Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Routage des demandes avec les tables globales DynamoDB
La partie la plus complexe d'un déploiement de tables globales est peut-être la gestion du routage des demandes. Les demandes doivent d'abord aller d'un utilisateur final vers une région choisie et acheminée d'une manière ou d'une autre. La demande rencontre une pile de services dans cette région, notamment une couche de calcul qui consiste peut-être en un équilibreur de charge soutenu par une AWS Lambda fonction, un conteneur ou un nœud Amazon Elastic Compute Cloud (Amazon EC2), et éventuellement d'autres services, notamment une autre base de données. Cette couche de calcul communique avec DynamoDB. Pour ce faire, elle doit utiliser le point de terminaison local de cette région. Les données de la table globale sont répliquées dans toutes les autres régions participantes et chaque région dispose d'une pile de services similaire autour de sa table DynamoDB.
La table globale fournit à chaque pile des différentes régions une copie locale des mêmes données. Vous pouvez envisager de concevoir une pile unique dans une seule région et prévoir de passer des appels distants vers le point de terminaison DynamoDB d'une région secondaire en cas de problème avec la table DynamoDB locale. Ce n'est pas la bonne pratique recommandée. Les latences associées au passage d'une région à une autre peuvent être 100 fois plus élevées que pour l'accès local. Une back-and-forth série de 5 requêtes peut prendre quelques millisecondes lorsqu'elle est exécutée localement, mais quelques secondes lorsqu'elle traverse le globe. Il est préférable d'acheminer le traitement de l'utilisateur final vers une autre région. Pour garantir la résilience, vous avez besoin d'une réplication entre plusieurs régions, avec une réplication de la couche de calcul ainsi que de la couche de données.
Il existe de nombreuses techniques alternatives pour acheminer une demande d'utilisateur final vers une région à des fins de traitement. Le choix optimal dépend de votre mode d'écriture et de vos considérations relatives au basculement. Cette section décrit quatre options : piloté par le client, couche de calcul, Route 53 et Global Accelerator.
Routage des demandes piloté par le client
Avec le routage des demandes piloté par le client, un client d'utilisateur final tel qu'une application ou une page Web avec un JavaScript autre client gardera une trace des points de terminaison valides de l'application. Dans ce cas, il s'agit de points de terminaison d'application tels qu'une Amazon API Gateway plutôt que de points de terminaison DynamoDB littéraux. Le client de l'utilisateur final utilise sa propre logique intégrée pour choisir la région avec laquelle communiquer. Il peut choisir de façon aléatoire, en fonction des latences les plus faibles observées, des mesures de bande passante les plus élevées observées ou des surveillances de l'état effectuées localement.
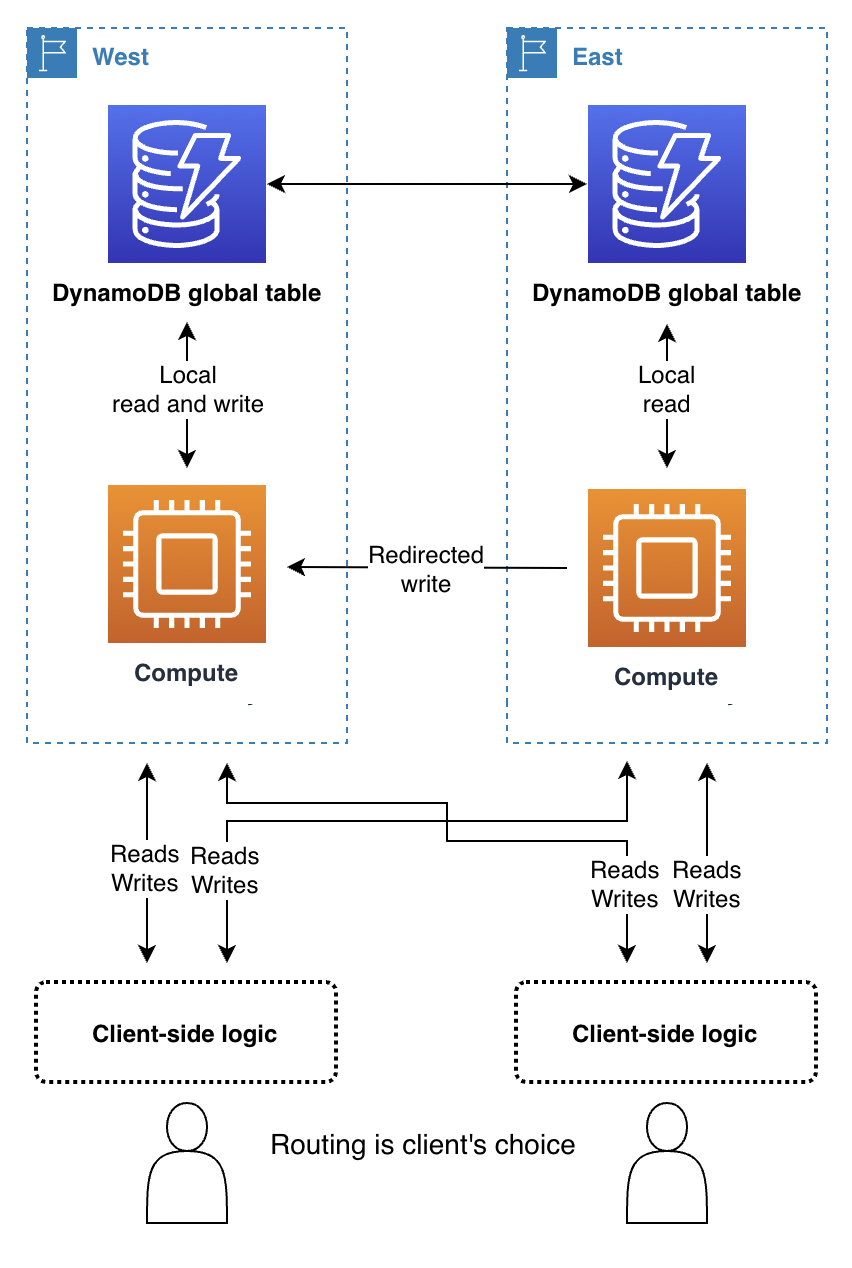
L'avantage du routage des demandes piloté par le client est qu'il peut s'adapter à des facteurs tels que les conditions réelles du trafic Internet public pour changer de région en cas de dégradation des performances. Le client doit connaître tous les points de terminaison potentiels, mais il n'est pas courant de lancer un nouveau point de terminaison régional.
Avec le mode Écrire dans n'importe quelle région, un client peut sélectionner unilatéralement son point de terminaison préféré. Si son accès à une région est perturbé, le client peut effectuer un routage vers un autre point de terminaison.
Avec le mode Écrire dans une région, le client aura besoin d'un mécanisme pour acheminer ses écritures vers la région actuellement active. Cela peut être aussi simple que de tester de façon empirique quelle région accepte actuellement les écritures (en notant tout rejet d'écriture et en revenant à une autre région) ou aussi complexe que d'appeler un coordinateur mondial pour demander l'état actuel de l'application (ce qui peut-être basé sur le contrôle de routage Route 53 Application Recovery Controller (ARC) qui fournit un système piloté par un quorum à 5 régions afin de maintenir l'état global pour des besoins tels que celui-ci). Le client peut décider si les lectures peuvent être acheminées vers n'importe quelle région pour une cohérence éventuelle ou si elles doivent être acheminées vers la région active pour une forte cohérence. Pour plus d'informations, consultez Fonctionnement de Route 53.
Avec le mode Écrire dans votre région, le client doit déterminer la région d'origine du jeu de données sur lequel il travaille. Par exemple, si le client correspond à un compte utilisateur et que chaque compte utilisateur est associé à une région, le client peut demander le point de terminaison approprié auprès d'un système de connexion global.
Par exemple, une entreprise de services financiers qui aide les utilisateurs à gérer les finances de leur entreprise via le Web peut utiliser des tables globales avec un mode Écrire dans votre région. Chaque utilisateur doit se connecter à un service central. Ce service renvoie les informations d'identification et le point de terminaison de la région dans laquelle ces informations d'identification fonctionnent. Les informations d'identification sont valides pendant une courte période. Ensuite, la page Web négocie automatiquement une nouvelle connexion, ce qui permet de rediriger potentiellement l'activité de l'utilisateur vers une nouvelle région.
Routage des demandes dans la couche de calcul
Avec le routage des demandes dans la couche de calcul, le code qui s'exécute dans la couche de calcul décide s'il souhaite traiter la demande localement ou la transmettre à une copie de lui-même qui s'exécute dans une autre région. Lorsque vous utilisez le mode Écrire dans une région, la couche de calcul peut détecter qu'il ne s'agit pas de la région active et autoriser les opérations de lecture locales tout en transférant toutes les opérations d'écriture vers une autre région. Ce code de couche de calcul doit tenir compte de la topologie des données et des règles de routage, et les appliquer de manière fiable en fonction des derniers paramètres qui spécifient quelles régions sont actives pour quelles données. La pile logicielle externe au sein de la région n'a pas besoin de savoir comment les demandes de lecture et d'écriture sont acheminées par le microservice. Dans une conception robuste, la région réceptrice vérifie s'il s'agit de la région principale actuelle pour l'opération d'écriture. Si ce n'est pas le cas, cela génère une erreur indiquant que l'état global doit être corrigé. La région réceptrice peut également mettre en mémoire tampon l'opération d'écriture pendant un certain temps si la région principale est en cours de modification. Dans tous les cas, la pile de calcul d'une région écrit uniquement sur son point de terminaison DynamoDB local, mais les piles de calcul peuvent communiquer entre elles.
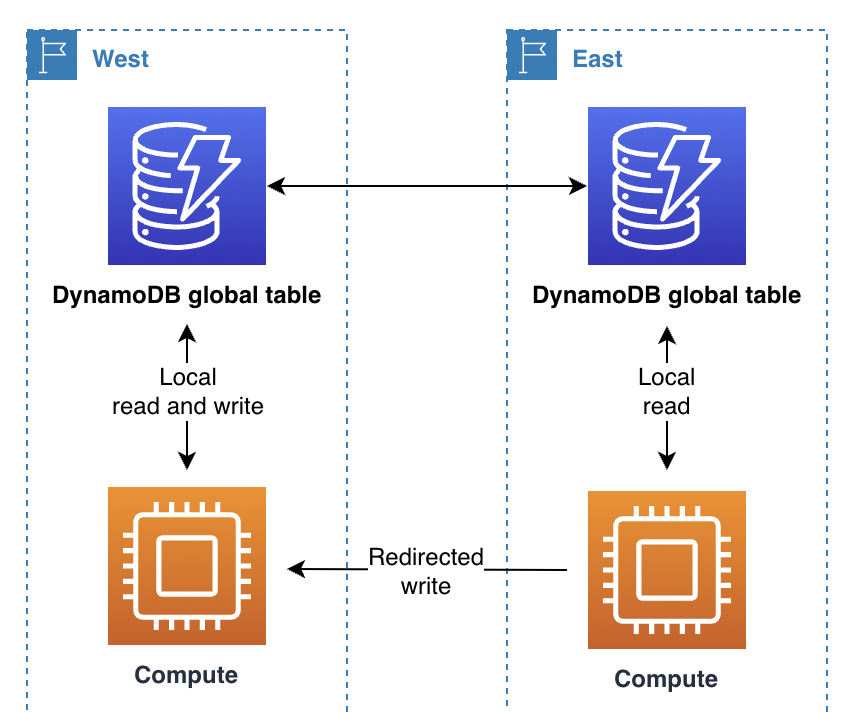
Dans ce scénario, supposons qu'une société de services financiers utilise un modèle principal follow-the-sun unique. Elle utilise un système et une bibliothèque pour ce processus de routage. Leur système global maintient l'état global, de la même manière que le contrôle AWS de routage ARC. Il utilise une table globale pour savoir quelle région est la région principale et quand le prochain commutateur principal est planifié. Toutes les opérations de lecture et d'écriture passent par la bibliothèque, qui se coordonne avec son système. La bibliothèque permet d'effectuer des opérations de lecture localement, avec une faible latence. Pour les opérations d'écriture, l'application vérifie si la région locale est la région principale actuelle. Si tel est le cas, l'opération d'écriture se termine directement. Dans le cas contraire, la bibliothèque transmet la tâche d'écriture à la bibliothèque située dans la région principale actuelle. Cette bibliothèque réceptrice confirme qu'elle se considère également comme la région principale et génère une erreur si ce n'est pas le cas, ce qui indique un délai de propagation par rapport à l'état global. Cette approche offre un avantage en matière de validation car elle ne permet pas d'écrire directement sur un point de terminaison DynamoDB distant.
Routage des demandes avec Route 53
Amazon Application Recovery Controller (ARC) est une technologie DNS (Domain Name Service). Avec Route 53, le client demande son point de terminaison en recherchant un nom de domaine DNS connu et Route 53 renvoie l'adresse IP correspondante au ou aux points de terminaison régionaux qu'il juge les plus appropriés. Route 53 dispose d'une liste de politiques de routage qu'elle utilise pour déterminer la région appropriée. Route 53 peut également effectuer un routage de basculement pour acheminer le trafic en dehors des régions où les surveillances de l'état échouent.
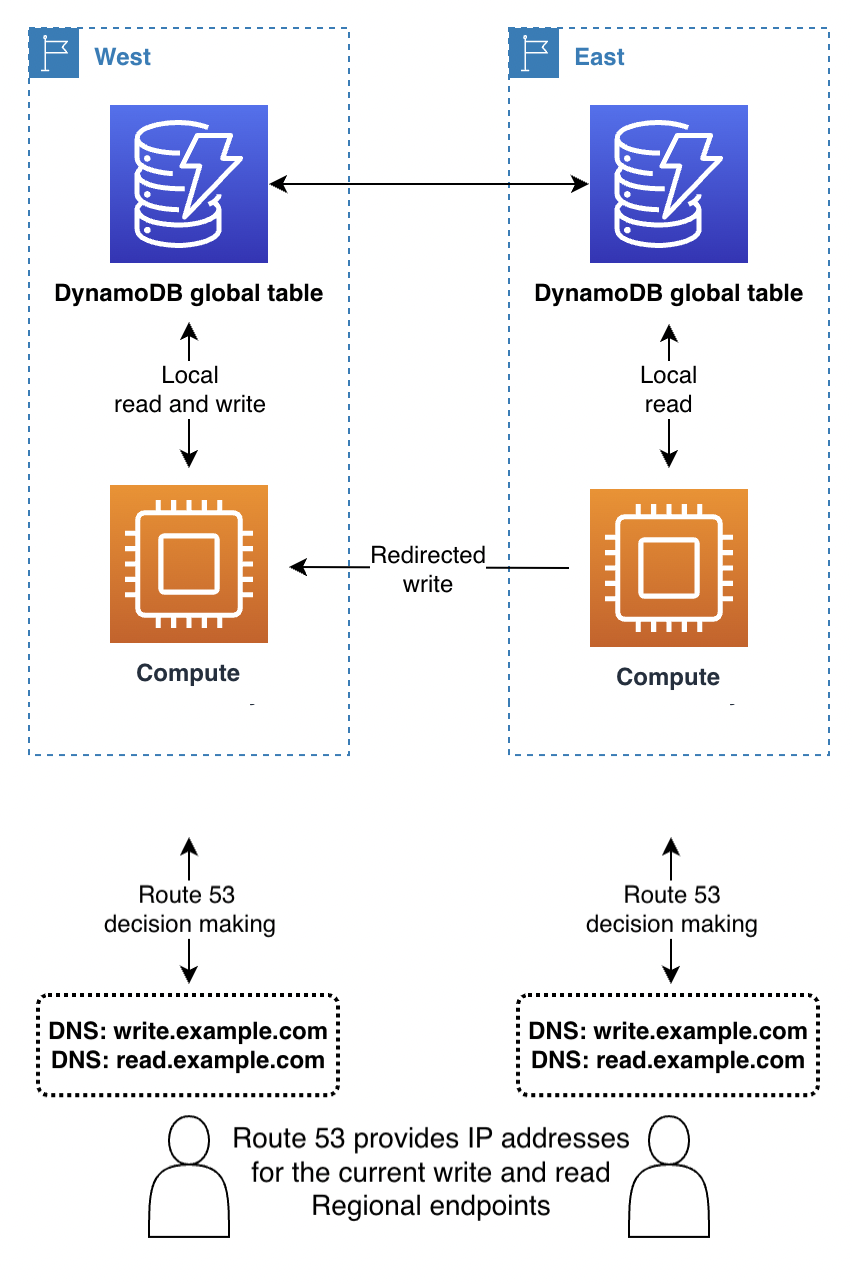
Avec le mode Écrire dans n'importe quelle région, ou en combinaison avec le routage des demandes dans la couche de calcul sur le back-end, Route 53 peut bénéficier d'un accès complet pour renvoyer la région en fonction de règles internes complexes, telles que la région la plus proche du réseau, la zone géographique la plus proche, ou tout autre choix.
Avec le mode Écrire dans une région, Route 53 peut être configuré pour renvoyer la région actuellement active (à l'aide de Route 53 ARC).
Note
Les clients mettent en cache les adresses IP figurant dans la réponse de Route 53 pendant une durée indiquée par le paramètre de durée de vie (TTL) du nom de domaine. Une durée de vie plus longue prolonge l'objectif de délai de reprise (RTO) pour que tous les clients puissent reconnaître le nouveau point de terminaison. Une valeur de 60 secondes est généralement utilisée pour un basculement. Tous les logiciels ne respectent pas parfaitement l'expiration de la durée de vie du DNS.
Avec le mode Écrire dans votre région, il est préférable d'éviter Route 53, sauf si vous utilisez également le routage des demandes dans la couche de calcul.
Routage des demandes avec Global Accelerator
Un client utilise AWS Global Accelerator
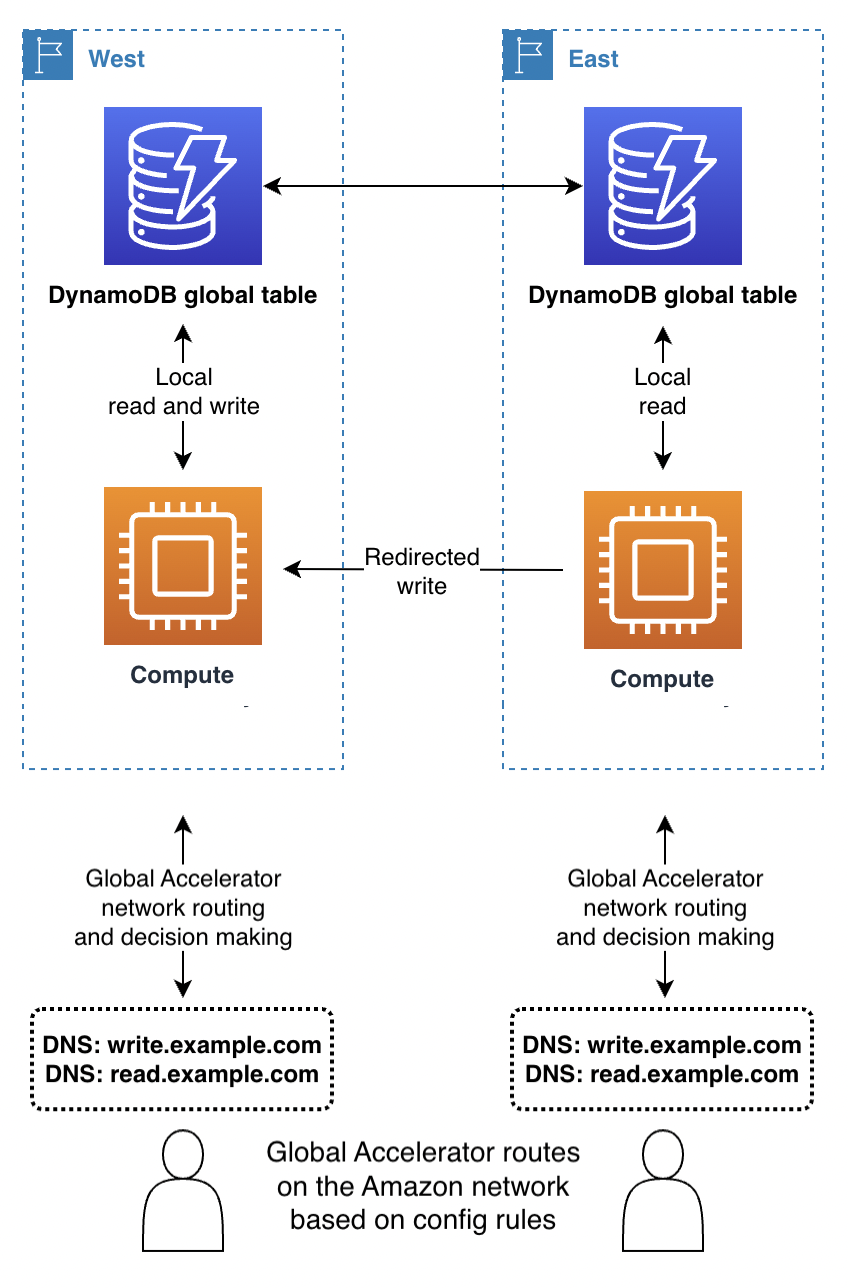
Avec le mode Écrire dans n'importe quelle région, ou s'il est associé au routage des demandes dans la couche de calcul sur le back-end, Global Accelerator fonctionne parfaitement. Le client se connecte à l'emplacement périphérique le plus proche et n'a pas à se soucier de savoir quelle région reçoit la demande.
Avec le mode Écrire dans une région, les règles de routage de Global Accelerator doivent envoyer des demandes à la région actuellement active. Vous pouvez utiliser des surveillances de l'état qui signalent artificiellement une défaillance dans une région qui n'est pas considérée par votre système global comme étant la région active. Comme avec DNS, il est possible d'utiliser un autre nom de domaine DNS pour acheminer les demandes de lecture si celles-ci peuvent provenir de n'importe quelle région.
Avec le mode Écrire dans votre région, il est préférable d'éviter Global Accelerator, sauf si vous utilisez également le routage des demandes dans la couche de calcul.
