Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration des charges de travail Hadoop vers Amazon EMR avec AWS Schema Conversion Tool
Pour migrer des clusters Apache Hadoop, assurez-vous d'utiliser la AWS SCT version 1.0.670 ou supérieure. Familiarisez-vous également avec l'interface de ligne de commande (CLI) de AWS SCT. Pour de plus amples informations, veuillez consulter Référence CLI pour AWS Schema Conversion Tool.
Présentation de la migration
L'image suivante montre le schéma d'architecture de la migration d'Apache Hadoop vers Amazon EMR.
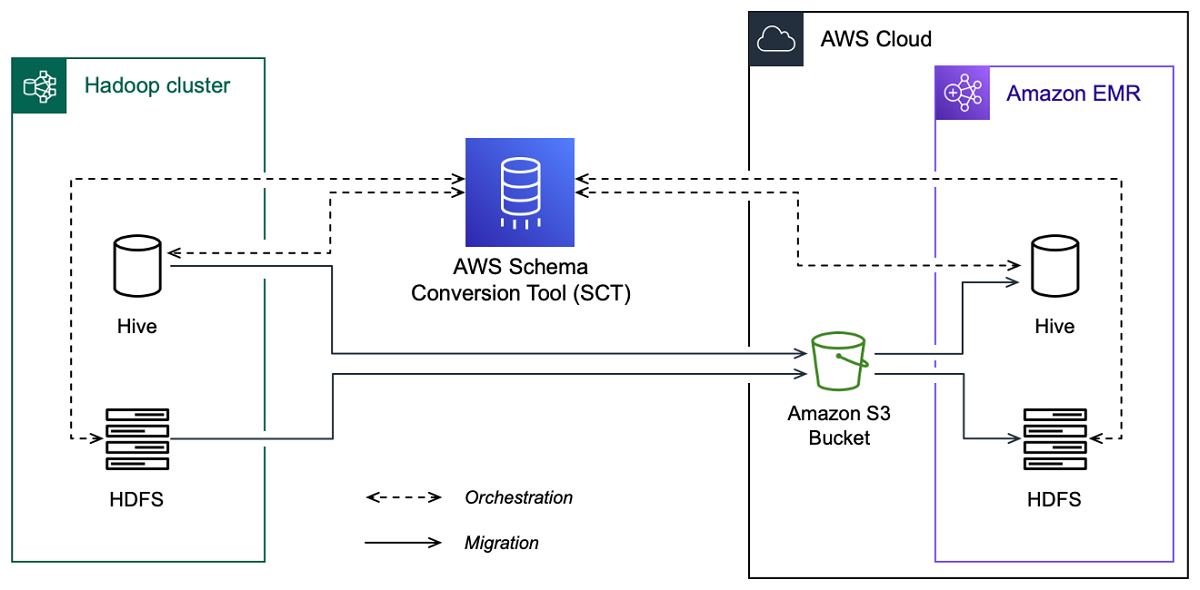
AWS SCT migre les données et les métadonnées de votre cluster Hadoop source vers un compartiment Amazon S3. Ensuite, AWS SCT utilise vos métadonnées Hive source pour créer des objets de base de données dans le service Amazon EMR Hive cible. Vous pouvez éventuellement configurer Hive pour qu'il utilise le AWS Glue Data Catalog comme métastore. Dans ce cas, AWS SCT migre vos métadonnées Hive source vers le. AWS Glue Data Catalog
Vous pouvez ensuite les utiliser AWS SCT pour migrer les données d'un compartiment Amazon S3 vers votre service Amazon EMR HDFS cible. Vous pouvez également laisser les données dans votre compartiment Amazon S3 et les utiliser comme référentiel de données pour vos charges de travail Hadoop.
Pour démarrer la migration vers Hapood, vous devez créer et exécuter votre script AWS SCT CLI. Ce script inclut l'ensemble complet des commandes permettant d'exécuter la migration. Vous pouvez télécharger et modifier un modèle de script de migration Hadoop. Pour de plus amples informations, veuillez consulter Obtenir des scénarios CLI.
Assurez-vous que votre script inclut les étapes suivantes afin de pouvoir exécuter votre migration d'Apache Hadoop vers Amazon S3 et Amazon EMR.
Étape 1 : Connectez-vous à vos clusters Hadoop
Pour démarrer la migration de votre cluster Apache Hadoop, créez un nouveau AWS SCT projet. Connectez-vous ensuite à vos clusters source et cible. Assurez-vous de créer et de provisionner vos AWS ressources cibles avant de commencer la migration.
Au cours de cette étape, vous devez utiliser les commandes AWS SCT CLI suivantes.
CreateProject— pour créer un nouveau AWS SCT projet.AddSourceCluster— pour vous connecter au cluster Hadoop source de votre AWS SCT projet.AddSourceClusterHive— pour vous connecter au service Hive source de votre projet.AddSourceClusterHDFS— pour vous connecter au service HDFS source de votre projet.AddTargetCluster— pour vous connecter au cluster Amazon EMR cible de votre projet.AddTargetClusterS3— pour ajouter le compartiment Amazon S3 à votre projet.AddTargetClusterHive— pour vous connecter au service Hive cible de votre projetAddTargetClusterHDFS— pour vous connecter au service HDFS cible de votre projet
Pour des exemples d'utilisation de ces commandes AWS SCT CLI, consultezConnexion à Apache Hadoop.
Lorsque vous exécutez la commande qui se connecte à un cluster source ou cible, AWS SCT essaie d'établir la connexion à ce cluster. Si la tentative de connexion échoue, AWS SCT arrête d'exécuter les commandes de votre script CLI et affiche un message d'erreur.
Étape 2 : configurer les règles de mappage
Après vous être connecté à vos clusters source et cible, configurez les règles de mappage. Une règle de mappage définit la cible de migration pour un cluster source. Assurez-vous de définir des règles de mappage pour tous les clusters sources que vous avez ajoutés dans votre AWS SCT projet. Pour plus d'informations sur les règles de mappage, consultezCartographie des types de données dans AWS Schema Conversion Tool.
Dans cette étape, vous devez utiliser la AddServerMapping commande. Cette commande utilise deux paramètres qui définissent les clusters source et cible. Vous pouvez utiliser la AddServerMapping commande avec le chemin explicite vers les objets de votre base de données ou avec le nom d'un objet. Pour la première option, vous devez inclure le type de l'objet et son nom. Pour la deuxième option, vous n'incluez que les noms des objets.
-
sourceTreePath— le chemin explicite vers les objets de votre base de données source.targetTreePath— le chemin explicite vers les objets de votre base de données cible. -
sourceNamePath: le chemin qui inclut uniquement les noms de vos objets source.targetNamePath: le chemin qui inclut uniquement les noms de vos objets cibles.
L'exemple de code suivant crée une règle de mappage utilisant des chemins explicites pour la base de données testdb Hive source et le cluster EMR cible.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Vous pouvez utiliser cet exemple et les exemples suivants sous Windows. Pour exécuter les commandes CLI sous Linux, assurez-vous d'avoir mis à jour les chemins de fichiers en fonction de votre système d'exploitation.
L'exemple de code suivant crée une règle de mappage en utilisant les chemins qui incluent uniquement les noms des objets.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Vous pouvez choisir Amazon EMR ou Amazon S3 comme cible pour votre objet source. Pour chaque objet source, vous ne pouvez choisir qu'une seule cible dans un seul AWS SCT projet. Pour modifier la cible de migration d'un objet source, supprimez la règle de mappage existante, puis créez-en une nouvelle. Pour supprimer une règle de mappage, utilisez la DeleteServerMapping commande. Cette commande utilise l'un des deux paramètres suivants.
sourceTreePath— le chemin explicite vers les objets de votre base de données source.sourceNamePath: le chemin qui inclut uniquement les noms de vos objets source.
Pour plus d'informations sur les DeleteServerMapping commandes AddServerMapping et, consultez la référence de la AWS Schema Conversion Tool CLI
Étape 3 : Création d'un rapport d'évaluation
Avant de commencer la migration, nous vous recommandons de créer un rapport d'évaluation. Ce rapport résume toutes les tâches de migration et détaille les actions qui apparaîtront au cours de la migration. Pour vous assurer que votre migration n'échoue pas, consultez ce rapport et abordez les mesures à prendre avant la migration. Pour de plus amples informations, veuillez consulter Rapport d’évaluation.
Dans cette étape, vous devez utiliser la CreateMigrationReport commande. Cette commande utilise deux paramètres. Le treePath paramètre est obligatoire, tandis que le forceMigrate paramètre est facultatif.
treePath— le chemin explicite vers les objets de votre base de données source pour lesquels vous enregistrez une copie du rapport d'évaluation.forceMigrate— lorsque ce paramètre est défini surtrue, AWS SCT poursuit la migration même si votre projet inclut un dossier HDFS et une table Hive faisant référence au même objet. La valeur par défaut estfalse.
Vous pouvez ensuite enregistrer une copie du rapport d'évaluation au format PDF ou au format CSV (valeurs séparées par des virgules). Pour ce faire, utilisez la SaveReportCSV commande SaveReportPDF or.
La SaveReportPDF commande enregistre une copie de votre rapport d'évaluation sous forme de fichier PDF. Cette commande utilise quatre paramètres. Le file paramètre est obligatoire, les autres paramètres sont facultatifs.
file— le chemin d'accès au fichier PDF et son nom.filter: le nom du filtre que vous avez créé auparavant pour définir l'étendue des objets source à migrer.treePath— le chemin explicite vers les objets de votre base de données source pour lesquels vous enregistrez une copie du rapport d'évaluation.namePath: le chemin qui inclut uniquement les noms des objets cibles pour lesquels vous enregistrez une copie du rapport d'évaluation.
La SaveReportCSV commande enregistre votre rapport d'évaluation dans trois fichiers CSV. Cette commande utilise quatre paramètres. Le directory paramètre est obligatoire, les autres paramètres sont facultatifs.
directory— le chemin d'accès au dossier dans lequel AWS SCT sont enregistrés les fichiers CSV.filter: le nom du filtre que vous avez créé auparavant pour définir l'étendue des objets source à migrer.treePath— le chemin explicite vers les objets de votre base de données source pour lesquels vous enregistrez une copie du rapport d'évaluation.namePath: le chemin qui inclut uniquement les noms des objets cibles pour lesquels vous enregistrez une copie du rapport d'évaluation.
L'exemple de code suivant enregistre une copie du rapport d'évaluation dans le c:\sct\ar.pdf fichier.
SaveReportPDF -file:'c:\sct\ar.pdf' /
L'exemple de code suivant enregistre une copie du rapport d'évaluation sous forme de fichiers CSV dans le c:\sct dossier.
SaveReportCSV -file:'c:\sct' /
Pour plus d'informations sur les SaveReportCSV commandes SaveReportPDF et, consultez la référence de la AWS Schema Conversion Tool CLI
Étape 4 : migrer votre cluster Apache Hadoop vers Amazon EMR avec AWS SCT
Après avoir configuré votre AWS SCT projet, lancez la migration de votre cluster Apache Hadoop local vers le. AWS Cloud
Au cours de cette étape, vous devez utiliser les ResumeMigration commandes MigrateMigrationStatus, et.
La Migrate commande fait migrer vos objets source vers le cluster cible. Cette commande utilise quatre paramètres. Assurez-vous de spécifier le treePath paramètre filter ou. Les autres paramètres sont facultatifs.
filter: le nom du filtre que vous avez créé auparavant pour définir l'étendue des objets source à migrer.treePath— le chemin explicite vers les objets de votre base de données source pour lesquels vous enregistrez une copie du rapport d'évaluation.forceLoad— lorsqu'il est défini surtrue, charge AWS SCT automatiquement les arborescences de métadonnées de la base de données lors de la migration. La valeur par défaut estfalse.forceMigrate— lorsque ce paramètre est défini surtrue, AWS SCT poursuit la migration même si votre projet inclut un dossier HDFS et une table Hive faisant référence au même objet. La valeur par défaut estfalse.
La MigrationStatus commande renvoie les informations relatives à la progression de la migration. Pour exécuter cette commande, entrez le nom de votre projet de migration pour le name paramètre. Vous avez indiqué ce nom dans la CreateProject commande.
La ResumeMigration commande reprend la migration interrompue que vous avez lancée à l'aide de la Migrate commande. La ResumeMigration commande n'utilise pas de paramètres. Pour reprendre la migration, vous devez vous connecter à vos clusters source et cible. Pour de plus amples informations, veuillez consulter Gestion de votre projet de migration.
L'exemple de code suivant migre les données de votre service HDFS source vers Amazon EMR.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
Exécution de votre script CLI
Une fois que vous avez terminé de modifier votre script AWS SCT CLI, enregistrez-le sous forme de fichier avec l'.sctsextension. Vous pouvez maintenant exécuter votre script depuis le app dossier correspondant à votre chemin AWS SCT d'installation. Pour cela, utilisez la commande suivante.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
Dans l'exemple précédent, remplacez script_path par le chemin d'accès à votre fichier par le script CLI. Pour plus d'informations sur l'exécution de scripts CLI dans AWS SCT, consultezMode script.
Gestion de votre projet de migration de mégadonnées
Une fois la migration terminée, vous pouvez enregistrer et modifier votre AWS SCT projet pour une utilisation future.
Pour enregistrer votre AWS SCT projet, utilisez la SaveProject commande. Cette commande n'utilise pas de paramètres.
L'exemple de code suivant enregistre votre AWS SCT projet.
SaveProject /
Pour ouvrir votre AWS SCT projet, utilisez la OpenProject commande. Cette commande utilise un paramètre obligatoire. Pour le file paramètre, entrez le chemin d'accès à votre fichier de AWS SCT projet et son nom. Vous avez indiqué le nom du projet dans la CreateProject commande. Assurez-vous d'ajouter l'.sctsextension au nom de votre fichier de projet pour exécuter la OpenProject commande.
L'exemple de code suivant ouvre le hadoop_emr projet depuis le c:\sct dossier.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
Après avoir ouvert votre AWS SCT projet, vous n'avez pas besoin d'ajouter les clusters source et cible, car vous les avez déjà ajoutés à votre projet. Pour commencer à travailler avec vos clusters source et cible, vous devez vous y connecter. Pour ce faire, vous devez utiliser les ConnectTargetCluster commandes ConnectSourceCluster et. Ces commandes utilisent les mêmes paramètres que les AddTargetCluster commandes AddSourceCluster et. Vous pouvez modifier votre script CLI et remplacer le nom de ces commandes en laissant la liste des paramètres inchangée.
L'exemple de code suivant permet de se connecter au cluster Hadoop source.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
L'exemple de code suivant permet de se connecter au cluster Amazon EMR cible.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
Dans l'exemple précédent, remplacez hadoop_address par l'adresse IP de votre cluster Hadoop. Si nécessaire, configurez la valeur de la variable de port. Ensuite, remplacez hadoop_user et hadoop_password par le nom de votre utilisateur Hadoop et le mot de passe de cet utilisateur. Pourpath\name, entrez le nom et le chemin du fichier PEM de votre cluster Hadoop source. Pour plus d'informations sur l'ajout de vos clusters source et cible, consultezConnexion aux bases de données Apache Hadoop à l'aide du AWS Schema Conversion Tool.
Après vous être connecté à vos clusters Hadoop source et cible, vous devez vous connecter à vos services Hive et HDFS, ainsi qu'à votre compartiment Amazon S3. Pour ce faire, vous devez utiliser les ConnectTargetClusterS3 commandes ConnectSourceClusterHive ConnectSourceClusterHdfsConnectTargetClusterHive,ConnectTargetClusterHdfs,, et. Ces commandes utilisent les mêmes paramètres que les commandes que vous avez utilisées pour ajouter les services Hive et HDFS, ainsi que le bucket Amazon S3 à votre projet. Modifiez le script CLI pour remplacer le Add préfixe par Connect le nom des commandes.
