Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Conception de schéma de profil de jeu dans DynamoDB
Cas d'utilisation métier du profil de jeu
Ce cas d'utilisation décrit l'utilisation de DynamoDB pour stocker les profils des joueurs pour un système de jeu. Les utilisateurs (dans ce cas, les joueurs) doivent créer des profils avant de pouvoir interagir avec de nombreux jeux modernes, en particulier les jeux en ligne. Les profils de jeu incluent généralement les éléments suivants :
-
Informations de base telles que leur nom d'utilisateur
-
Données de jeu telles que les objets et l'équipement
-
Enregistrements de jeu tels que les tâches et les activités
-
Informations sociales telles que les listes d'amis
Pour satisfaire aux exigences précises en matière d'accès aux requêtes de données de cette application, les clés primaires (clé de partition et clé de tri) utiliseront des noms génériques (PK et SK) afin qu'elles puissent être surchargées de différents types de valeurs, comme nous le verrons ci-dessous.
Les modèles d'accès de cette conception de schéma sont les suivants :
-
Obtenir la liste d'amis d'un utilisateur
-
Obtenir toutes les informations d'un joueur
-
Obtenir la liste d'objets d'un utilisateur
-
Obtenir un objet spécifique de la liste d'objets de l'utilisateur
-
Mettre à jour le personnage d'un utilisateur
-
Mettre à jour le nombre d'objets d'un utilisateur
La taille du profil de jeu varie selon les jeux. La compression des valeurs d'attributs volumineuses permet de maintenir celles-ci dans les limites des éléments dans DynamoDB et de réduire les coûts. La stratégie de gestion du débit dépend de divers facteurs, tels que le nombre de joueurs, le nombre de parties jouées par seconde et la saisonnalité de la charge de travail. Généralement, pour un jeu récent, le nombre de joueurs et le niveau de popularité ne sont pas connus. Nous allons donc commencer par le mode de débit à la demande.
Diagramme des relations entre entités de profil de jeu
Il s'agit du diagramme de relation entre les entités (ERD) que nous utiliserons pour la conception du schéma des profils de jeu.
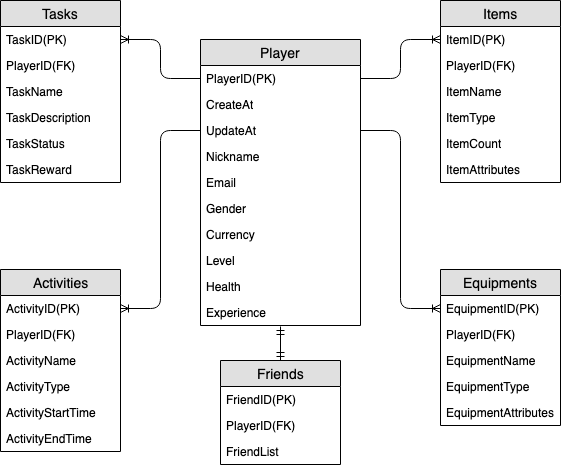
Modèles d'accès de profil de jeu
Voici les modèles d'accès que nous allons prendre en considération pour la conception du schéma de réseau social.
-
getPlayerFriends -
getPlayerAllProfile -
getPlayerAllItems -
getPlayerSpecificItem -
updateCharacterAttributes -
updateItemCount
Évolution de la conception du schéma de profil de jeu
D'après ce qui précèdeERD, nous pouvons voir qu'il s'agit d'un type de one-to-many relation de modélisation des données. Dans DynamoDB one-to-many, les modèles de données peuvent être organisés en collections d'éléments, ce qui est différent des bases de données relationnelles traditionnelles dans lesquelles plusieurs tables sont créées et liées par des clés étrangères. Une collection d'éléments est un groupe d'éléments qui partagent la même valeur de clé de partition, mais qui ont des valeurs de clé de tri différentes. Au sein d'une collection d'objets, chaque élément possède une valeur de clé de tri unique qui le distingue des autres éléments. Dans cette optique, utilisons le modèle suivant pour les valeurs HASH et RANGE pour chaque type d'entité.
Pour commencer, nous utilisons des noms génériques tels que PK et SK pour stocker différents types d'entités dans la même table et ainsi pérenniser le modèle. Pour une meilleure lisibilité, nous pouvons inclure des préfixes pour indiquer le type de données ou inclure un attribut arbitraire nommé Entity_type ou Type. Dans l'exemple actuel, nous utilisons une chaîne commençant par player pour stocker player_ID sous PK. Nous utilisons ensuite entity name# comme préfixe de SK et ajoutons un attribut Type pour indiquer le type d'entité auquel appartient cette donnée. Cela nous permet de prendre en charge le stockage d'un plus grand nombre de types d'entités à l'avenir et d'utiliser des technologies avancées telles que GSI Overloading et Sparse GSI pour répondre à davantage de modèles d'accès.
Commençons à implémenter les modèles d'accès. Les modèles d'accès tels que l'ajout de joueurs et l'ajout d'équipements peuvent être réalisés au cours de l'opération PutItem. Nous pouvons donc les ignorer. Dans ce document, nous allons nous concentrer sur les modèles d'accès typiques répertoriés ci-dessus.
Étape 1 : Traitement du modèle d'accès 1 (getPlayerFriends)
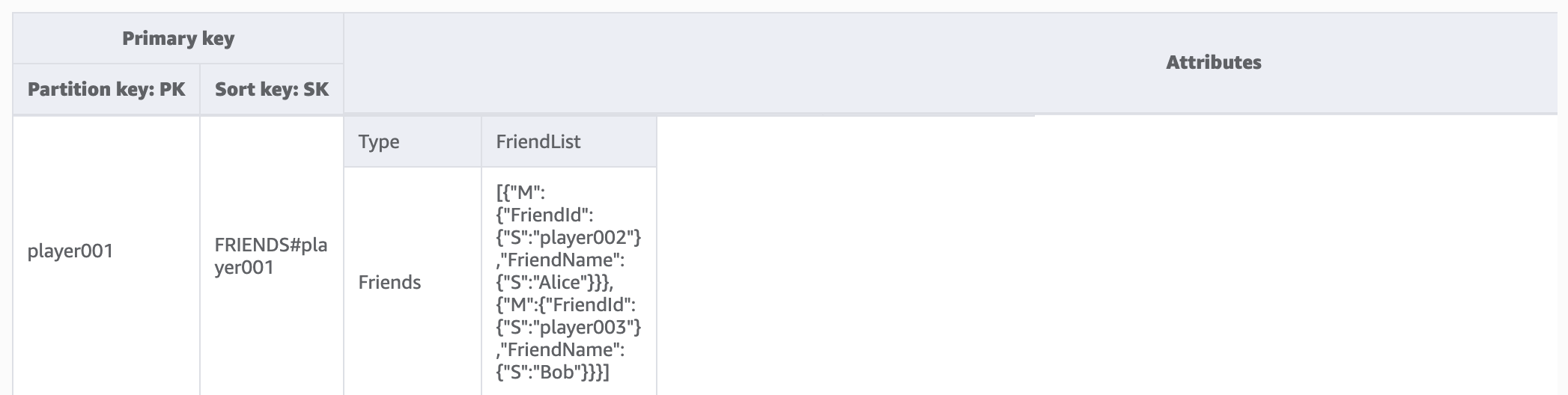
Lors de cette étape, nous traitons le modèle d'accès 1 (getPlayerFriends). Dans notre conception actuelle, l'amitié est simple et le nombre d'amis dans le jeu est réduit. Par souci de simplicité, nous utilisons un type de données de liste pour stocker les listes d'amis (modélisation 1:1). Dans cette conception, nous utilisons GetItem pour satisfaire ce modèle d'accès. Au cours de l'opération GetItem, nous fournissons explicitement la valeur de la clé de partition et de la clé de tri pour obtenir un élément spécifique.
Cependant, si un jeu compte un grand nombre d'amis et que les relations entre eux sont complexes (par exemple, les amitiés sont bidirectionnelles avec un composant d'invitation et d'acceptation), il serait nécessaire d'utiliser une many-to-many relation pour enregistrer chaque ami individuellement, afin d'atteindre une taille de liste d'amis illimitée. Et si le changement d'amitié implique d'opérer sur plusieurs éléments en même temps, les transactions DynamoDB peuvent être utilisées pour regrouper plusieurs actions et les soumettre en une all-or-nothing TransactWriteItemsseule opération. TransactGetItems
Étape 2 : Traitement des modèles d’accès 2 (getPlayerAllProfile), 3 (getPlayerAllItems) et 4 (getPlayerSpecificItem)
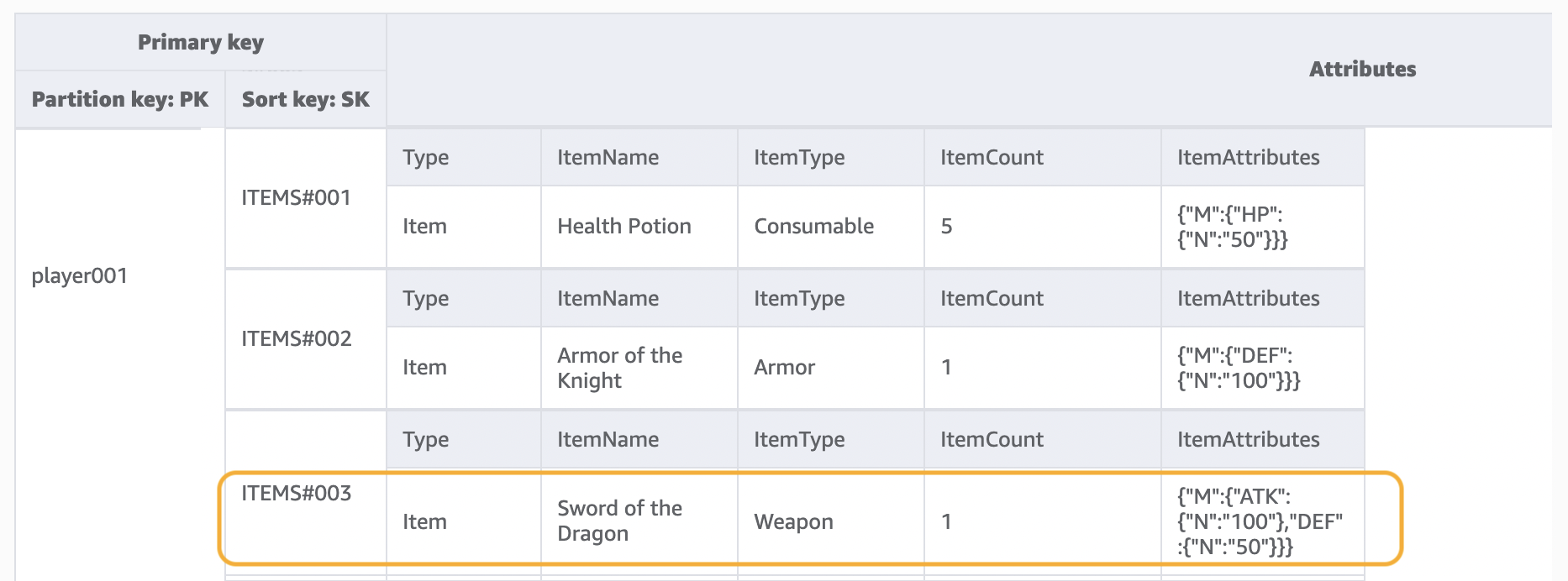
Lors de cette étape, nous traitons les modèles d'accès 2 (getPlayerAllProfile), 3 (getPlayerAllItems) et 4 (getPlayerSpecificItem). Ces trois modèles d'accès ont en commun une requête de plage qui utilise l'opération Query. En fonction de l'étendue de la requête, une condition de clé et des expressions de filtre sont utilisées. Elles sont couramment utilisées dans le développement pratique.
Dans l'opération Query, nous fournissons une valeur unique pour la clé de partition et nous obtenons tous les éléments avec cette valeur de clé de partition. Le modèle d'accès 2 (getPlayerAllProfile) est implémenté de cette manière. Nous pouvons éventuellement ajouter une expression de condition de clé de tri, c'est-à-dire une chaîne qui détermine les éléments à lire à partir de la table. Le modèle d'accès 3 (getPlayerAllItems) est implémenté en ajoutant la condition clé de la clé de tri begins_withITEMS#. De plus, afin de simplifier le développement côté application, nous pouvons utiliser des expressions de filtre pour implémenter le modèle d'accès 4 (getPlayerSpecificItem).
Voici un exemple de pseudo-code utilisant une expression de filtre qui filtre les éléments de la catégorie Weapon :
filterExpression: "ItemType = :itemType" expressionAttributeValues: {":itemType": "Weapon"}
Note
Une expression de filtre est appliquée après la fin de l'opération Query, mais avant que les résultats soient renvoyés au client. Par conséquent, une opération Query utilise la même capacité de lecture, qu'une expression de filtre soit présente ou non.
Si le modèle d'accès consiste à interroger un jeu de données volumineux et à filtrer une grande quantité de données pour ne conserver qu'un petit sous-ensemble de données, l'approche appropriée consiste à concevoir la clé de partition et la clé de tri DynamoDB de manière plus efficace. Par exemple, dans l'exemple ci-dessus pour obtenir un certain ItemType, s'il existe de nombreux éléments pour chaque joueur et que la recherche d'un certain ItemType est un modèle d'accès type, il serait plus efficace d’importer ItemType dans SK sous forme de clé composite. Le modèle de données ressemblerait à ceci : ITEMS#ItemType#ItemId.
Étape 3 : Traitement des modèles d'accès 5 (updateCharacterAttributes) et 6 (updateItemCount)
Lors de cette étape, nous traitons les modèles d'accès 5 (updateCharacterAttributes) et 6 (updateItemCount). Lorsque le joueur a besoin de modifier son personnage, pour réduire la monnaie ou modifier la quantité d'une arme dans ses objets, utilisez UpdateItem pour implémenter ces modèles d'accès. Pour mettre à jour la monnaie d'un joueur tout en veillant à ce qu'elle ne descende jamais en dessous d'un montant minimum, nous pouvons ajouter un élément Exemple d'expression de condition DynamoDB CLI pour réduire le solde uniquement s'il est supérieur ou égal au montant minimum. Voici un exemple de pseudo-code :
UpdateExpression: "SET currency = currency - :amount" ConditionExpression: "currency >= :minAmount"

Lors du développement avec DynamoDB et de l'utilisation de compteurs atomiques pour réduire l'inventaire, nous pouvons garantir l'idempotence en utilisant un verrouillage optimiste. Voici un exemple de pseudo-code pour les compteurs atomiques :
UpdateExpression: "SET ItemCount = ItemCount - :incr" expression-attribute-values: '{":incr":{"N":"1"}}'

De plus, dans un scénario où le joueur achète un objet avec de la monnaie, l'ensemble du processus doit déduire la monnaie et ajouter un objet en même temps. Nous pouvons utiliser les transactions DynamoDB pour regrouper plusieurs actions et les soumettre en tant all-or-nothing TransactWriteItems qu'opération unique. TransactGetItems TransactWriteItemsest une opération d'écriture synchrone et idempotente qui regroupe jusqu'à 100 actions d'écriture en une seule opération. all-or-nothing Les actions sont exécutées de manière atomique, de sorte qu'elles réussissent toutes ou aucune ne réussit. Les transactions contribuent à éliminer le risque de duplication ou de disparition de monnaie. Pour plus d'informations sur les transactions, consultez Exemple de transactions DynamoDB.
Tous les modèles d'accès et la façon dont ils sont traités par la conception du schéma sont résumés dans le tableau ci-dessous :
| Modèle d'accès | Table de base//GSILSI | Opération | Valeur de la clé de partition | Valeur de clé de tri | Autres conditions/filtres |
|---|---|---|---|---|---|
| getPlayerFriends | Table de base | GetItem | PK=PlayerID | SK = « FRIENDS #playerID » | |
| getPlayerAllProfil | Table de base | Requête | PK=PlayerID | ||
| getPlayerAllObjets | Table de base | Requête | PK=PlayerID | Le SK commence par « # » ITEMS | |
| getPlayerSpecificArticle | Table de base | Requête | PK=PlayerID | Le SK commence par « # » ITEMS | filterExpression: "ItemType = :itemType" expressionAttributeValues : {« : itemType « : « Arme »} |
| updateCharacterAttributes | Table de base | UpdateItem | PK=PlayerID | SK = « # METADATA #playerID » | UpdateExpression: "SETdevise = devise -:montant » ConditionExpression : « devise >= : » minAmount |
| updateItemCount | Table de base | UpdateItem | PK=PlayerID | SK = « ITEMS #ItemID » | expression-mise à jour : "SET ItemCount = ItemCount -:incr » expression-attribute-values : '{» :incr » : {"N » ⁄1"}}' |
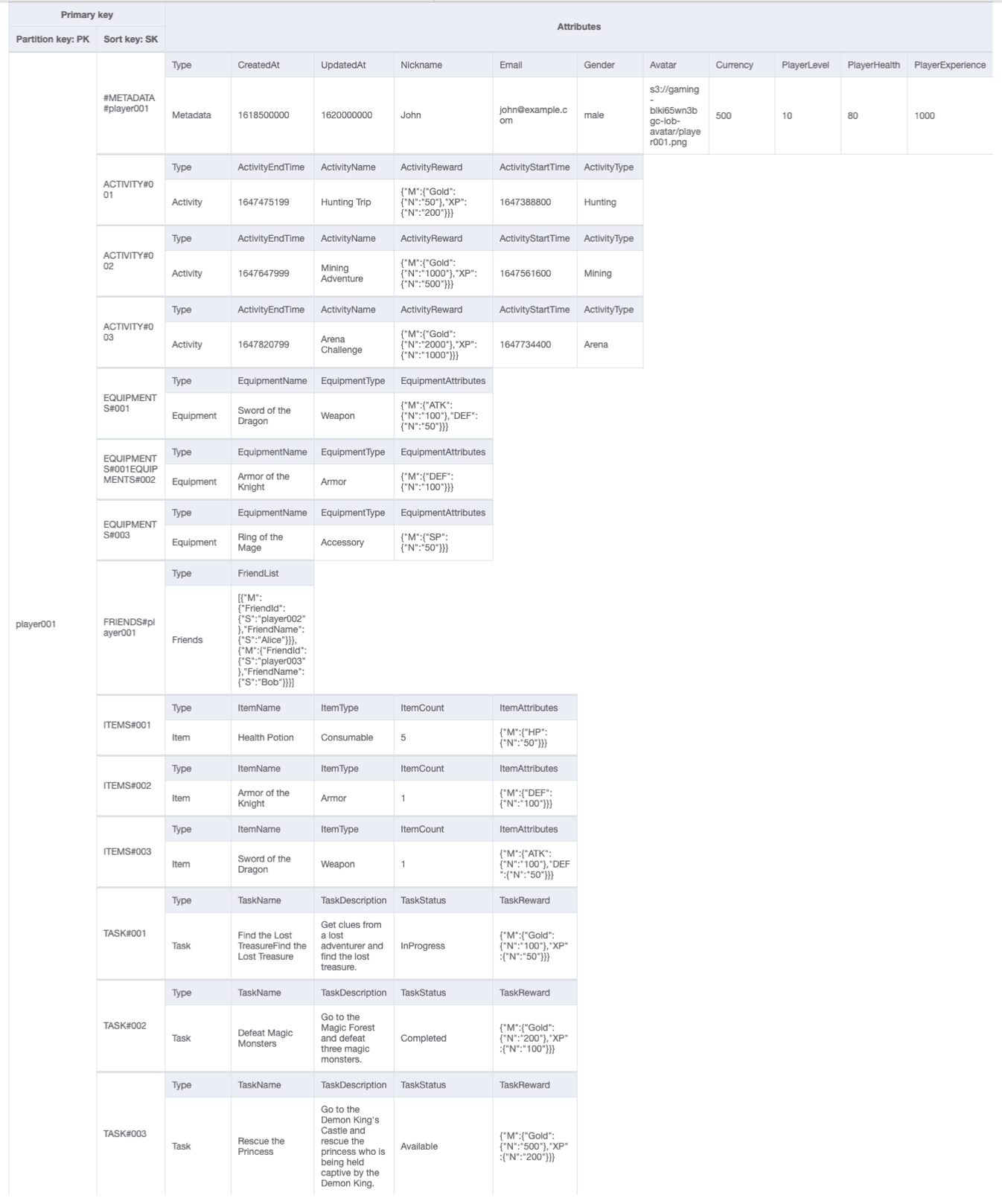
Schéma final de profil de jeu
Voici la conception du schéma final. Pour télécharger cette conception de schéma sous forme de JSON fichier, consultez les exemples DynamoDB
Table de base :
Utilisation de No SQL Workbench avec cette conception de schéma
Vous pouvez importer ce schéma final dans No SQL Workbench, un outil visuel qui fournit des fonctionnalités de modélisation des données, de visualisation des données et de développement de requêtes pour DynamoDB, afin d'explorer et de modifier davantage votre nouveau projet. Pour commencer, procédez comme suit :
-
Téléchargez No SQL Workbench. Pour de plus amples informations, veuillez consulter Télécharger No SQL Workbench pour DynamoDB.
-
Téléchargez le fichier de JSON schéma indiqué ci-dessus, qui est déjà au format du modèle No SQL Workbench.
-
Importez le fichier de JSON schéma dans No SQL Workbench. Pour de plus amples informations, veuillez consulter Importation d'un modèle de données existant.
-
Une fois que vous avez importé dans NOSQL Workbench, vous pouvez modifier le modèle de données. Pour de plus amples informations, veuillez consulter Modification d'un modèle de données existant.
-
Pour visualiser votre modèle de données, ajouter des exemples de données ou importer des exemples de données à partir d'un CSV fichier, utilisez la fonction de visualisation de données de No SQL Workbench.
