AWS Data Pipeline n'est plus disponible pour les nouveaux clients. Les clients existants de AWS Data Pipeline peuvent continuer à utiliser le service normalement. En savoir plus
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exécution de travaux sur des ressources existantes à l'aide de Task Runner
Vous pouvez installer Task Runner sur les ressources informatiques que vous gérez, telles qu'une instance Amazon EC2, un serveur physique ou un poste de travail. Task Runner peut être installé n'importe où, sur n'importe quel matériel ou système d'exploitation compatible, à condition qu'il puisse communiquer avec le service AWS Data Pipeline Web.
Cette approche peut être utile lorsque, par exemple, vous souhaitez AWS Data Pipeline traiter des données stockées dans le pare-feu de votre entreprise. En installant Task Runner sur un serveur du réseau local, vous pouvez accéder à la base de données locale en toute sécurité, puis AWS Data Pipeline demander la prochaine tâche à exécuter. Lorsque le traitement est AWS Data Pipeline terminé ou que le pipeline est supprimé, l'instance Task Runner continue de fonctionner sur votre ressource de calcul jusqu'à ce que vous l'arrêtiez manuellement. Les journaux de Task Runner sont conservés une fois l'exécution du pipeline terminée.
Pour utiliser Task Runner sur une ressource que vous gérez, vous devez d'abord télécharger Task Runner, puis l'installer sur votre ressource de calcul, en suivant les procédures décrites dans cette section.
Note
Vous ne pouvez installer Task Runner que sous Linux, UNIX ou macOS. Task Runner n'est pas compatible avec le système d'exploitation Windows.
Pour utiliser Task Runner 2.0, la version minimale de Java requise est 1.7.
Pour connecter un Task Runner que vous avez installé aux activités du pipeline qu'il doit traiter, ajoutez un workerGroup champ à l'objet et configurez Task Runner pour qu'il interroge cette valeur de groupe de travail. Pour ce faire, transmettez la chaîne du groupe de travail en tant que paramètre (par exemple,--workerGroup=wg-12345) lorsque vous exécutez le fichier JAR de Task Runner.
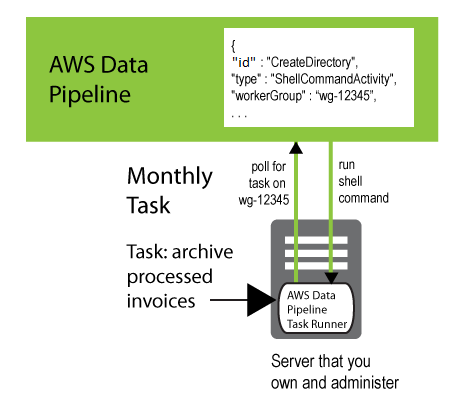
{ "id" : "CreateDirectory", "type" : "ShellCommandActivity", "workerGroup" : "wg-12345", "command" : "mkdir new-directory" }
Installation de Task Runner
Cette section explique comment installer et configurer Task Runner et ses prérequis. L'installation est un processus manuel simple.
Pour installer Task Runner
-
Task Runner nécessite les versions 1.6 ou 1.8 de Java. Pour déterminer si Java est installé et la version qui est en cours d'exécution, utilisez la commande suivante :
java -versionSi Java 1.6 ou 1.8 n'est pas installé sur votre ordinateur, téléchargez l'une de ces versions sur http://www.oracle. com/technetwork/java/index.html
. Téléchargez et installez Java, puis passez à l'étape suivante. -
Téléchargez-le
TaskRunner-1.0.jardepuis https://s3.amazonaws.com/datapipeline-us-east-1/us-east-1/ software/latest/TaskRunner/TaskRunner -1.0.jar, puis copiez-le dans un dossier de la ressource informatique cible. Pour les clusters Amazon EMR exécutant EmrActivitydes tâches, installez Task Runner sur le nœud principal du cluster. -
Lorsque vous utilisez Task Runner pour se connecter au service AWS Data Pipeline Web afin de traiter vos commandes, les utilisateurs ont besoin d'un accès programmatique à un rôle autorisé à créer ou à gérer des pipelines de données. Pour de plus amples informations, veuillez consulter Accorder un accès par programmation.
-
Task Runner se connecte au service AWS Data Pipeline Web via HTTPS. Si vous utilisez une AWS ressource, assurez-vous que le protocole HTTPS est activé dans la table de routage et l'ACL de sous-réseau appropriées. Si vous utilisez un pare-feu ou un proxy, assurez-vous que le port 443 est ouvert.
Démarrage de Task Runner
Dans une nouvelle fenêtre d'invite de commande définie sur le répertoire dans lequel vous avez installé Task Runner, lancez Task Runner avec la commande suivante.
java -jar TaskRunner-1.0.jar --config ~/credentials.json--workerGroup=myWorkerGroup--region=MyRegion--logUri=s3://amzn-s3-demo-bucket/foldername
L'option --config pointe vers votre fichier d'informations d'identification.
L'option --workerGroup indique le nom de votre groupe de travail, qui doit être identique à la valeur indiquée dans votre pipeline pour les tâches à traiter.
L'option --region indique la région du service où les tâches à exécuter doivent être récupérées.
--logUriCette option est utilisée pour transférer vos journaux compressés vers un emplacement dans Amazon S3.
Lorsque Task Runner est actif, il affiche le chemin vers lequel les fichiers journaux sont écrits dans la fenêtre du terminal. Voici un exemple.
Logging to /Computer_Name/.../output/logs
Task Runner doit être exécuté détaché de votre shell de connexion. Si vous utilisez une application de terminal pour vous connecter à votre ordinateur, vous devrez peut-être utiliser un utilitaire comme nohup ou screen pour empêcher l'application Task Runner de se fermer lorsque vous vous déconnecterez. Pour plus d'informations sur les options de ligne de commande, consultez Options de configuration de Task Runner.
Vérifier la journalisation de Task Runner
Le moyen le plus simple de vérifier que Task Runner fonctionne est de vérifier s'il écrit des fichiers journaux. Task Runner écrit des fichiers journaux horaires dans le répertoire output/logs situé sous le répertoire où Task Runner est installé. Le nom du fichier est Task Runner.log.YYYY-MM-DD-HH, où HH va de 00 à 23, au format UDT. Pour économiser de l'espace de stockage, tous les fichiers journaux datant de plus de huit heures sont compressés avec GZip.
