Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Évaluation de votre capacité provisionnée pour un dimensionnement approprié dans votre table DynamoDB
Cette section explique comment évaluer si vous avez alloué la capacité appropriée pour vos tables DynamoDB. À mesure que votre charge de travail évolue, vous devez modifier vos procédures opérationnelles de manière appropriée, notamment lorsque votre table DynamoDB est configurée en mode provisionné et que vous risquez de surprovisionner ou de sous-provisionner vos tables.
Les procédures décrites ci-dessous nécessitent des informations statistiques qui doivent être capturées à partir des tables DynamoDB qui prennent en charge votre application de production. Pour comprendre le comportement de votre application, vous devez définir une période suffisamment longue pour tenir compte de la saisonnalité de ses données. Par exemple, si votre application repose sur des cycles hebdomadaires, spécifier une période de trois semaines devrait vous laisser suffisamment de marge pour analyser ses besoins en matière de débit.
Si vous ne savez pas par où commencer, utilisez au moins un mois de données pour les calculs ci-dessous.
Lors de l’évaluation de la capacité, les tables DynamoDB peuvent configurer des unités de capacité de lecture (RCU) et des unités de capacité d’écriture (WCU) indépendamment. Si des index secondaires globaux (GSI) sont configurés sur vos tables, vous devez spécifier le débit qu’ils consommeront, qui est indépendant des UCU et des WCU de la table de base.
Note
Les index secondaires locaux (LSI) consomment la capacité à partir de la table de base.
Rubriques
Comment récupérer les métriques de consommation sur vos tables DynamoDB
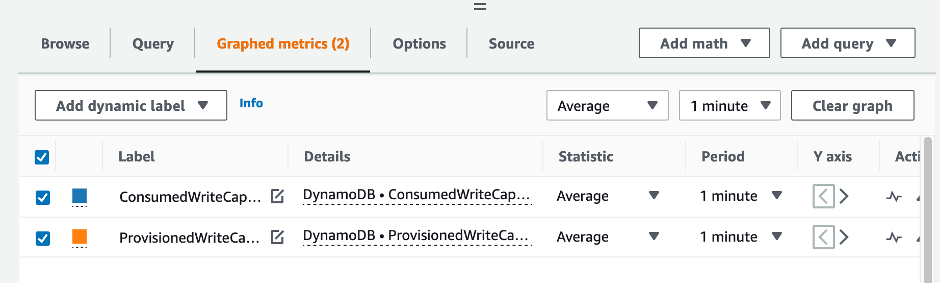
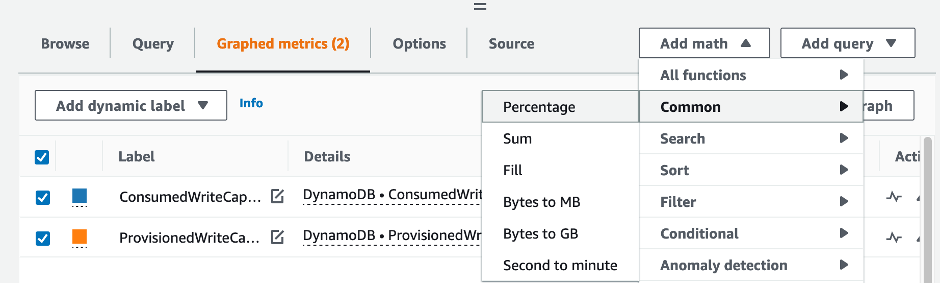
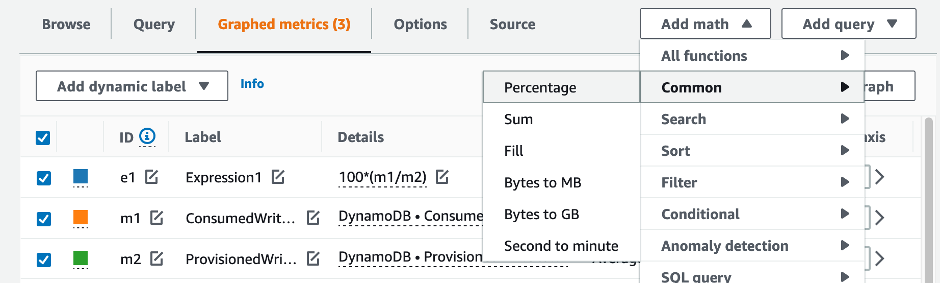
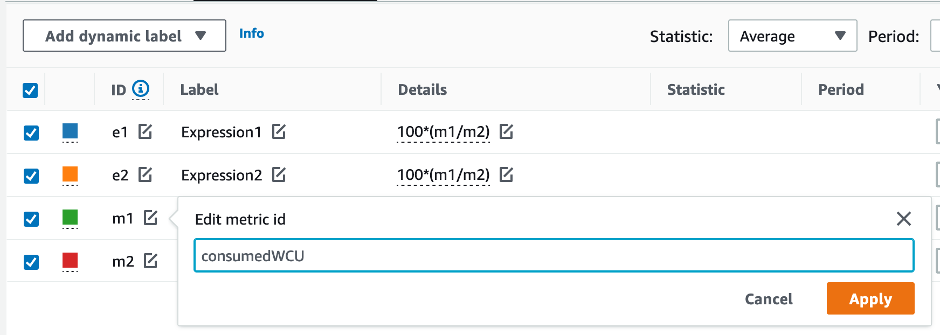
Pour évaluer la table et la capacité du GSI, surveillez les CloudWatch mesures suivantes et sélectionnez la dimension appropriée pour récupérer les informations du tableau ou du GSI :
| Unités de capacité de lecture | Unités de capacité d’écriture |
|---|---|
|
|
|
|
|
|
|
|
|
Vous pouvez le faire via le AWS CLI ou le AWS Management Console.
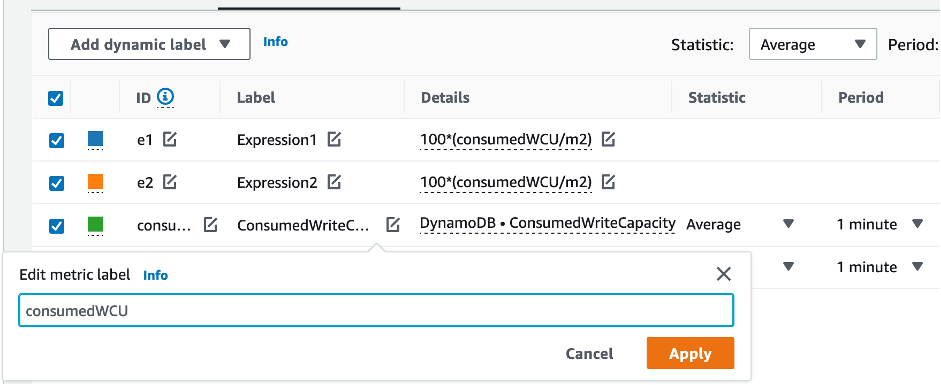
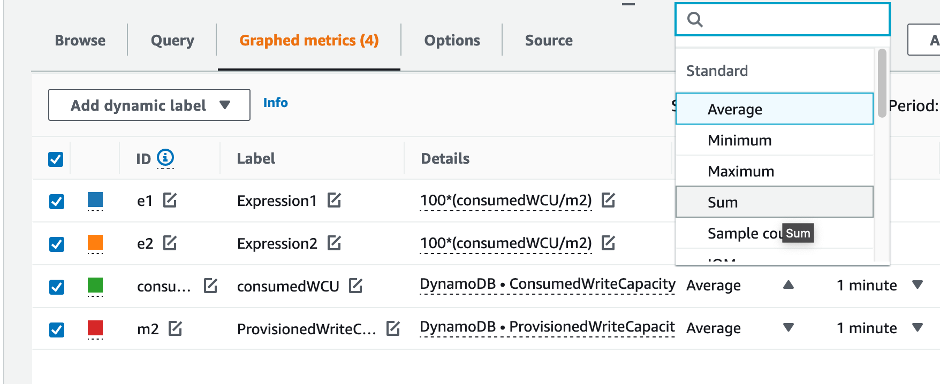
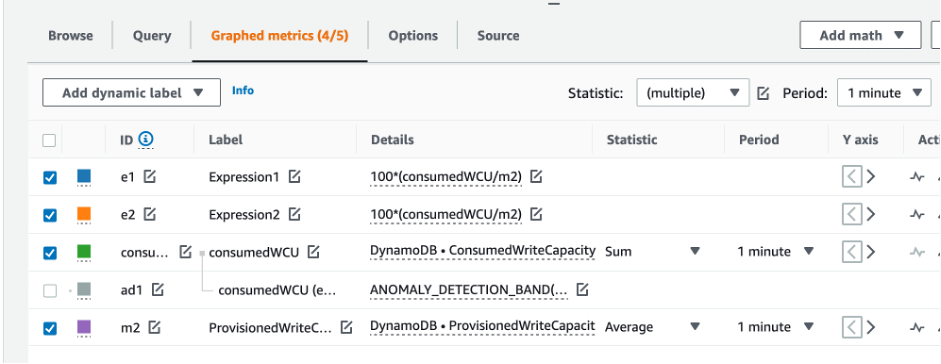
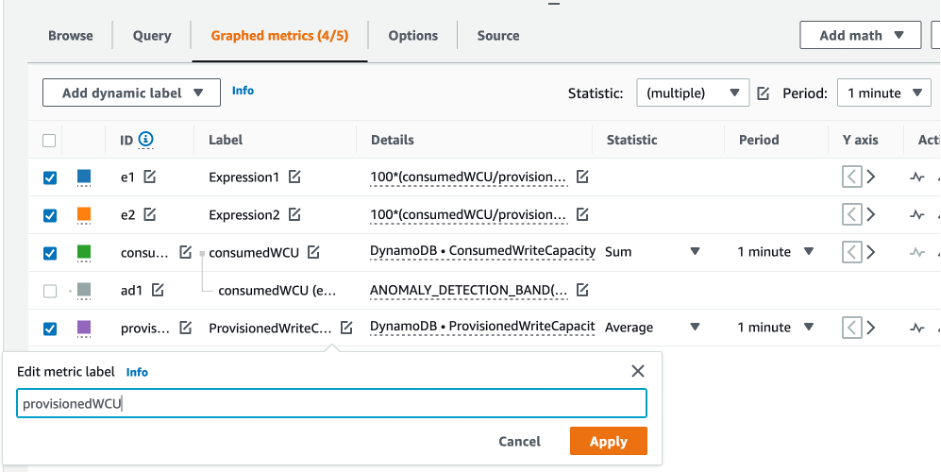
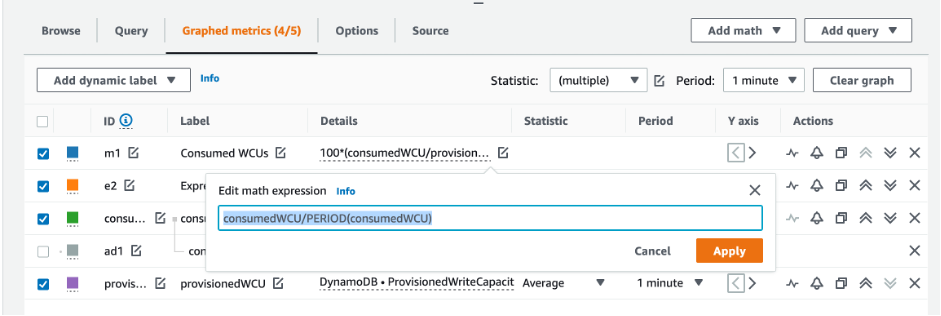
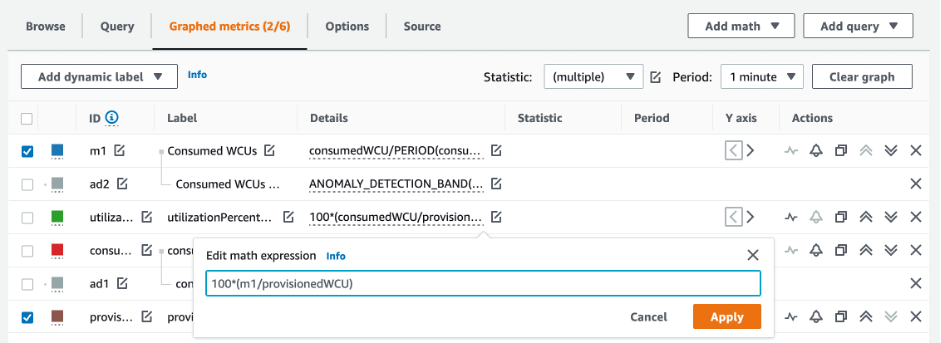
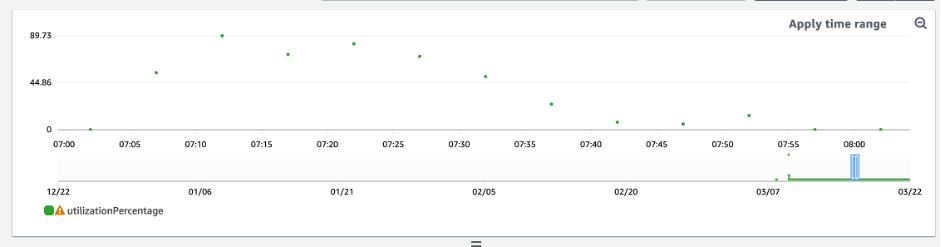
Comment identifier les tables DynamoDB sous-provisionnées
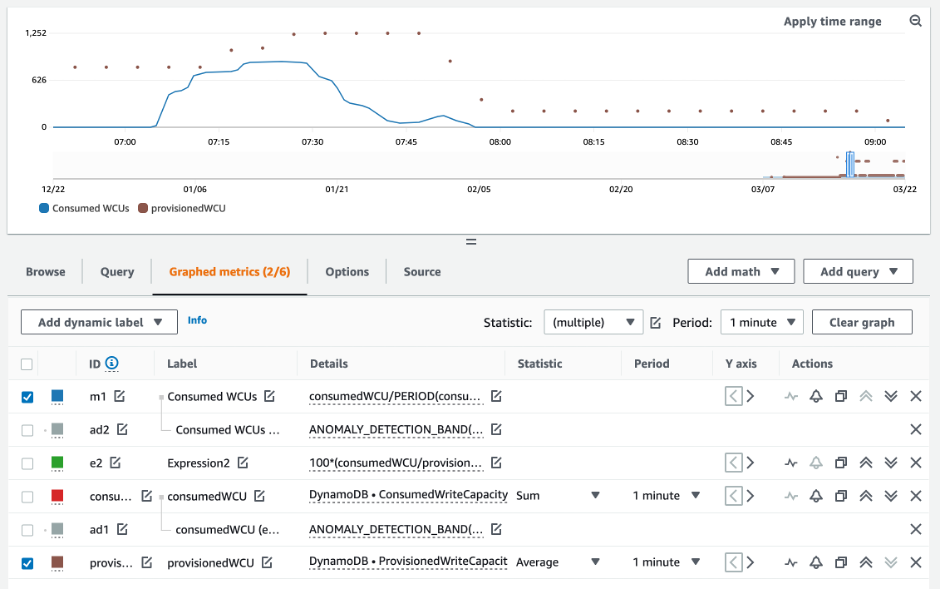
Pour la plupart des charges de travail, une table est considérée comme sous-provisionnée lorsqu’elle consomme constamment plus de 80 % de sa capacité provisionnée.
La capacité en rafale est une fonctionnalité de DynamoDB qui permet aux clients de consommer temporairement RCUs/WCUs plus que ce qui était initialement prévu (plus que le débit provisionné par seconde défini dans le tableau). La capacité de débordement a été créée pour absorber les augmentations soudaines du trafic dues à des événements spéciaux ou à des pics d’utilisation. Elle ne dure pas éternellement. Dès que les unités RCU et WCU inutilisées sont épuisées, vous êtes limité si vous essayez de consommer plus de capacité que celle allouée. Lorsque le trafic de votre application approche le taux d’utilisation de 80 %, le risque de limitation est nettement plus élevé.
La règle du taux d’utilisation de 80 % varie en fonction de la saisonnalité de vos données et de la croissance du trafic. Réfléchissez aux scénarios suivants :
-
Si le trafic est resté stable à un taux d’utilisation d’environ 90 % au cours des 12 derniers mois, votre table dispose de la capacité idéale
-
Si le trafic de vos applications augmente à un rythme de 8 % par mois en moins de 3 mois, vous allez atteindre une utilisation de 100 %
-
Si le trafic de vos applications augmente à un rythme de 5 % en un peu plus de 4 mois, vous allez tout de même atteindre une utilisation de 100 %
Les résultats des requêtes ci-dessus donnent une idée de votre taux d’utilisation. Utilisez-les comme guide pour évaluer plus en détail d’autres métriques qui pourront vous aider à choisir d’augmenter la capacité de votre table selon vos besoins (par exemple, à un taux de croissance mensuel ou hebdomadaire). Travaillez avec l’équipe des opérations pour définir le pourcentage approprié pour votre charge de travail et vos tables.
Il existe des scénarios particuliers dans lesquels les données sont biaisées lorsque nous les analysons sur une base quotidienne ou hebdomadaire. Par exemple, pour les applications saisonnières qui connaissent des pics d’utilisation pendant les heures de travail (mais qui tombent ensuite presque à zéro en dehors de ces plages horaires), vous pourriez bénéficier de l’autoscaling planifié qui permet de spécifier les heures de la journée (et les jours de la semaine) pour lesquels vous souhaitez augmenter la capacité provisionnée, et quand la réduire. Au lieu de viser une capacité plus élevée pour couvrir les heures de pointe, vous pouvez également tirer parti des configurations de l’autoscaling des tables DynamoDB si la saisonnalité de vos données est moins prononcée.
Note
Lorsque vous créez une configuration de mise à l’échelle automatique de DynamoDB pour votre table de base, n’oubliez pas d’inclure une autre configuration pour les index secondaires globaux qui y sont associés.
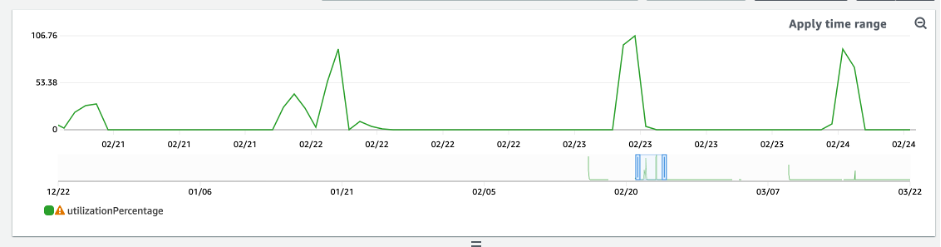
Comment identifier les tables DynamoDB surprovisionnées
Les résultats de requête obtenus à partir des scripts ci-dessus fournissent les points de données nécessaires pour effectuer une analyse initiale. Si votre ensemble de données présente des valeurs d’utilisation inférieures à 20 % pendant plusieurs intervalles, votre table est peut-être surprovisionnée. Pour déterminer plus précisément si vous devez réduire le nombre de WCU et de RCU, réexaminez les autres lectures dans les intervalles.
Lorsque des tables contiennent plusieurs intervalles d’utilisation faibles, vous pouvez tirer parti de l’utilisation de politiques d’autoscaling automatique en planifiant l’autoscaling automatique ou en configurant simplement les politiques d’autoscaling par défaut pour la table en fonction de l’utilisation.
Si votre charge de travail présente un faible ratio d'utilisation/accélération élevé (Max (ThrottleEvents) /Min (ThrottleEvents) dans l'intervalle), cela peut se produire lorsque vous avez une charge de travail très élevée où le trafic augmente considérablement pendant certains jours (ou heures), mais en général, le trafic est constamment faible. Dans ces scénarios, il peut être utile de recourir à l’autoscaling planifié.
