Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utiliser EXPLAIN et EXPLAIN ANALYZE dans Athéna
L'EXPLAINinstruction montre le plan d'exécution logique ou distribué d'une SQL instruction spécifiée, ou valide l'SQLinstruction. Vous pouvez produire les résultats au format texte ou dans un format de données pour les intégrer dans un graphique.
Note
Vous pouvez afficher des représentations graphiques des plans logiques et distribués pour vos requêtes dans la console Athena sans utiliser la syntaxe EXPLAIN. Pour de plus amples informations, veuillez consulter Afficher les plans d'exécution des SQL requêtes.
L'EXPLAIN ANALYZEinstruction indique à la fois le plan d'exécution distribué d'une SQL instruction spécifiée et le coût de calcul de chaque opération d'une SQL requête. Vous pouvez afficher les résultats sous forme de texte ou de JSON format.
Considérations et restrictions
Les instructions EXPLAIN et EXPLAIN ANALYZE sur Athena ont les limitations suivantes.
-
Comme les requêtes
EXPLAINn'analysent pas de données, Athena ne les facture pas. Cependant, étant donné que les requêtesEXPLAINeffectuent des appels vers AWS Glue pour récupérer les métadonnées des tables, vous pouvez encourir des frais de la part de Glue si les appels dépassent la limite de l'offre gratuite de Glue. -
Étant donné que les requêtes
EXPLAIN ANALYZEsont exécutées, elles analysent les données et Athena facture la quantité de données analysées. -
Les informations de filtrage des lignes ou des cellules définies dans Lake Formation et les informations sur les statistiques des requêtes n'apparaissent pas dans la sortie de
EXPLAINetEXPLAIN ANALYZE.
EXPLAINsyntaxe
EXPLAIN [ (option[, ...]) ]statement
option peut être l'une des suivantes :
FORMAT { TEXT | GRAPHVIZ | JSON } TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
Si l'option FORMAT n'est pas spécifiée, la sortie se fait par défaut au format TEXT. Le IO type fournit des informations sur les tables et les schémas lus par la requête. IOn'est pris en charge que dans la version 2 du moteur Athena et ne peut être renvoyé qu'au JSON format.
EXPLAINANALYZEsyntaxe
Outre la sortie incluseEXPLAIN, EXPLAIN
ANALYZE la sortie inclut également les statistiques d'exécution pour la requête spécifiée, telles que CPU l'utilisation, le nombre de lignes en entrée et le nombre de lignes en sortie.
EXPLAIN ANALYZE [ (option[, ...]) ]statement
option peut être l'une des suivantes :
FORMAT { TEXT | JSON }
Si l'option FORMAT n'est pas spécifiée, la sortie se fait par défaut au format TEXT. Parce que toutes les requêtes pour EXPLAIN ANALYZE sont DISTRIBUTED, l'option TYPE n'est pas disponible pour EXPLAIN ANALYZE.
statement peut être l'une des suivantes :
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
EXPLAINexemples
Les exemples suivants pour EXPLAIN vont du plus simple au plus complexe.
Dans l'exemple suivant, EXPLAIN affiche le plan d'exécution d'une requête SELECT sur les journaux Elastic Load Balancing. Le format est défini par défaut sur la sortie de texte.
EXPLAIN SELECT request_timestamp, elb_name, request_ip FROM sampledb.elb_logs;
Résultats
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULARVous pouvez utiliser la console Athena pour représenter graphiquement un plan de requête pour vous. Entrez une SELECT instruction comme celle-ci dans l'éditeur de requêtes Athena, puis choisissez. EXPLAIN
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey
La page EXPLAIN de l'éditeur de requêtes Athena s'ouvre et affiche un plan distribué et un plan logique pour la requête. Le graphique suivant montre le plan logique de l'exemple.
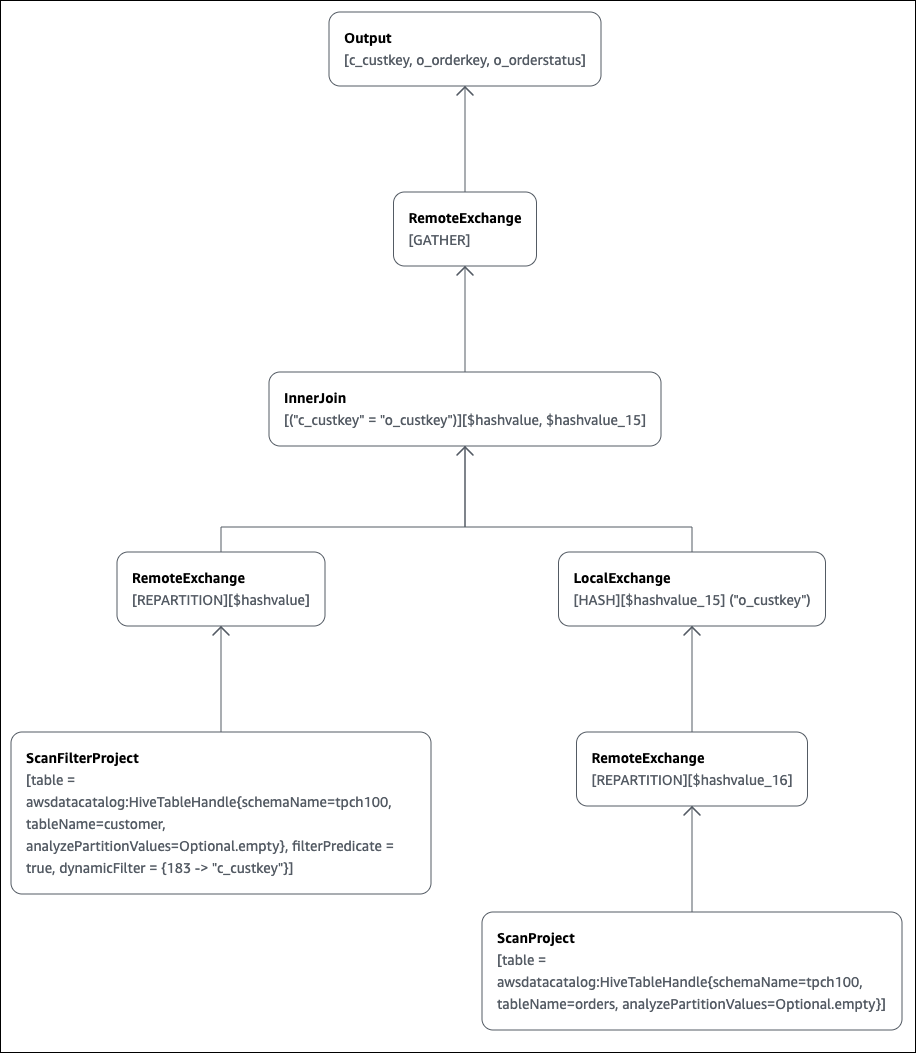
Important
Actuellement, certains filtres de partition peuvent ne pas être visibles dans l'arborescence des opérateurs imbriqués même si Athena les applique à votre requête. Pour vérifier l'effet de tels filtres, exécutez EXPLAIN ou EXPLAIN
ANALYZE sur votre requête et affichez les résultats.
Pour plus d'informations sur l'utilisation des fonctionnalités de graphique du plan de requête dans la console Athena, consultez Afficher les plans d'exécution des SQL requêtes.
Lorsque vous utilisez un prédicat de filtrage sur une clé partitionnée pour effectuer une requête sur une table partitionnée, le moteur de requête applique le prédicat à la clé partitionnée afin de réduire la quantité de données lues.
L'exemple suivant utilise une requête EXPLAIN pour vérifier l'élagage des partitions pour une requête SELECT sur une table partitionnée. Tout d'abord, une instruction CREATE TABLE crée la table tpch100.orders_partitioned. La table est partitionnée sur la colonne o_orderdate.
CREATE TABLE `tpch100.orders_partitioned`( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) PARTITIONED BY ( `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/<your_directory_path>/'
La table tpch100.orders_partitioned a plusieurs partitions sur o_orderdate, comme le montre la commande SHOW PARTITIONS.
SHOW PARTITIONS tpch100.orders_partitioned; o_orderdate=1994 o_orderdate=2015 o_orderdate=1998 o_orderdate=1995 o_orderdate=1993 o_orderdate=1997 o_orderdate=1992 o_orderdate=1996
La requête EXPLAIN suivante vérifie l'élagage des partitions sur l'instruction SELECT spécifiée.
EXPLAIN SELECT o_orderkey, o_custkey, o_orderdate FROM tpch100.orders_partitioned WHERE o_orderdate = '1995'
Résultats
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARLe texte en gras dans le résultat montre que le prédicat o_orderdate =
'1995' a été appliqué sur la PARTITION_KEY.
La requête EXPLAIN suivante vérifie l'ordre et le type de jointure de l'instruction SELECT. Utilisez une requête comme celle-ci pour examiner l'utilisation de la mémoire de la requête afin de réduire les risques d'erreur EXCEEDED_LOCAL_MEMORY_LIMIT.
EXPLAIN (TYPE DISTRIBUTED) SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
Résultats
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARLa requête donnée en exemple a été optimisée en une jointure croisée pour une meilleure performance. Les résultats montrent que tpch100.orders sera distribué comme le type de distribution BROADCAST. Cela implique que la table tpch100.orders sera distribuée à tous les nœuds qui effectuent l'opération de jointure. Le type de distribution BROADCAST exigera que tous les résultats filtrés de la table tpch100.orders tiennent dans la mémoire de chaque nœud qui effectue l'opération de jointure.
Cependant, la table tpch100.customer est plus petite que tpch100.orders. Comme tpch100.customer nécessite moins de mémoire, vous pouvez réécrire la requête en BROADCAST
tpch100.customer au lieu de tpch100.orders. Cela réduit le risque que la requête reçoive une erreur EXCEEDED_LOCAL_MEMORY_LIMIT. Cette politique suppose les points suivants :
-
La
tpch100.customer.c_custkeyest unique dans la tabletpch100.customer. -
Il existe une relation one-to-many cartographique entre
tpch100.customerettpch100.orders.
L'exemple suivant illustre la requête réécrite.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.orders o JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes. ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
Vous pouvez utiliser une requête EXPLAIN pour vérifier l'efficacité du filtrage des prédicats. Vous pouvez utiliser les résultats pour supprimer les prédicats qui n'ont aucun effet, comme dans l'exemple suivant.
EXPLAIN SELECT c.c_name FROM tpch100.customer c WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT) AND c.c_custkey BETWEEN 1000 AND 2000 AND c.c_custkey = 1500
Résultats
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULARLe filterPredicate dans les résultats montre que l'optimiseur a fusionné les trois prédicats d'origine en deux prédicats et a changé leur ordre d'application.
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
Comme les résultats montrent que le prédicat AND c.c_custkey BETWEEN
1000 AND 2000 n'a aucun effet, vous pouvez supprimer ce prédicat sans modifier les résultats de la requête.
Pour plus d'informations sur les termes utilisés dans les résultats des requêtes EXPLAIN, voir Comprendre les résultats de la déclaration d'Athéna EXPLAIN.
EXPLAINANALYZEexemples
Les exemples suivants montrent des exemples de requêtes et de sorties EXPLAIN ANALYZE.
L'exemple suivant EXPLAIN ANALYZE montre le plan d'exécution et les coûts de calcul d'une SELECT requête sur les CloudFront journaux. Le format est défini par défaut sur la sortie de texte.
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
Résultats
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULARL'exemple suivant montre le plan d'exécution et les coûts de calcul d'une SELECT requête sur les CloudFront journaux. L'exemple indique JSON le format de sortie.
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
Résultats
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}Ressources supplémentaires
Pour plus d'informations, consultez les ressources suivantes.
-
Afficher les statistiques et les détails d'exécution des requêtes terminées
-
Documentation Trino
EXPLAIN -
Documentation Trino
EXPLAIN ANALYZE -
Optimisez les performances des requêtes fédérées à l'aide EXPLAIN et EXPLAIN ANALYZE dans Amazon
Athena sur AWS le blog Big Data.
