avec un minimum de modifications. Les objets de stockage incluent les tables, les index, les contraintes, etc.
- % de conversion des éléments de syntaxe
-
Pourcentage d'éléments de syntaxe que le SCT peut convertir automatiquement. Les éléments de syntaxe incluent
SELECTFROMDELETE,,, et lesJOINclauses, etc.
Le calcul de la complexité de conversion est basé sur la notion d'éléments d'action. Un élément d'action reflète un type de problème détecté dans le code source que vous devez résoudre manuellement lors de la migration vers une cible particulière. Un élément d'action peut avoir plusieurs occurrences.
Une échelle pondérée identifie le niveau de complexité associé à la réalisation d'une migration. Le chiffre 1 représente le niveau de complexité le plus faible et le chiffre 10 représente le niveau de complexité le plus élevé.
