Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur Amazon Athena pour Timestream
Le connecteur Amazon Athena pour Timestream permet à Amazon Athena de communiquer avec Amazon Timestream
Amazon Timestream est une base de données de séries temporelles rapide, évolutive, entièrement gérée et spécialement conçue pour faciliter le stockage et l'analyse de milliers de milliards de points de données en séries chronologiques par jour. Timestream vous fait gagner du temps et réduire les coûts de gestion du cycle de vie des données en séries chronologiques en conservant les données récentes en mémoire et en déplaçant les données historiques vers un niveau de stockage à coût optimisé en fonction des politiques définies par l'utilisateur.
Ce connecteur peut être enregistré auprès de Glue Data Catalog en tant que catalogue fédéré. Il prend en charge les contrôles d'accès aux données définis dans Lake Formation au niveau du catalogue, de la base de données, de la table, des colonnes, des lignes et des balises. Ce connecteur utilise Glue Connections pour centraliser les propriétés de configuration dans Glue.
Si Lake Formation est activé sur votre compte, le rôle IAM de votre connecteur Lambda fédéré Athena que vous avez déployé dans AWS Serverless Application Repository le doit avoir un accès en lecture dans Lake Formation au. AWS Glue Data Catalog
Prérequis
Déployez le connecteur sur votre Compte AWS à l’aide de la console Athena ou du AWS Serverless Application Repository. Pour plus d’informations, consultez Création d'une connexion à une source de données ou Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données.
Paramètres
Utilisez les paramètres de cette section pour configurer le connecteur Timestream.
Configuration de bases de données et de tables dans AWS Glue
Vous pouvez éventuellement utiliser le AWS Glue Data Catalog comme source de métadonnées supplémentaires. Pour activer une AWS Glue table à utiliser avec Timestream, vous devez disposer d'une AWS Glue base de données et d'une table dont les noms correspondent à la base de données Timestream et à la table pour laquelle vous souhaitez fournir des métadonnées supplémentaires.
Note
Pour des performances optimales, n'utilisez que des minuscules pour vos noms de bases de données et de tables. L'utilisation d'une casse mixte oblige le connecteur à effectuer une recherche insensible à la casse, ce qui demande plus de temps de calcul.
Pour configurer AWS Glue une table à utiliser avec Timestream, vous devez définir ses propriétés dans. AWS Glue
Pour utiliser une AWS Glue table pour des métadonnées supplémentaires
-
Modifiez le tableau dans la AWS Glue console pour ajouter les propriétés de tableau suivantes :
timestream-metadata-flag— Cette propriété indique au connecteur Timestream que le connecteur peut utiliser la table pour des métadonnées supplémentaires. Vous pouvez fournir n’importe quelle valeur pour
timestream-metadata-flagtant que la propriététimestream-metadata-flagest présente dans la liste des propriétés de la table.-
_view_template – Lorsque vous utilisez AWS Glue pour des métadonnées supplémentaires, vous pouvez utiliser cette propriété de table et spécifier n’importe quel SQL Timestream en tant que vue. Le connecteur Athena Timestream utilise le SQL de la vue avec votre SQL d’Athena pour exécuter votre requête. Cela s’avère utile si vous souhaitez utiliser une fonctionnalité de Timestream SQL qui n’est pas disponible dans Athena.
-
Assurez-vous d'utiliser les types de données appropriés AWS Glue tels que listés dans ce document.
Types de données
Actuellement, le connecteur Timestream ne prend en charge qu’un sous-ensemble des types de données disponibles dans Timestream, en particulier les valeurs scalaires varchar, double et timestamp.
Pour interroger le type de données timeseries, vous devez configurer une vue dans les propriétés de la table AWS Glue
qui utilise la fonction CREATE_TIME_SERIES de Timestream. Vous devez également fournir un schéma pour la vue qui utilise la syntaxe ARRAY<STRUCT<time:timestamp,measure_value::double:double>> comme type pour n’importe laquelle de vos colonnes de séries chronologiques. Assurez-vous de remplacer double par le type scalaire approprié pour votre table.
L'image suivante montre un exemple de propriétés de AWS Glue table configurées pour configurer une vue sur une série chronologique.
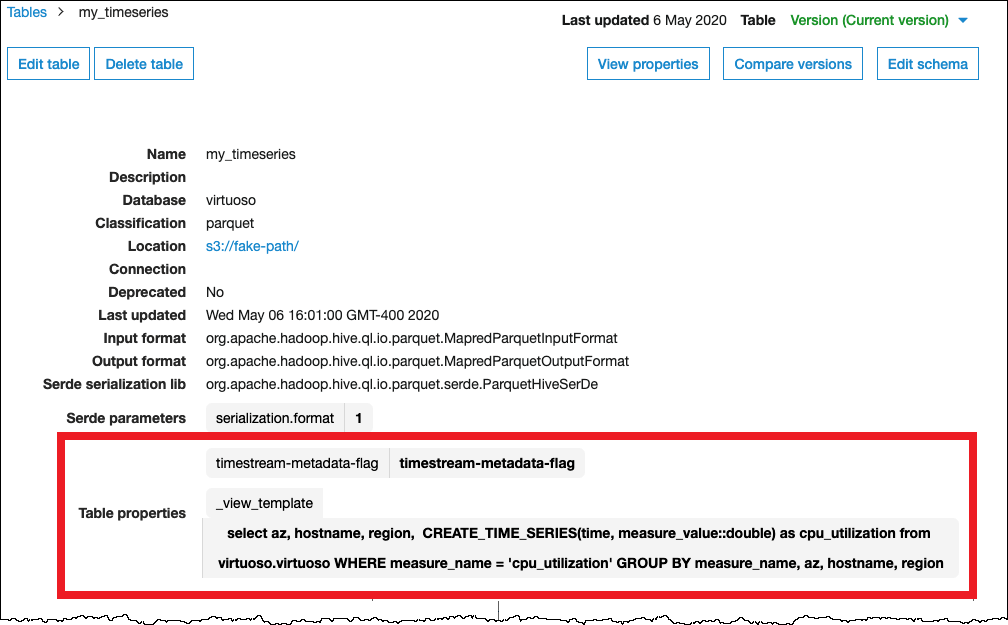
Autorisations nécessaires
Pour plus de détails sur les politiques IAM requises par ce connecteur, reportez-vous à la section Policies du fichier athena-timestream.yaml
-
Amazon S3 write access (Accès en écriture Amazon S3) – Le connecteur nécessite un accès en écriture à un emplacement dans Amazon S3 pour déverser les résultats à partir de requêtes volumineuses.
-
Athena GetQueryExecution — Le connecteur utilise cette autorisation pour échouer rapidement lorsque la requête Athena en amont est terminée.
-
AWS Glue Data Catalog— Le connecteur Timestream nécessite un accès en lecture seule au pour AWS Glue Data Catalog obtenir des informations sur le schéma.
-
CloudWatch Journaux : le connecteur a besoin d'accéder aux CloudWatch journaux pour stocker les journaux.
-
Accès à Timestream – Pour exécuter des requêtes Timestream.
Performances
Nous vous recommandons d'utiliser la clause LIMIT afin de limiter les données renvoyées (et non les données numérisées) à moins de 256 Mo afin de garantir les performances des requêtes interactives.
Le connecteur Athena Timestream effectue une poussée vers le bas des prédicats pour réduire les données analysées par la requête. Les clauses LIMIT réduisent la quantité de données analysées, mais si vous ne fournissez pas de prédicat, vous devez vous attendre à ce que les requêtes SELECT avec une clause LIMIT analysent au moins 16 Mo de données. La sélection d'un sous-ensemble de colonnes accélère considérablement l'exécution des requêtes et réduit le nombre de données analysées. Le connecteur Timestream résiste à la limitation due à la simultanéité.
Requêtes passthrough
Le connecteur Timestream prend en charge les requêtes passthrough. Les requêtes passthrough utilisent une fonction de table pour transférer votre requête complète vers la source de données pour exécution.
Pour utiliser des requêtes directes avec Timestream, vous pouvez utiliser la syntaxe suivante :
SELECT * FROM TABLE( system.query( query => 'query string' ))
L'exemple de requête suivant envoie une requête vers une source de données dans Timestream. La requête sélectionne toutes les colonnes de la customer table, limitant les résultats à 10.
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
Informations de licence
Le projet de connecteur Timestream Amazon Athena est concédé sous licence dans le cadre de la licence Apache-2.0
Ressources supplémentaires
Pour plus d'informations sur ce connecteur, rendez-vous sur le site correspondant
