Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Principes de base de la modélisation des données dans DynamoDB
Cette section s’intéresse à la couche de base en examinant les deux types de conception de table : à une seule table ou à plusieurs tables.
Principe de base de la conception à une seule table
Notre premier choix pour la base de notre schéma DynamoDB se porte sur la conception à une seule table. La conception à une seule table est un modèle qui vous permet de stocker plusieurs types (entités) de données dans une seule table DynamoDB. Elle vise à optimiser les modèles d’accès aux données, à améliorer les performances et à réduire les coûts en évitant de gérer plusieurs tables et les relations complexes entre elles. Cela est possible, car DynamoDB stocke les éléments dotés de la même clé de partition (appelée collection d’éléments) sur les mêmes partitions les uns que les autres. Dans cette conception, différents types de données sont stockés sous forme d’éléments dans la même table et chaque élément est identifié par une clé de tri unique.
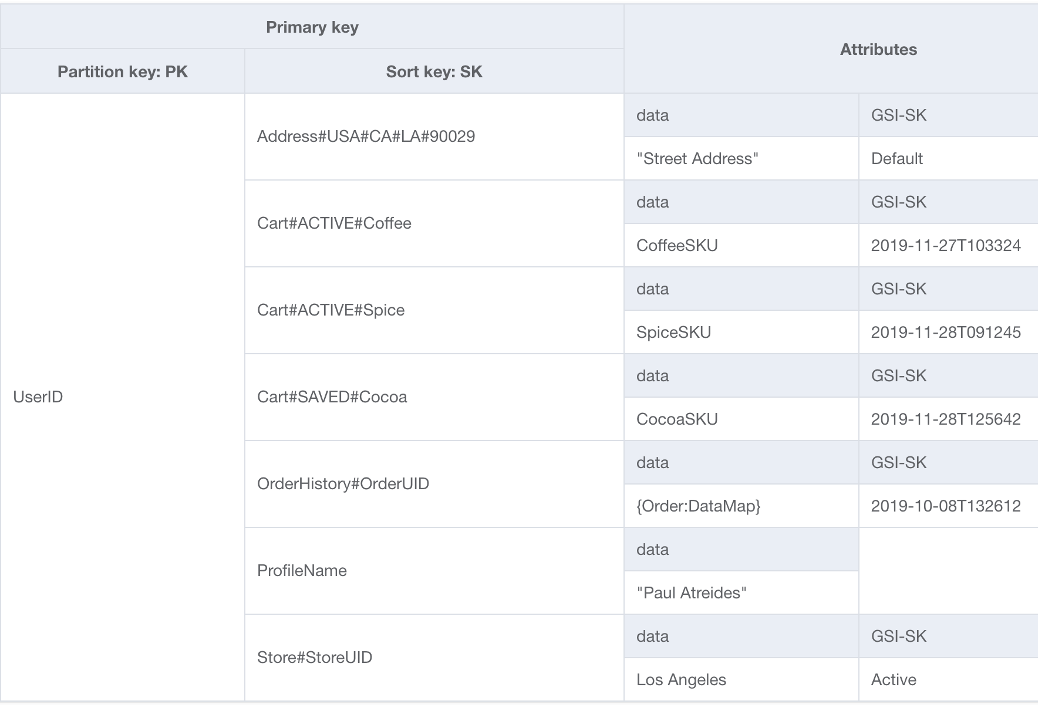
Avantages
-
Localité des données pour prendre en charge les requêtes relatives à plusieurs types d’entités lors d’un seul appel de base de données
-
Réduit les coûts financiers globaux et les coûts de latence liés aux lectures :
-
Une seule requête pour deux éléments d’un volume total inférieur à 4 ko équivaut à 0,5 RCU finalement cohérente
-
Deux requêtes pour deux éléments d’un volume total inférieur à 4 ko équivalent à 1 RCU finalement cohérente (0,5 RCU chacune)
-
La durée nécessaire pour renvoyer deux appels de base de données distincts sera en moyenne supérieure à celle d’un seul appel
-
-
Réduit le nombre de tables à gérer :
-
Il n’est pas nécessaire de conserver les autorisations entre plusieurs rôles ou politiques IAM
-
La gestion de la capacité de la table est calculée en moyenne pour toutes les entités, ce qui se traduit généralement par un modèle de consommation plus prévisible
-
La surveillance nécessite moins d’alarmes
-
Les clés de chiffrement gérées par le client ne doivent subir une rotation que sur une table
-
-
Facilite le trafic vers la table :
-
En agrégeant plusieurs modèles d’utilisation dans la même table, l’utilisation globale a tendance à être plus fluide (de la même manière que la performance d’un indice boursier a tendance à être plus fluide que celle d’une action individuelle), ce qui fonctionne mieux pour obtenir une utilisation plus élevée avec les tables en mode provisionné
-
Inconvénients
-
La courbe d’apprentissage peut être ardue en raison d’une conception paradoxale par rapport aux bases de données relationnelles
-
Les exigences en matière de données doivent être cohérentes pour tous les types d’entités
-
Pour les sauvegardes, c’est tout ou rien. Par conséquent, si certaines données ne sont pas essentielles à votre mission, pensez à les conserver dans une table séparée
-
Le chiffrement des tables est partagé entre tous les éléments. Pour les applications multilocataires avec des exigences de chiffrement de locataire individuel, un chiffrement côté client est requis
-
Les tables contenant à la fois des données historiques et des données opérationnelles ne tireront pas autant d’avantages de l’activation de la classe de stockage Accès peu fréquent. Pour de plus amples informations, consultez Classes de tables DynamoDB.
-
-
Toutes les données modifiées seront transmises à DynamoDB Streams, même si seul un sous-ensemble d’entités doit être traité.
-
Grâce aux filtres d’événements Lambda, cela n’affectera pas votre facture lorsque vous utiliserez Lambda, mais cela représentera un coût supplémentaire lorsque vous utiliserez Kinesis Consumer Library
-
-
Lors de l’utilisation de GraphQL, la conception à une seule table sera plus difficile à mettre en œuvre.
-
Lorsque vous utilisez des clients SDK de niveau supérieur tels que DynamoDBMapper de Java ou le client amélioré, le traitement des résultats peut s’avérer plus difficile, car les éléments d’une même réponse peuvent être associés à différentes classes
Quand l’utiliser
La conception à une seule table est indiquée pour les applications qui interrogent fréquemment plusieurs types d’entités ensemble ou qui ont besoin de maintenir des relations entre différents types de données. Elle est particulièrement efficace lorsque vos modèles d’accès tirent parti de la localisation des données et lorsque vous souhaitez minimiser les frais liés à la gestion de plusieurs tables.
Principe de base de la conception à plusieurs tables
Notre second choix pour la base de notre schéma DynamoDB se porte sur la conception à plusieurs tables. La conception à plusieurs tables est un modèle qui ressemble davantage à une conception de base de données traditionnelle dans laquelle vous stockez un seul type (entité) de données dans chaque table DynamoDB. Les données de chaque table seront toujours organisées par clé de partition, de sorte que les performances au sein d’un même type d’entité seront optimisées en termes de capacité de mise à l’échelle et de performance, mais les requêtes sur plusieurs tables devront être effectuées indépendamment.
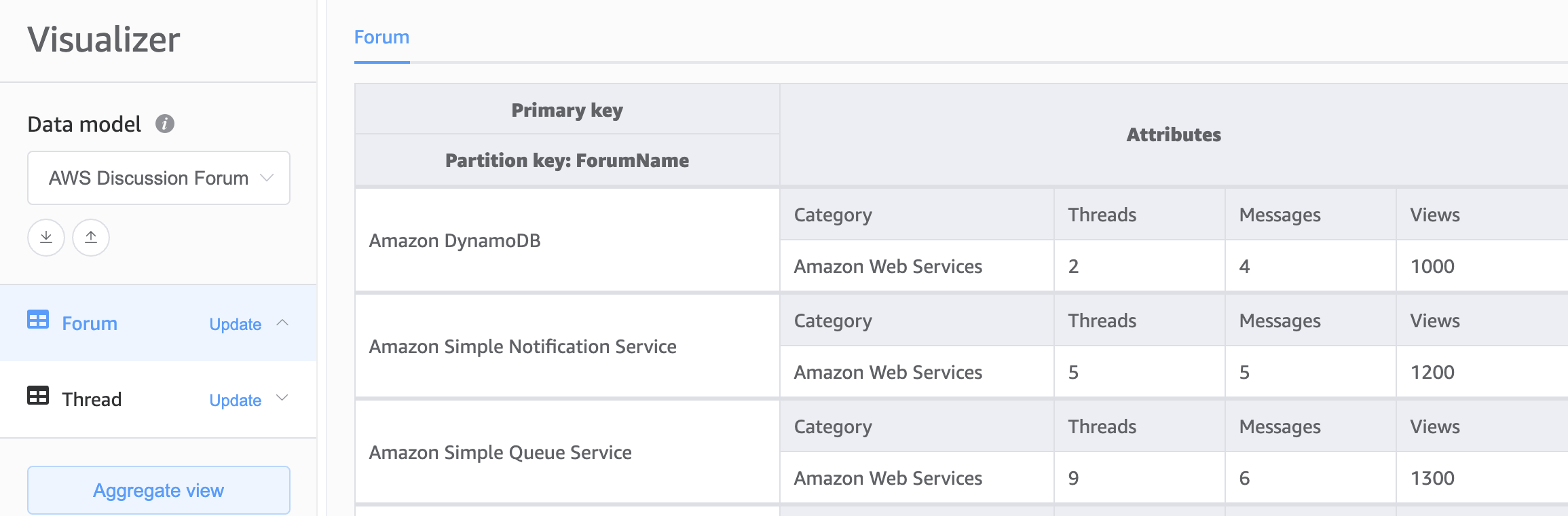
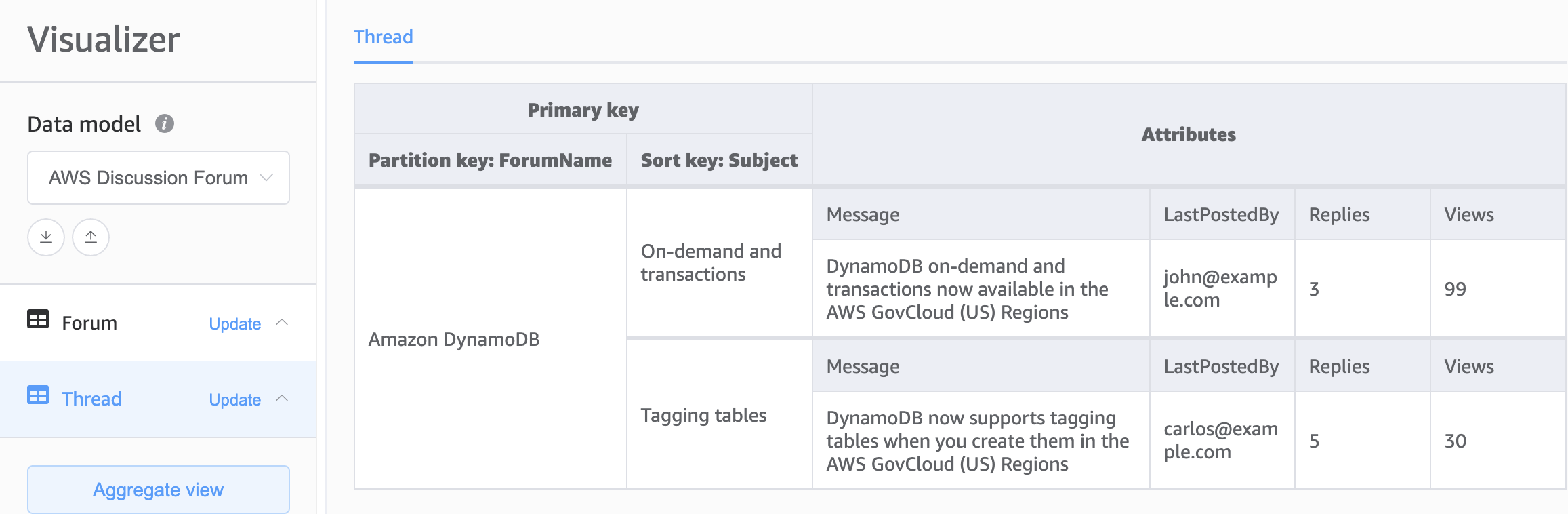
Avantages
-
Plus simple à concevoir pour qui n’a pas l’habitude d’utiliser la conception à une seule table.
-
Mise en œuvre simplifiée des résolveurs GraphQL grâce au mappage de chaque résolveur à une seule entité (table)
-
Permet de répondre à des exigences de données uniques pour différents types d’entités :
-
Possibilité d’effectuer des sauvegardes pour les tables individuelles qui sont essentielles à la mission
-
Le chiffrement des tables peut être géré pour chaque table. Pour les applications multilocataires ayant des exigences de chiffrement de locataire individuel, les tables de locataire distinctes permettent à chaque client d’avoir sa propre clé de chiffrement
-
La classe de stockage Accès peu fréquent peut être activée uniquement sur les tables contenant des données historiques afin de tirer pleinement parti des économies sur les coûts. Pour de plus amples informations, consultez Classes de tables DynamoDB.
-
-
Chaque table disposera de son propre flux de données de modification, ce qui permettra de concevoir une fonction Lambda dédiée pour chaque type d’élément plutôt qu’un seul processeur monolithique.
Inconvénients
-
Pour les modèles d'accès qui nécessitent des données sur plusieurs tables, plusieurs lectures depuis DynamoDB seront nécessaires et les données devront peut-être processed/joined figurer sur le code client.
-
Les opérations et la surveillance de plusieurs tables nécessitent davantage d' CloudWatch alarmes et chaque table doit être mise à l'échelle de manière indépendante
-
Les autorisations de chaque table devront être gérées séparément. L’ajout de tables à l’avenir exigera de modifier tous les rôles ou politiques IAM nécessaires.
Quand l’utiliser
Si les modèles d’accès de votre application n’ont pas besoin d’interroger simultanément plusieurs entités ou tables, la conception à plusieurs tables est une approche appropriée et suffisante.
