Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Analyse de tables dans DynamoDB
Une opération Scan dans Amazon DynamoDB lit tous les éléments d’une table ou d’un index secondaire. Par défaut, une opération Scan renvoie tous les attributs de données pour chaque élément de la table ou de l’index. Vous pouvez utiliser le paramètre ProjectionExpression de sorte que Scan renvoie uniquement certains des attributs, plutôt que leur totalité.
Scan renvoie toujours un ensemble de résultats. Si aucun élément correspondant n’est trouvé, l’ensemble de résultats est vide.
Une seule demande Scan permet d’extraire un maximum de 1 Mo de données. Le cas échéant, DynamoDB peut appliquer une expression de filtre à ces données, en affinant les résultats avant qu’ils soient renvoyés à l’utilisateur.
Note
A Scan renvoie les éléments dans un ordre déterminé par la façon dont la table ou l'index secondaire les stocke en interne. Les valeurs des clés de partition sont renvoyées dans un ordre arbitraire qui n'est pas trié. Dans une valeur de clé de partition unique, les éléments sont renvoyés par ordre croissant (ASC) par valeur de clé de tri.
Rubriques
Filtrer les expressions à des fins d’analyse
Si vous devez affiner davantage les résultats de l’opération Scan, vous pouvez également fournir une expression de filtre. Une expression de filtre détermine les éléments dans les résultats de l’opération Scan qui doivent vous être renvoyés. Tous les autres résultats sont ignorés.
Une expression de filtre est appliquée après la fin de l’opération Scan, mais avant que les résultats soient renvoyés. Par conséquent, une opération Scan consomme la même capacité de lecture, qu’une expression de filtre soit présente ou non.
Une opération Scan permet d’extraire au maximum 1 Mo de données. Cette limite s’applique avant que l’expression de filtre soit évaluée.
Avec Scan, vous pouvez spécifier tous les attributs dans une expression de filtre, y compris les attributs de clé de partition et de clé de tri.
La syntaxe d’un expression de filtre est identique à celle d’une expression de condition. Les expressions de filtre peuvent utiliser les mêmes comparateurs, fonctions et opérateurs logiques qu’une expression de condition. Pour en savoir plus sur les opérateurs, consultez Expressions de condition et de filtre, opérateurs et fonctions dans DynamoDB.
Exemple
L'exemple suivant AWS Command Line Interface (AWS CLI) analyse le Thread tableau et renvoie uniquement les derniers éléments publiés par un utilisateur en particulier.
aws dynamodb scan \ --table-name Thread \ --filter-expression "LastPostedBy = :name" \ --expression-attribute-values '{":name":{"S":"User A"}}'
Limiter le nombre d’éléments dans l’ensemble de résultats
L’opération Scan permet de limiter le nombre d’éléments renvoyés dans le résultat. Pour ce faire, définissez le paramètre Limit sur le nombre maximal d’éléments que vous souhaitez que l’opération Scan renvoie, avant l’évaluation de l’expression de filtre.
Par exemple, supposons que vous effectuiez une opération Scan sur une table, avec une valeur Limit de 6 et sans expression de filtre. Le résultat de l’opération Scan comporte les six premiers éléments de la table.
Supposons maintenant que vous ajoutiez une expression de filtre à l’opération Scan. Dans ce cas, DynamoDB applique l’expression de filtre aux six éléments renvoyés et supprime ceux qui ne correspondent pas. Le résultat final de l’opération Scan comporte six éléments au plus, selon le nombre d’éléments filtrés.
Pagination des résultats
DynamoDB pagine les résultats des opérations Scan. Avec la pagination, les résultats de l’opération Scan sont répartis en « pages » de données d’une taille maximum de 1 Mo. Une application peut traiter la première page des résultats, puis la deuxième, et ainsi de suite.
Une opération Scan renvoie uniquement un ensemble de résultats correspondant à la limite de taille de 1 Mo.
Pour déterminer si le nombre de résultats est plus important et récupérer une page à la fois, les applications doivent procéder comme suit :
-
Examinez le résultat de l’opération
Scande niveau inférieur :-
Si le résultat comporte un élément
LastEvaluatedKey, passez à l’étape 2. -
S’il n’y a pas de
LastEvaluatedKeydans le résultat, il n’y a plus aucun élément à récupérer.
-
-
Construisez une nouvelle demande
Scan, avec les mêmes paramètres que la précédente. Cependant, cette fois-ci, acceptez la valeurLastEvaluatedKeyde l’étape 1 et utilisez-la comme paramètreExclusiveStartKeydans la nouvelle demandeScan. -
Exécutez la nouvelle demande
Scan. -
Passez à l’étape 1.
Autrement dit, l’élément LastEvaluatedKey provenant d’une réponse de l’opération Scan doit être utilisé comme ExclusiveStartKey pour la demande Scan suivante. Si aucun élément LastEvaluatedKey n’est présent dans la réponse de l’opération Scan, vous avez extrait la dernière page de résultats. (L’absence de LastEvaluatedKey est le seul moyen de savoir que vous avez atteint la fin de l’ensemble de résultats.)
Vous pouvez utiliser le AWS CLI pour visualiser ce comportement. AWS CLI envoie des Scan requêtes de bas niveau à DynamoDB, à plusieurs reprises, LastEvaluatedKey jusqu'à ce qu'elles ne soient plus présentes dans les résultats. Prenons l' AWS CLI exemple suivant qui scanne l'intégralité du Movies tableau mais ne renvoie que les films d'un genre particulier.
aws dynamodb scan \ --table-name Movies \ --projection-expression "title" \ --filter-expression 'contains(info.genres,:gen)' \ --expression-attribute-values '{":gen":{"S":"Sci-Fi"}}' \ --page-size 100 \ --debug
Normalement, il AWS CLI gère automatiquement la pagination. Toutefois, dans cet exemple, le AWS CLI --page-size paramètre limite le nombre d'éléments par page. La paramètre --debug imprime les informations de bas niveau relatives aux demandes et aux réponses.
Note
Vos résultats de pagination diffèrent également en fonction des paramètres d’entrée que vous transmettez.
-
L’utilisation de
aws dynamodb scan --table-name Prices --max-items 1renvoie unNextToken -
L’utilisation de
aws dynamodb scan --table-name Prices --limit 1renvoie unLastEvaluatedKey.
Sachez également que l’utilisation de --starting-token en particulier requiert la valeur NextToken.
Si vous exécutez l’exemple, la première réponse de DynamoDB est similaire à ce qui suit.
2017-07-07 12:19:14,389 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":7,"Items":[{"title":{"S":"Monster on the Campus"}},{"title":{"S":"+1"}}, {"title":{"S":"100 Degrees Below Zero"}},{"title":{"S":"About Time"}},{"title":{"S":"After Earth"}}, {"title":{"S":"Age of Dinosaurs"}},{"title":{"S":"Cloudy with a Chance of Meatballs 2"}}], "LastEvaluatedKey":{"year":{"N":"2013"},"title":{"S":"Curse of Chucky"}},"ScannedCount":100}'
Le LastEvaluatedKey de la réponse indique que certains éléments n’ont pas été récupérés. Il envoie AWS CLI ensuite une autre Scan demande à DynamoDB. Ce modèle de requête et de réponse se poursuit jusqu’à l’obtention d’une réponse finale.
2017-07-07 12:19:17,830 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":1,"Items":[{"title":{"S":"WarGames"}}],"ScannedCount":6}'
L’absence de LastEvaluatedKey indique qu’il n’y a pas plus de d’élément à récupérer.
Note
Les AWS SDK gèrent les réponses DynamoDB de bas niveau (y compris la présence ou l'absence deLastEvaluatedKey) et fournissent diverses abstractions pour la pagination des résultats. Scan Par exemple, l’interface de document du kit SDK pour Java fournit le support java.util.Iterator pour vous permettre de parcourir les résultats un par un.
Pour des exemples de code dans divers langages de programmation, consultez le Guide de prise en main d’Amazon DynamoDB et la documentation du kit SDK AWS pour votre langage.
Comptabilisation des éléments dans les résultats
Outre les éléments qui correspondent à vos critères, la réponse d’une opération Scan comporte les éléments suivants :
-
ScannedCount– Nombre d’éléments évalués avant l’application deScanFilter. Une valeurScannedCountélevée avec un nombre faible ou nul de résultatsCountindique une opérationScaninefficace. Si vous n’avez pas utilisé de filtre dans la demande,ScannedCountetCountont la même valeur. -
Count– Nombre d’éléments qui restent après l’application d’une expression de filtre (le cas échéant).
Note
Si vous n’utilisez pas d’expression de filtre, ScannedCount et Count ont la même valeur.
Si la taille de l’ensemble de résultats Scan est supérieure à 1 Mo, les opérations ScannedCount et Count représentent seulement un décompte partiel du nombre total d’éléments. Vous devez effectuer plusieurs opérations Scan pour extraire tous les résultats. (Consultez Pagination des résultats.)
Chaque réponse Scan comporte les ScannedCount et Count des éléments traités par cette demande Scan particulière. Pour obtenir les totaux de toutes les demandes Scan, vous pouvez garder un compte actif de ScannedCount et Count.
Unités de capacité consommées par l’opération d’analyse
Vous pouvez effectuer une opération Scan sur toute table ou tout index secondaire. Les opérations Scan consomment des unités de capacité de lecture, comme suit.
Si vous effectuez une opération Scan sur… |
DynamoDB consomme des unités de capacité de lecture de… |
|---|---|
| Table | Capacité de lecture allouée de la table. |
| GSI | Capacité de lecture allouée à l’index. |
| Index secondaire local | Capacité de lecture allouée de la table de base. |
Note
Cross-account l'accès aux opérations d'analyse d'index secondaires n'est actuellement pas pris en charge par les politiques basées sur les ressources.
Par défaut, une opération Scan ne renvoie pas de données concernant la consommation de capacité de lecture. Vous pouvez toutefois spécifier le paramètre ReturnConsumedCapacity dans une demande Scan pour obtenir ces informations. Voici les paramètres valides pour ReturnConsumedCapacity :
-
NONE– Aucune donnée de capacité consommée n’est renvoyée. (Il s’agit de l’option par défaut.) -
TOTAL– La réponse inclut le nombre agrégé d’unités de capacité de lecture consommées. -
INDEXES– La réponse indique le nombre agrégé d’unités de capacité de lecture consommées, ainsi que la capacité consommée pour chaque table et index consultés.
DynamoDB calcule le nombre d’unités de capacité de lecture consommées en fonction du nombre d’éléments et de la taille de ces éléments, et non du volume de données renvoyées à une application. Pour cette raison, le nombre d’unités de capacité consommées sera le même que vous demandiez tous les attributs (comportement par défaut) ou seulement certains d’entre eux (avec une expression de projection). Le nombre est également le même, que vous utilisiez ou non une expression de filtre. Scan consomme une unité de capacité de lecture minimale pour effectuer une lecture fortement cohérente par seconde ou deux lectures cohérentes à terme par seconde pour un élément d’une taille maximale de 4 Ko. Si vous devez lire un élément d’une taille supérieure à 4 Ko, DynamoDB a besoin d’unités de demande de lecture supplémentaires. Les tables vides et les très grandes tables comportant un nombre restreint de clés de partition peuvent entraîner la facturation de certaines RCU supplémentaires au-delà du volume de données analysées. Cela couvre les frais de traitement de la demande Scan, même en l’absence de données.
Cohérence en lecture de l’opération d’analyse
Par défaut, une opération Scan effectue des lectures cohérentes à terme. Autrement dit, les résultats de l’opération Scan peuvent ne pas refléter des modifications apportées par des opérations PutItem ou UpdateItem récentes. Pour de plus amples informations, veuillez consulter Cohérence en lecture DynamoDB.
Si vous avez besoin de lectures fortement cohérentes au moment où l’opération Scan commence, définissez le paramètre ConsistentRead sur la valeur true dans la demande Scan. Ainsi, toutes les opérations d’écriture terminées avant le début de l’opération Scan sont incluses dans la réponse Scan.
La définition de ConsistentRead sur true peut être utile dans la sauvegarde des tables ou les scénarios de réplication, conjointement avec DynamoDB Streams. Vous utilisez d’abord Scan avec le paramètre ConsistentRead défini sur la valeur true pour obtenir une copie cohérente des données de la table. Pendant l’opération Scan, DynamoDB Streams enregistre toute activité d’écriture supplémentaire qui se produit sur la table. Une fois l’opération Scan terminée, vous pouvez appliquer l’activité d’écriture du flux vers la table.
Note
Notez qu’une opération Scan avec le paramètre ConsistentRead défini sur la valeur true consomme deux fois plus d’unités de capacité de lecture, par rapport au fait de laisser la paramètre ConsistentRead défini sur sa valeur par défaut (false).
Analyse parallèle
Par défaut, l’opération Scan traite les données de manière séquentielle. Amazon DynamoDB renvoie des données à l’application par incréments de 1 Mo, et une application effectue des opérations Scan supplémentaires pour extraire le Mo de données suivant.
Plus la table ou l’index en cours d’analyse est grand(e), plus l’opération Scan prend du temps. En outre, il arrive qu’une opération Scan séquentielle ne puisse pas utiliser pleinement la capacité de débit de lecture alloué. Même si DynamoDB répartit les données d’une grande table sur plusieurs partitions physiques, une opération Scan ne peut lire qu’une seule partition à la fois. C’est pourquoi le débit d’une opération Scan est limité par le débit maximum d’une partition.
Pour résoudre ce problème, l’opération Scan peut diviser logiquement une table ou un index secondaire en plusieurs segments, avec plusieurs workers d’application qui analysent les segments en parallèle. Chaque worker peut être un thread (lorsque le langage de programmation prend en charge le multithreading) ou un processus de système d’exploitation. Pour effectuer une analyse en parallèle, chaque worker émet sa propre demande Scan avec les paramètres suivants :
-
Segment– Segment à analyser par un worker particulier. Chaque worker doit utiliser une valeur différente pourSegment. -
TotalSegments– Nombre total de segments pour l’analyse en parallèle. Cette valeur doit être identique au nombre de workers que votre application va utiliser.
Le diagramme suivant illustre la manière dont une application multithread exécute une opération Scan en parallèle avec trois degrés de parallélisme.
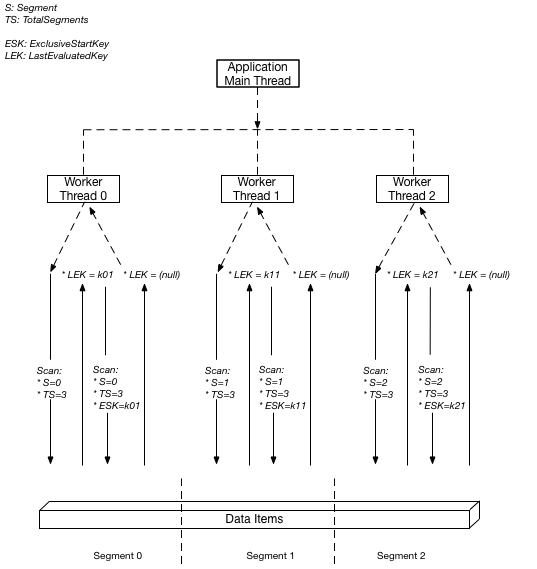
Dans ce diagramme, l’application produit trois threads auxquels elle affecte un numéro. (Les segments étant de base zéro, le premier numéro est toujours 0.) Chaque thread émet une demande Scan, définissant le paramètre Segment sur son numéro désigné, et le paramètre TotalSegments sur 3. Chaque thread analyse son segment désigné en extrayant 1 Mo de données à la fois, puis renvoie les données au thread principal de l’application.
DynamoDB affecte des éléments à des segments en appliquant une fonction de hachage à la clé de partition de chaque élément. Pour une TotalSegments valeur donnée, tous les éléments ayant la même clé de partition sont toujours assignés à la même valeurSegment. Cela signifie que dans un tableau où les éléments 1, 2 et 3 se partagent tous pk="account#123" (mais ont des clés de tri différentes), ces éléments seront traités par le même opérateur, quelles que soient les valeurs des clés de tri ou la taille de la collection d'articles.
Comme l'attribution des segments est basée uniquement sur le hachage de la clé de partition, les segments peuvent être répartis de manière inégale. Certains segments peuvent ne contenir aucun élément, tandis que d'autres peuvent contenir de nombreuses clés de partition avec de grandes collections d'éléments. Par conséquent, l'augmentation du nombre total de segments ne garantit pas des performances d'analyse plus rapides, en particulier lorsque les clés de partition ne sont pas réparties uniformément dans l'espace de touches.
Les valeurs des paramètres Segment et TotalSegments s’appliquent à des demandes Scan individuelles et vous pouvez utiliser différentes valeurs à tout moment. Il se peut que vous deviez tester ces valeurs et le nombre de workers que vous utilisez, jusqu’à ce que votre application atteigne des performances optimales.
Note
Une analyse en parallèle avec de nombreux threads peut facilement consommer tout le débit alloué pour la table ou l’index analysé(e). Il est préférable d’éviter de telles analyses si d’autres applications soumettent également la table ou l’index à une intense activité de lecture ou d’écriture.
Ccontrôlez le volume de données renvoyées par demande à l’aide du paramètre Limit. Cela vous permet d’éviter des situations où un worker consomme tout le débit alloué, au détriment des autres.
