Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation du sharding d'écriture de l'index secondaire global pour les requêtes de table sélectives dans DynamoDB
Les applications doivent fréquemment identifier un petit sous-ensemble d'éléments dans une table Amazon DynamoDB, qui répondent à une certaine condition. Lorsque ces éléments sont distribués de façon aléatoire sur les clés de partition de la table, vous pouvez recourir à une analyse de table pour les extraire. Cette option peut être coûteuse, mais elle fonctionne bien quand un grand nombre d'éléments sur la table répondent à la condition de recherche. Cependant, lorsque l'espace de clé est grand et que la condition de recherche est très sélective, cette politique peut entraîner beaucoup de traitement inutile.
Une meilleure solution peut consister à interroger les données. Pour activer les requêtes sélectives dans l'espace de clé entier, vous pouvez utiliser un partitionnement d'écriture en ajoutant un attribut contenant une valeur (0-N) à chaque élément que vous comptez utiliser pour la clé de partition d'index secondaire global.
Voici un exemple de schéma utilisant cette approche dans un flux d'événement critique :
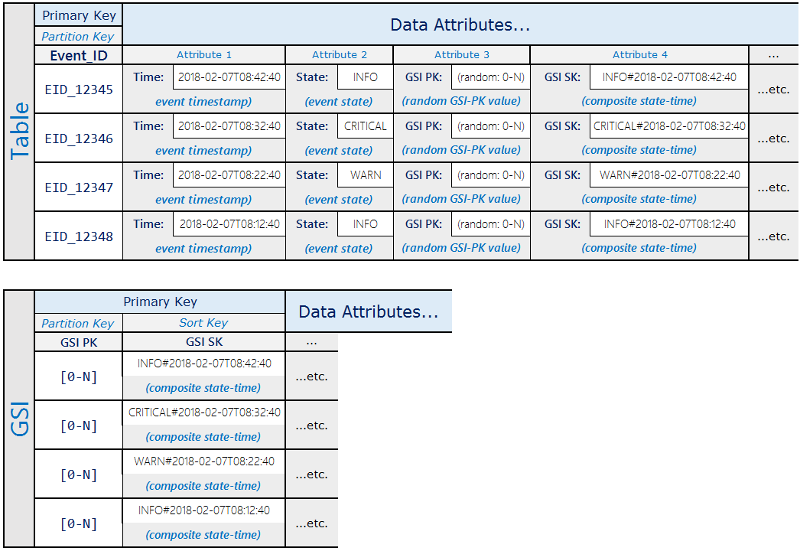
Grâce à cette conception de schéma, les éléments d'événement sont répartis sur les 0-N partitions duGSI, ce qui permet une lecture par dispersion à l'aide d'une condition de tri sur la clé composite pour récupérer tous les éléments ayant un état donné pendant une période spécifiée.
Ce modèle de schéma fournit un jeu de résultats hautement sélectif à un coût minimal, sans nécessiter d'analyse de table.
