Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS AppSync présentation du modèle de mappage du résolveur
Note
Nous prenons désormais principalement en charge le runtime APPSYNC_JS et sa documentation. Pensez à utiliser le runtime APPSYNC_JS et ses guides ici.
AWS AppSync vous permet de répondre aux requêtes GraphQL en effectuant des opérations sur vos ressources. Pour chaque champ GraphQL sur lequel vous souhaitez exécuter une requête ou une mutation, un résolveur doit être attaché afin de communiquer avec une source de données. La communication s'effectue généralement par le biais de paramètres ou d'opérations propres à la source de données.
Les résolveurs sont les connecteurs entre GraphQL et une source de données. Ils expliquent AWS AppSync comment traduire une requête GraphQL entrante en instructions pour votre source de données principale, et comment traduire la réponse de cette source de données en réponse GraphQL. Ils sont écrits dans le langage de modèle Apache Velocity (VTL)
Il existe deux types de résolveurs AWS AppSync qui exploitent les modèles de mappage de manière légèrement différente :
-
Résolveurs d'unités
-
Résolveurs de pipelines
Résolveurs d'unités
Les résolveurs d'unités sont des entités autonomes qui incluent uniquement un modèle de demande et de réponse. Utilisez-les pour les opérations simples et uniques, comme lister des éléments à partir d'une seule source de données.
-
Modèles de demande : prenez la demande entrante après l'analyse d'une opération GraphQL et convertissez-la en une configuration de demande pour l'opération de source de données sélectionnée.
-
Modèles de réponses : interprétez les réponses de votre source de données et mappez-les à la forme du type de sortie du champ GraphQL.
Résolveurs de pipelines
Les résolveurs de pipeline contiennent une ou plusieurs fonctions exécutées dans un ordre séquentiel. Chaque fonction inclut un modèle de demande et un modèle de réponse. Un résolveur de pipeline possède également un modèle avant et un modèle après qui entourent la séquence de fonctions que le modèle contient. Le modèle After correspond au type de sortie du champ GraphQL. Les résolveurs de pipeline diffèrent des résolveurs d'unités dans la façon dont le modèle de réponse mappe la sortie. Un résolveur de pipeline peut mapper sur n'importe quelle sortie de votre choix, y compris l'entrée d'une autre fonction ou le modèle postérieur du résolveur de pipeline.
Les fonctions de résolution de pipeline vous permettent d'écrire une logique commune que vous pouvez réutiliser dans plusieurs résolveurs de votre schéma. Les fonctions sont associées directement à une source de données et, comme un résolveur d'unités, contiennent le même format de modèle de mappage de demandes et de réponses.
Le schéma suivant montre le flux de processus d'un résolveur d'unités sur la gauche et d'un résolveur de pipeline sur la droite.
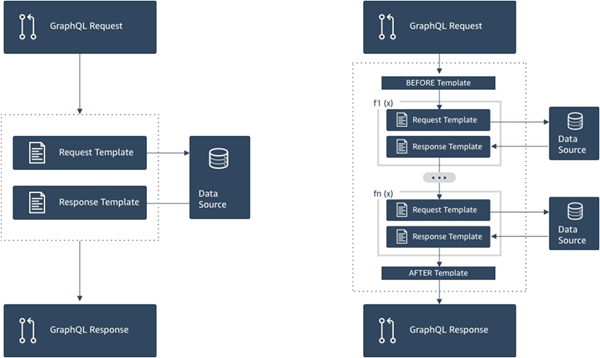
Les résolveurs de pipeline contiennent un surensemble des fonctionnalités prises en charge par les résolveurs unitaires, et bien plus encore, au prix d'un peu plus de complexité.
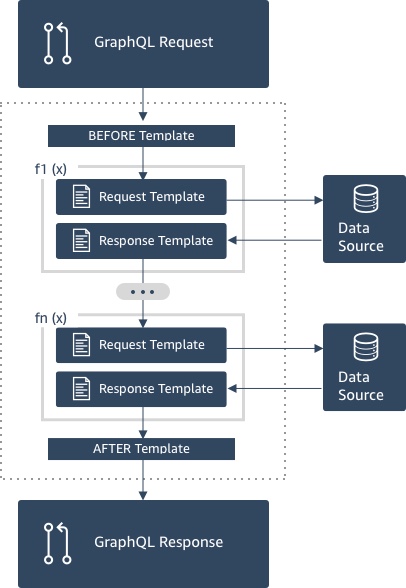
Anatomie d'un résolveur de pipeline
Un résolveur de pipeline est composé d'un modèle avant mappage, d'un modèle après mappage et d'une liste de fonctions. Chaque fonction possède un modèle de mappage de requêtes et de réponses qu'elle exécute par rapport à une source de données. Comme un résolveur de pipeline délègue l'exécution à une liste de fonctions, il n'est lié à aucune source de données. Les résolveurs d'unité et les fonctions sont des primitifs qui exécutent l'opération sur les sources de données. Consultez la présentation du modèle de mappage Resolver pour plus d'informations.
Avant le modèle de mappage
Le modèle de mappage de demandes d'un résolveur de pipeline, ou l'étape Before, vous permet d'exécuter une certaine logique de préparation avant d'exécuter les fonctions définies.
Liste des fonctions
La liste des fonctions d'un résolveur de pipeline est exécutée dans l'ordre. Le résultat évalué du modèle de mappage de demande du résolveur de pipeline est mis à disposition de la première fonction en tant que $ctx.prev.result. Chaque sortie d'une fonction est disponible pour la fonction suivante en tant que $ctx.prev.result.
Modèle de mappage Après
Le modèle de mappage des réponses d'un résolveur de pipeline, ou l'étape After, vous permet d'exécuter une logique de mappage finale entre la sortie de la dernière fonction et le type de champ GraphQL attendu. La sortie de la dernière fonction de la liste de fonctions est disponible dans le modèle de mappage du résolveur de pipeline en tant que $ctx.prev.result ou $ctx.result.
Flux d'exécution
Étant donné qu'un résolveur de pipeline est composé de deux fonctions, la liste ci-dessous représente le flux d'exécution lorsque le résolveur est invoqué :
-
Résolveur de pipeline avant le modèle de mappage
-
Fonction 1 : Modèle de mappage de demande de fonction
-
Fonction 1 : Appel de source de données
-
Fonction 1 : Modèle de mappage de réponse de fonction
-
Fonction 2 : Modèle de mappage de demande de fonction
-
Fonction 2 : Appel de source de données
-
Fonction 2 : Modèle de mappage de réponse de fonction
-
Résolveur de pipeline après le modèle de mappage
Note
Le flux d'exécution du résolveur de pipeline est unidirectionnel et défini de manière statique sur le résolveur.
Utilitaires VTL (Apache Velocity Template Language) utiles
À mesure qu'une application devient plus complexe, les utilitaires VTL et les directives permettent de faciliter la productivité de développement. Les utilitaires suivants peuvent vous aider si vous travaillez avec des résolveurs de pipeline.
$ctx.stash
Le stash est disponible dans chaque résolveur et chaque modèle de mappage de fonctions. Map La même instance stash perdure pendant une exécution de résolveur. Cela signifie que vous pouvez utiliser le stash pour transmettre des données arbitraires sur des modèles de mappage de demande et de réponse, et sur des fonctions dans un résolveur de pipeline. Le stash expose les mêmes méthodes que la structure de données cartographiques Java
$ctx.prev.result
Le $ctx.prev.result représente le résultat de l'opération précédente exécutée dans le résolveur de pipeline.
Si l'opération précédente était le modèle de mappage Before du résolveur de pipeline, elle $ctx.prev.result représente le résultat de l'évaluation du modèle et est mise à la disposition de la première fonction du pipeline. Si l'opération précédente est la première fonction, alors $ctx.prev.result représente le résultat de la première fonction et il est disponible pour la seconde fonction du pipeline. Si l'opération précédente était la dernière fonction, elle $ctx.prev.result représente la sortie de la dernière fonction et est mise à la disposition du modèle After mapping du résolveur de pipeline.
#return(data: Object)
La directive #return(data: Object) s'avère utile si vous avez besoin de revenir en arrière prématurément depuis un modèle de mappage. #return(data: Object) est analogue au mot clé return dans les langages de programmation, car il renvoie au bloc de logique à portée le plus proche. Cela signifie qu'utiliser #return dans un modèle de mappage de résolveur renvoie des données à partir du résolveur. L'utilisation de #return(data: Object) dans un modèle de mappage de résolveur définit data sur le champ GraphQL. De plus, l'utilisation de #return(data: Object) à partir d'un modèle de mappage de fonction renvoie des données à partir de la fonction et continue l'exécution vers la prochaine fonction du pipeline ou vers le modèle de mappage de réponse du résolveur.
#return
C'est la même chose que#return(data: Object), mais elle null sera renvoyée à la place.
$util.error
L'utilitaire $util.error est utile pour envoyer une erreur de champ. L'utilisation de $util.error dans un modèle de mappage de fonction envoie immédiatement une erreur de champ qui empêche l'exécution des fonctions suivantes. Pour plus de détails et pour d'autres $util.error signatures, consultez la référence de l'utilitaire de modèle de mappage Resolver.
$util.appendError
$util.appendError est similaire à $util.error(), avec une différence majeure : il n'interrompt pas l'évaluation du modèle de mappage. Au lieu de cela, il signale qu'une erreur s'est produite avec le champ, mais autorise l'évaluation du modèle et renvoie les données. L'utilisation de $util.appendError dans une fonction ne perturbera pas le flux d'exécution du pipeline. Pour plus de détails et pour d'autres $util.error signatures, consultez la référence de l'utilitaire de modèle de mappage Resolver.
Exemple de modèle
Supposons que vous disposiez d'une source de données DynamoDB et d'un résolveur d'unités dans un champ getPost(id:ID!) nommé qui renvoie Post un type avec la requête GraphQL suivante :
getPost(id:1){ id title content }
Votre modèle de résolveur peut ressembler à ce qui suit :
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : $util.dynamodb.toDynamoDBJson($ctx.args.id) } }
Ce modèle remplace la valeur du paramètre d'entrée id par 1 (au lieu de ${ctx.args.id}) et génère le code JSON suivant :
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : { "S" : "1" } } }
AWS AppSync utilise ce modèle pour générer des instructions permettant de communiquer avec DynamoDB et d'obtenir des données (ou d'effectuer d'autres opérations le cas échéant). Une fois les données renvoyées, AWS AppSync les exécute via un modèle de mappage de réponse facultatif que vous pouvez utiliser pour effectuer des opérations de mise en forme ou de logique sur les données. Par exemple, lorsque nous récupérons les résultats de DynamoDB, ils peuvent ressembler à ceci :
{ "id" : 1, "theTitle" : "AWS AppSync works offline!", "theContent-part1" : "It also has realtime functionality", "theContent-part2" : "using GraphQL" }
Vous pouvez choisir de regrouper deux des champs en un seul avec le modèle de mappage de réponse suivant :
{ "id" : $util.toJson($context.data.id), "title" : $util.toJson($context.data.theTitle), "content" : $util.toJson("${context.data.theContent-part1} ${context.data.theContent-part2}") }
Voici comment les données sont formatées une fois que le modèle leur a été appliqué :
{ "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" }
Ces données sont renvoyées au client sous forme de réponse comme suit :
{ "data": { "getPost": { "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" } } }
Notez que, dans la plupart des cas, les modèles de mappage de réponse sont une simple transmission de données, lesquels sont surtout différents si vous renvoyez un élément individuel ou une liste d'éléments. Pour un élément individuel, la transmission est :
$util.toJson($context.result)
Pour une liste, la transmission est généralement :
$util.toJson($context.result.items)
Pour voir d'autres exemples de résolveurs unitaires et de résolveurs de pipeline, consultez les didacticiels sur les résolveurs.
Règles de désérialisation des modèles de mappage évalués
Les modèles de mappage sont évalués selon une chaîne. Dans AWS AppSync, la chaîne de sortie doit suivre une structure JSON pour être valide.
En outre, les règles de désérialisation suivantes sont appliquées.
Les clés en double ne sont pas autorisées dans les objets JSON
Si la chaîne de modèle de mappage évaluée représente un objet JSON ou contient un objet qui contient des clés en double, le modèle de mappage renvoie le message d'erreur suivant :
Duplicate field 'aField' detected on Object. Duplicate JSON keys are not
allowed.
Exemple de clé en double dans un modèle de mappage de demande évalué :
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", "field": "getPost" ## key 'field' has been redefined } }
Pour corriger cette erreur, ne redéfinissez pas les clés dans les objets JSON.
Les caractères de fin ne sont pas autorisés dans les objets JSON
Si la chaîne de modèle de mappage évaluée représente un objet JSON et contient des caractères de fin étrangers, le modèle de mappage renvoie le message d'erreur suivant :
Trailing characters at the end of the JSON string are not allowed.
Exemple de caractères de fin dans un modèle de mappage de demande évalué :
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", } }extraneouschars
Pour corriger cette erreur, assurez-vous que les modèles évalués sont strictement conformes au JSON.
