Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Contrôle AWS Tâches DMS
La surveillance joue un rôle important dans le maintien de la fiabilité, de la disponibilité AWS DMS et des performances de vos AWS solutions. Vous devez collecter des données de surveillance provenant de toutes les parties de votre AWS solution afin de pouvoir corriger plus facilement une défaillance multipoint, le cas échéant. AWS fournit plusieurs outils pour surveiller vos AWS DMS tâches et vos ressources, et répondre aux incidents potentiels :
- AWS DMS événements et notifications
-
AWS DMS utilise Amazon Simple Notification Service (Amazon SNS) pour envoyer des notifications lorsqu' AWS DMS un événement se produit, par exemple la création ou la suppression d'une instance de réplication. AWS DMS regroupe les événements dans des catégories auxquelles vous pouvez vous abonner, afin que vous puissiez être averti lorsqu'un événement de cette catégorie se produit. Par exemple, si vous vous abonnez à la catégorie de création d'une instance de réplication donnée, vous recevez une notification chaque fois que survient un événement lié à la création qui affecte votre instance de réplication. Vous pouvez utiliser ces notifications sous n'importe quelle forme prise en charge par Amazon SNS pour une AWS région, comme un e-mail, un message texte ou un appel vers un point de terminaison HTTP. Pour de plus amples informations, consultez Utilisation des événements et des notifications Amazon SNS dans AWS Database Migration Service.
- Statut de la tâche
-
Vous pouvez surveiller la progression d'une tâche en vérifiant le statut de la tâche et en surveillant la table de contrôle de la tâche. Le statut de la tâche indique l'état d'une AWS DMS tâche et de ses ressources associées. Il inclut des indications qui permettent de déterminer si la tâche est en cours de création, de lancement, d'exécution ou d'arrêt. Il indique également l'état actuel des tables migrées par la tâche. Par exemple, il permet de déterminer si une charge complète d'une table a commencé ou si elle est en cours et donne des informations telles que le nombre d'insertions, de suppressions et de mises à jour effectuées pour cette table. Pour plus d'informations sur la surveillance de l'état des tâches et de leurs ressources, consultez Statut de la tâche et État d'une table pendant des tâches. Pour plus d'informations sur les tables de contrôle, consultez Paramètres de tâche de la table de contrôle.
- CloudWatch Alarmes et journaux Amazon
-
À l'aide des CloudWatch alarmes Amazon, vous surveillez une ou plusieurs statistiques de tâches sur une période que vous spécifiez. Si une métrique dépasse un seuil donné, une notification est envoyée à une rubrique Amazon SNS. CloudWatch les alarmes n'appellent pas d'actions car elles se trouvent dans un état particulier. L'état doit plutôt avoir changé et être maintenu pendant un certain nombre de périodes. AWS DMS est également utilisé CloudWatch pour enregistrer les informations relatives aux tâches pendant le processus de migration. Vous pouvez utiliser l'API AWS CLI ou l' AWS DMS API pour consulter les informations relatives aux journaux des tâches. Pour plus d'informations sur l'utilisation CloudWatch avec AWS DMS, consultezSurveillance des tâches de réplication à l'aide d'Amazon CloudWatch. Pour plus d'informations sur la surveillance AWS DMS des métriques, consultezAWS Database Migration Service métriques. Pour plus d'informations sur l'utilisation des journaux des AWS DMS tâches, consultezAffichage et gestion AWS Journaux des tâches DMS.
- Journaux de voyage dans le temps
-
Pour enregistrer et déboguer les tâches de réplication, vous pouvez utiliser AWS DMS Time Travel. Dans cette approche, vous utilisez Amazon S3 pour stocker les journaux et les chiffrer à l’aide de vos clés de chiffrement. Vous pouvez récupérer vos journaux S3 à l’aide de filtres de date et d’heure, puis afficher, télécharger et masquer les journaux selon vos besoins. Ce faisant, vous pouvez « voyager dans le temps » pour examiner les activités de base de données.
Vous pouvez utiliser Time Travel avec les points de terminaison sources de DMS-supported PostgreSQL et les points de terminaison cibles de PostgreSQL et MySQL DMS-supported . Vous pouvez activer le voyage dans le temps uniquement pour les tâches de chargement complet et CDC et pour les tâches de CDC uniquement. Pour activer le voyage dans le temps ou pour modifier des paramètres de voyage dans le temps existants, assurez-vous que votre tâche est arrêtée.
Pour plus d’informations sur les journaux de voyage dans le temps, consultez Paramètres de tâche de voyage dans le temps. Pour examiner les bonnes pratiques relatives à l’utilisation des journaux de voyage dans le temps, consultez Résolution des problèmes liés aux tâches de réplication à l’aide du voyage dans le temps.
- AWS CloudTrail journaux
-
AWS DMS est intégré à AWS CloudTrail un service qui fournit un enregistrement des actions entreprises par un utilisateur, un rôle IAM ou un AWS service dans AWS DMS. CloudTrailcapture tous les appels d'API AWS DMS sous forme d'événements, y compris les appels depuis la AWS DMS console et les appels de code vers les opérations AWS DMS d'API. Si vous créez un suivi, vous pouvez activer la diffusion continue d' CloudTrail événements vers un compartiment Amazon S3, y compris les événements pour AWS DMS. Si vous ne configurez pas de suivi, vous pouvez toujours consulter les événements les plus récents dans la CloudTrail console dans Historique des événements. À l'aide des informations collectées par CloudTrail, vous pouvez déterminer la demande qui a été faite AWS DMS, l'adresse IP à partir de laquelle la demande a été faite, qui a fait la demande, quand elle a été faite et des détails supplémentaires. Pour de plus amples informations, veuillez consulter Logging AWS DMS Appels d'API avec AWS CloudTrail.
- Journaux de base de données
-
Vous pouvez consulter, télécharger et consulter les journaux de base de données pour les points de terminaison de vos tâches à l'aide de Console de gestion AWS AWS CLI, ou de l'API de votre service de AWS base de données. Pour plus d’informations, consultez la documentation de votre service de base de données dans la documentation AWS.
Pour plus d’informations, consultez les rubriques suivantes.
Statut de la tâche
Le statut de la tâche indique la condition de la tâche. Le tableau suivant montre les états possibles qu'une tâche peut avoir :
| Statut de la tâche | Description |
|---|---|
|
Création |
AWS DMS crée la tâche. |
|
En cours d'exécution |
La tâche exécute les tâches de migration spécifiées. |
|
Arrêté(e) |
La tâche est arrêtée. |
|
Arrêt en cours |
La tâche est en cours d'arrêt. Ceci est généralement une indication d'une intervention d'un utilisateur dans la tâche. |
|
Suppression en cours |
La tâche est cours de suppression, généralement suite à une demande d'intervention de l'utilisateur. |
|
Échec |
La tâche a échoué. Pour plus d’informations, consultez les fichiers journaux de la tâche. |
|
Error (Erreur) |
La tâche s’est arrêtée en raison d’une erreur. Une brève description de l’erreur concernant la tâche est fournie dans la dernière section du message d’échec, dans l’onglet Vue d’ensemble. |
|
Exécution avec des erreurs |
La tâche s’exécute avec un statut d’erreur. Cela indique généralement qu’une ou plusieurs tables de la tâche n’ont pas pu être migrées. La tâche continue de charger d’autres tables conformément aux règles de sélection. |
|
Démarrage en cours |
La tâche se connecte à l'instance de réplication et aux points de terminaison source et cible. Les filtres et les transformations sont appliqués. |
|
Prêt |
La tâche est prête à s'exécuter. Cet état suit généralement l'état « Création ». |
|
Modification |
La tâche est en cours de modification, généralement en raison d'une action de l'utilisateur qui a modifié les paramètres de la tâche. |
|
Déplacement |
La tâche est en cours de déplacement vers une autre instance de réplication. La réplication conserve ce statut jusqu’à ce que le déplacement soit terminé. La suppression de la tâche est la seule opération autorisée sur la tâche de réplication pendant son déplacement. |
|
Failed-move |
Le déplacement de la tâche a échoué pour une raison quelconque, telle qu’un manque d’espace de stockage sur l’instance de réplication cible. Lorsqu’une tâche de réplication présente ce statut, elle peut être démarrée, modifiée, déplacée ou supprimée. |
|
Test |
La migration de base de données spécifiée pour cette tâche est testée en réponse à l'exécution de l'StartReplicationTaskAssessmentRunopération ou de l'StartReplicationTaskAssessmentopération. |
La barre d’état des tâches donne une estimation de la progression de la tâche. La qualité de cette estimation dépend de la qualité des statistiques de table de la base de données source ; meilleures sont les statistiques de table, plus précise sera l'estimation. Pour les tâches avec une seule table ne disposant pas de statistiques de lignes estimées, nous ne pouvons par fournir une estimation complète en pourcentage. Dans ce cas, l'état de la tâche et l'indication des lignes chargées peuvent servir à confirmer que la tâche est bien en cours d'exécution et de progression.
Notez que la colonne « Dernière mise à jour » de la console DMS indique uniquement l’instant où AWS DMS a mis à jour pour la dernière fois l’enregistrement des statistiques de table pour une table. Elle n'indique pas l'heure de la dernière mise à jour de la table.
Outre l’utilisation de la console DMS, vous pouvez générer une description des tâches de réplication actuelles, y compris leur statut, à l’aide de la commande aws dms
describe-replication-tasks dans AWS CLI, comme illustré dans l’exemple suivant.
{ "ReplicationTasks": [ { "ReplicationTaskIdentifier": "moveit2", "SourceEndpointArn": "arn:aws:dms:us-east-1:123456789012:endpoint:6GGI6YPWWGAYUVLKIB732KEVWA", "TargetEndpointArn": "arn:aws:dms:us-east-1:123456789012:endpoint:EOM4SFKCZEYHZBFGAGZT3QEC5U", "ReplicationInstanceArn": "arn:aws:dms:us-east-1:123456789012:rep:T3OM7OUB5NM2LCVZF7JPGJRNUE", "MigrationType": "full-load", "TableMappings": ...output omitted... , "ReplicationTaskSettings": ...output omitted... , "Status": "stopped", "StopReason": "Stop Reason FULL_LOAD_ONLY_FINISHED", "ReplicationTaskCreationDate": 1590524772.505, "ReplicationTaskStartDate": 1590619805.212, "ReplicationTaskArn": "arn:aws:dms:us-east-1:123456789012:task:K55IUCGBASJS5VHZJIINA45FII", "ReplicationTaskStats": { "FullLoadProgressPercent": 100, "ElapsedTimeMillis": 0, "TablesLoaded": 0, "TablesLoading": 0, "TablesQueued": 0, "TablesErrored": 0, "FreshStartDate": 1590619811.528, "StartDate": 1590619811.528, "StopDate": 1590619842.068 } } ] }
État d'une table pendant des tâches
La console AWS DMS met à jour les informations relatives à l'état de vos tables pendant la migration. Le tableau suivant illustre les valeurs d’état possibles :
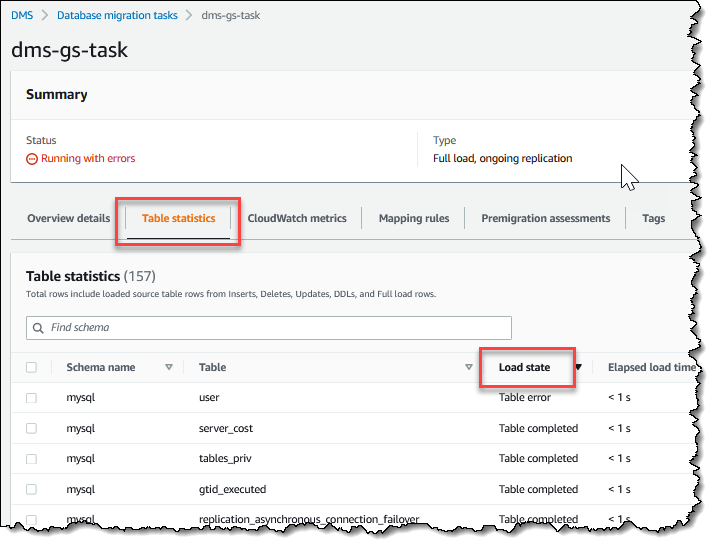
| State | Description |
|---|---|
|
La table n'existe pas |
AWS DMS ne trouve pas la table sur le point de terminaison source. |
|
Avant chargement |
Le processus de chargement complet a été activé, mais il n'a pas encore commencé. |
|
Chargement complet |
Le processus de chargement complet est en cours. |
|
Table terminée |
Le chargement complet est terminé. |
|
Table annulée |
Le chargement de la table a été annulé. |
|
Erreur de table |
Une erreur s'est produite lors du chargement de la table. |
Surveillance des tâches de réplication à l'aide d'Amazon CloudWatch
Vous pouvez utiliser les CloudWatch alarmes ou les événements Amazon pour suivre de plus près votre migration. Pour plus d'informations sur Amazon CloudWatch, consultez Que sont Amazon CloudWatch, Amazon CloudWatch Events et Amazon CloudWatch Logs ? dans le guide de CloudWatch l'utilisateur Amazon. Notez que l'utilisation d'Amazon est payante CloudWatch.
Si votre tâche de réplication ne crée pas de CloudWatch journaux, consultez le guide AWS DMS ne crée pas de CloudWatch journaux de résolution des problèmes.
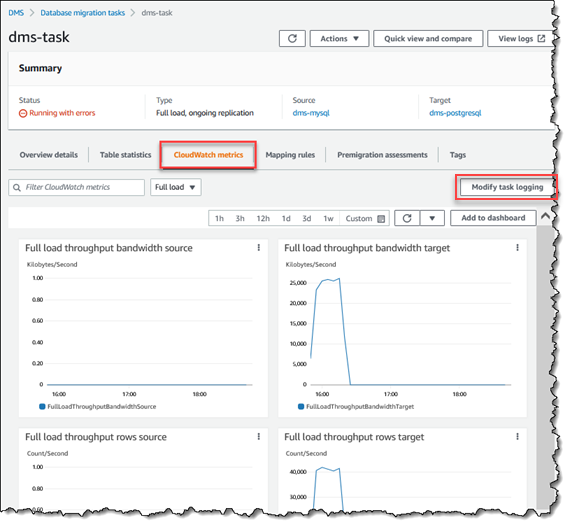
La AWS DMS console affiche les CloudWatch statistiques de base pour chaque tâche, notamment le statut de la tâche, le pourcentage d'achèvement, le temps écoulé et les statistiques du tableau, comme indiqué ci-dessous. Sélectionnez la tâche de réplication, puis sélectionnez l'onglet CloudWatch métriques.
Pour afficher et modifier les paramètres du journal des CloudWatch tâches, choisissez Modifier le journal des tâches. Pour de plus amples informations, veuillez consulter Paramètres de la tâche de journalisation.
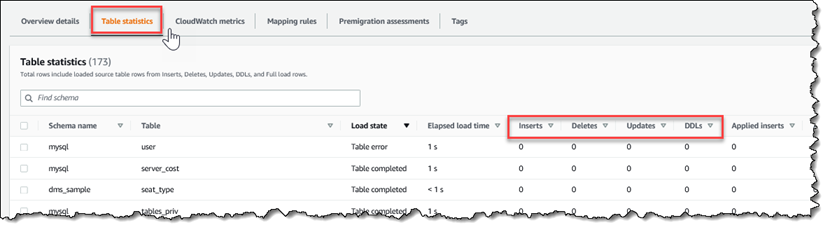
La console AWS DMS affiche les statistiques de performance pour chaque table, y compris le nombre d'insertions, de suppressions et de mises à jour, lorsque vous sélectionnez l'onglet Statistiques des tables.
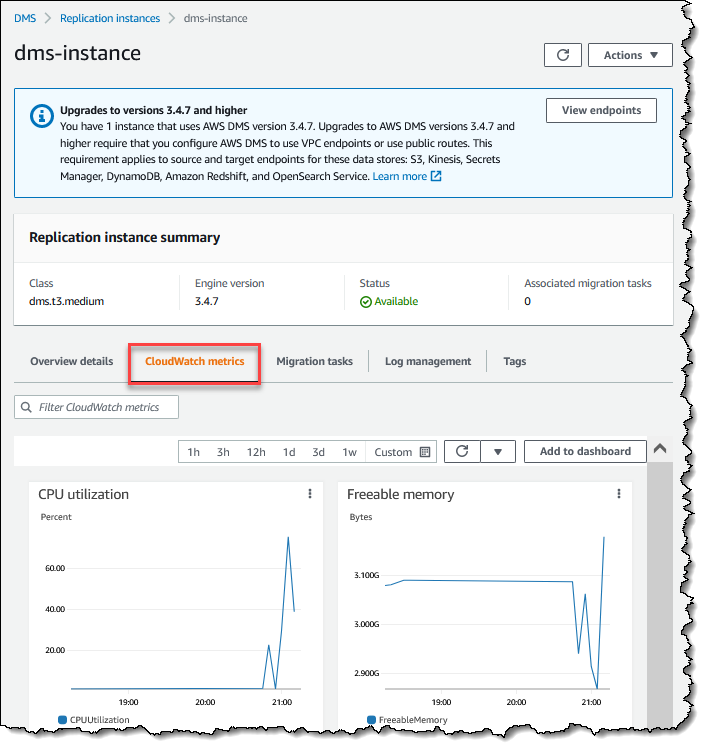
En outre, si vous sélectionnez une instance de réplication sur la page Instance de réplication, vous pouvez consulter les mesures de performance de l'instance en choisissant l'onglet CloudWatch Mesures.
AWS Database Migration Service métriques
AWS DMS fournit des statistiques pour les éléments suivants :
Mesures relatives à l'hôte : statistiques de performance et d'utilisation de l'hôte de réplication, fournies par Amazon CloudWatch. Pour consulter une liste complète des métriques disponibles, consultez la page Métriques des instances de réplication.
Métriques de la tâche de réplication : statistiques pour les tâches de réplication, notamment les modifications entrantes et validées, ainsi que la latence entre l’hôte de réplication et les bases de données source et cible. Pour consulter une liste complète des métriques disponibles, consultez la page Métriques de tâches de réplication.
Métriques de table : statistiques pour les tables en cours de migration, notamment le nombre d’instructions d’insertion, de mise à jour, de suppression et DDL terminées.
Les métriques de tâches sont divisées en statistiques pour l'hôte de réplication et le point de terminaison source, ainsi que pour l'hôte de réplication et le point de terminaison cible. Le CDCLatencySourceet CDCLatencyTargetpeut être utilisé pour identifier la cause de la latence d'une tâche en comparant ces statistiques associées. Par exemple, si la CDCLatencySourcevaleur est presque identique à la CDCLatencyTargetvaleur, vous devez d'abord vérifier le côté source. Toutefois, si le CDCLatencyTargetest supérieur à CDCLatencySource, vous devez vous concentrer sur la vérification de la latence côté cible.
Les valeurs de métriques de tâche peuvent être influencées par l'activité en cours dans votre base de données source. Par exemple, si une transaction a commencé mais n'a pas été validée, la CDCLatencySourcemétrique continue de croître jusqu'à ce que cette transaction soit validée.
Pour l'instance de réplication, la FreeableMemorymétrique doit être clarifiée. La mémoire libérable n'est pas une indication relative à la mémoire réelle disponible. Il s'agit de la mémoire actuellement en cours d'utilisation et pouvant être libérée et affectée à d'autres utilisations ; il s'agit d'une combinaison des mémoires tampon et de cache en cours d'utilisation sur l'instance de réplication.
Bien que la FreeableMemorymétrique ne reflète pas la mémoire libre réellement disponible, la combinaison des SwapUsagemétriques FreeableMemoryet peut indiquer si l'instance de réplication est surchargée.
Surveillez les conditions suivantes pour ces deux métriques.
La FreeableMemorymétrique approche de zéro.
La SwapUsagemétrique augmente ou fluctue.
Si vous rencontrez une de ces deux conditions, cela indique que vous devez envisager un transfert vers une instance de réplication plus importante. Vous devez également envisager de réduire le nombre et le type de tâches exécutées sur l'instance de réplication. Les tâches de chargement complet nécessitent davantage de mémoire que les tâches qui répliquent seulement des modifications.
Pour estimer approximativement les besoins réels en mémoire pour une tâche de AWS DMS migration, vous pouvez utiliser les paramètres suivants.
- Colonnes LOB
Nombre moyen de colonnes LOB dans chaque table de votre étendue de migration.
- Nombre maximum de tables à charger en parallèle
Nombre maximal de tables chargées AWS DMS en parallèle dans une tâche.
La valeur par défaut est 8.
- Taille de bloc du LOB
Taille des segments LOB, en kilo-octets, AWS DMS utilisés pour répliquer les données vers la base de données cible.
- Taux de validation pendant le chargement complet
Le nombre maximum d'enregistrements AWS DMS pouvant être transférés en parallèle.
La valeur par défaut est 10,000.
- Taille de LOB
Taille maximale d’un LOB individuel, en kilo-octets.
- Taille de tableau en masse
Nombre maximal de lignes extraites ou traitées par votre pilote de point de terminaison. Cette valeur dépend des paramètres du pilote.
La valeur par défaut est 1,000.
Après avoir déterminé ces valeurs, vous pouvez utiliser l’une des méthodes suivantes pour estimer la quantité de mémoire requise pour votre tâche de migration. Ces méthodes dépendent de l’option que vous choisissez pour Paramètres de la colonne LOB dans votre tâche de migration.
-
Pour Mode LOB complet, utilisez la formule suivante.
Required memory = (LOB columns) * (Maximum number of tables to load in parallel) * (LOB chunk size) * (Commit rate during full load)Prenons un exemple où vos tables sources incluent en moyenne 2 colonnes LOB et où la taille des blocs du LOB est de 64 Ko. Si vous utilisez les valeurs par défaut pour
Maximum number of tables to load in paralleletCommit rate during full load, la quantité de mémoire requise pour votre tâche est la suivante.Required memory = 2 * 8 * 64 * 10,000 = 10,240,000 KBNote
Pour réduire la valeur du taux de validation pendant le chargement complet, ouvrez la AWS DMS console, sélectionnez Tâches de migration de base de données, puis créez ou modifiez une tâche. Développez Paramètres avancés et entrez votre valeur pour Taux de validation (opérations Commit) lors du chargement complet.
-
Pour Mode LOB limité, utilisez la formule suivante.
Required memory = (LOB columns) * (Maximum number of tables to load in parallel) * (LOB size) * (Bulk array size)Prenons un exemple où vos tables sources incluent en moyenne 2 colonnes LOB et où la taille maximale d’un LOB individuel est de 4 096 Ko. Si vous utilisez les valeurs par défaut pour
Maximum number of tables to load in paralleletBulk array size, la quantité de mémoire requise pour votre tâche est la suivante.Required memory = 2 * 8 * 4,096 * 1,000 = 65,536,000 KB
AWS DMS Pour effectuer les conversions de manière optimale, le processeur doit être disponible au moment des conversions. La surcharge du processeur et le manque de ressources du processeur peuvent ralentir les migrations. AWS DMS cela peut être CPU-intensive le cas, en particulier lors de migrations et de réplications hétérogènes, telles que la migration d'Oracle vers PostgreSQL.
Métriques des instances de réplication
La surveillance des instances de réplication inclut CloudWatch les métriques Amazon pour les statistiques suivantes.
|
Métrique |
Description |
|---|---|
| AvailableMemory |
Estimation de la quantité de mémoire disponible pour démarrer de nouvelles applications, sans échange. Pour plus d’informations, consultez la valeur Unités : octets |
| CPUAllocated |
Pourcentage de CPU alloué au maximum pour la tâche (0 signifie qu’il n’y a pas de limite). AWS DMS augmente cette métrique par rapport aux dimensions combinées de Unités : pourcentage |
| CPUUtilization |
Pourcentage de vCPU (CPU virtuel) alloué actuellement utilisé dans l’instance. Unités : pourcentage |
| DiskQueueDepth |
Le nombre de read/write demandes en suspens (I/Os) en attente d'accès au disque. Unités : nombre |
| FreeStorageSpace |
Quantité d’espace de stockage disponible. Unités : octets |
| FreeMemory |
Quantité de mémoire physique disponible pour être utilisée par les applications, le cache de pages et pour les propres structures de données du noyau. Pour plus d’informations, consultez la valeur Unités : octets |
| FreeableMemory |
Quantité de mémoire vive disponible. Unités : octets |
| MemoryAllocated |
Allocation maximale de mémoire pour la tâche (0 signifie qu’il n’y a pas de limite). AWS DMS augmente cette métrique par rapport aux dimensions combinées de Unités : Mio |
| WriteIOPS |
Nombre moyen d' I/O opérations d'écriture sur disque par seconde. Unités : Count/Second |
| ReadIOPS |
Nombre moyen d' I/O opérations de lecture sur disque par seconde. Unités : Count/Second |
| WriteThroughput |
Nombre moyen d’octets écrits sur le disque par seconde. Unités : Bytes/Second |
| ReadThroughput |
Nombre moyen d’octets lus sur le disque par seconde. Unités : Bytes/Second |
| WriteLatency |
Durée moyenne par opération sur disque I/O (sortie). Unités : millisecondes |
| ReadLatency |
Durée moyenne par opération sur le disque I/O (entrée). Unités : millisecondes |
| SwapUsage |
Quantité d'espace d'échange utilisé sur l'instance de réplication. Unités : octets |
| NetworkTransmitThroughput | Le trafic réseau sortant (transmission) sur l'instance de réplication, y compris le trafic de base de données client. Unités Bytes/second: |
| NetworkReceiveThroughput |
Le trafic réseau entrant (réception) sur l'instance de réplication, y compris le trafic de base de données client. Unités : Bytes/second |
Métriques de tâches de réplication
La surveillance de la tâche de réplication inclut des métriques pour les statistiques suivantes.
|
Métrique |
Description |
|---|---|
| FullLoadThroughputBandwidthTarget |
Données sortantes transmises à partir d’un chargement complet pour la cible en Ko par seconde. |
| FullLoadThroughputRowsTarget |
Modifications sortantes à partir d'un chargement total depuis la source, exprimées en lignes par seconde. |
| CDCIncomingChanges |
Nombre total d'événements de modification qui attendent, à un moment donné, d'être appliqués à la cible. Notez que cela est différent de la mesure du taux de modifications de transaction du point de terminaison source. Une valeur élevée pour cette métrique indique généralement qu’ AWS DMS n’est pas en mesure d’appliquer les modifications capturées dans un délai raisonnable, ce qui entraîne une latence cible importante. |
| CDCChangesMemorySource |
Quantité de lignes s'accumulant dans une mémoire et attendant leur validation à partir de la source. Vous pouvez consulter cette métrique avec CDCChangesDiskSource. |
| CDCChangesMemoryTarget |
Quantité de lignes s'accumulant dans une mémoire et attendant leur validation dans la cible. Vous pouvez consulter cette métrique avec CDCChangesDiskTarget. |
| CDCChangesDiskSource |
Quantité de lignes s'accumulant sur un disque et attendant leur validation à partir de la source. Vous pouvez consulter cette métrique avec CDCChangesMemorySource. |
| CDCChangesDiskTarget |
Quantité de lignes s'accumulant sur un disque et attendant leur validation dans la cible. Vous pouvez consulter cette métrique avec CDCChangesMemoryTarget. |
| CDCThroughputBandwidthTarget |
Données sortantes transmises pour la cible en Ko par seconde. CDCThroughputBandwidth enregistre les données sortantes transmises sur les points de prélèvement. Si aucun trafic réseau de tâche n’est trouvé, la valeur est zéro. Étant donné que CDC ne délivre pas de transactions de longue durée, le trafic réseau peut ne pas être enregistré. |
| CDCThroughputRowsSource |
Modifications de tâche entrante à partir de la source en lignes par seconde. |
| CDCThroughputRowsTarget |
Modifications de tâche sortante pour la cible en lignes par seconde. |
| CDCLatencySource |
L'écart, en secondes, entre le dernier événement capturé par le point de terminaison source et l'horodatage système actuel de l' AWS DMS instance. CDCLatencySource représente la latence entre la source et l'instance de réplication. Un niveau élevé CDCLatencySource signifie que le processus de capture des modifications depuis la source est retardé. Pour identifier le temps de latence dans une réplication en cours, vous pouvez consulter cette métrique avec CDCLatencyTarget. Si CDCLatencySource les deux CDCLatencyTarget sont élevés, examinez d' CDCLatencySourceabord. CDCSourceLatency peut être égal à 0 lorsqu'il n'y a aucun délai de réplication entre la source et l'instance de réplication. CDCSourceLatencypeut également devenir zéro lorsque la tâche de réplication tente de lire le prochain événement dans le journal des transactions de la source et qu'aucun nouvel événement n'est enregistré par rapport à la dernière lecture depuis la source. Lorsque cela se produit, la tâche remet la valeur CDCSourceLatency à 0. Des pics de latence du CDC peuvent être attendus pendant les périodes d'activité intense de la base de données source, telles que le traitement par lots, les opérations de maintenance ou les transactions importantes. Les augmentations de latence temporaires constituent un comportement opérationnel normal et ne sont pas nécessairement le signe d'un problème de service. Si une latence élevée et prolongée est observée, passez en revue les facteurs décrits dansla réplication continue.. |
| CDCLatencyTarget |
Intervalle, en secondes, entre le premier horodatage d’événement en attente de validation sur la cible et l’horodatage actuel de l’instance AWS DMS . La latence cible est la différence entre l’heure du serveur de l’instance de réplication et le plus ancien identifiant d’événement non confirmé transféré vers un composant cible. En d’autres termes, la latence cible est la différence d’horodatage entre l’instance de réplication et le plus ancien événement appliqué mais non confirmé par le point de terminaison TRG (99 %). Lorsque CDCLatencyTarget cette valeur est élevée, cela indique que le processus d'application des événements de changement à la cible est retardé. Pour identifier le temps de latence dans une réplication en cours, vous pouvez consulter cette métrique avec CDCLatencySource. Si CDCLatencyTarget c'est élevé mais CDCLatencySource pas élevé, vérifiez si :
|
| CPUUtilization |
Pourcentage de CPU utilisé par une tâche sur plusieurs cœurs. La sémantique de la valeur CPUUtilization de la tâche est légèrement différente de celle de la valeur CPUUtilizaiton de la réplication. Si 1 vCPU est entièrement utilisé, cela indique 100 %, mais si plusieurs vCPU sont utilisés, la valeur peut dépasser 100 %. Unités : pourcentage |
| SwapUsage |
Quantité d’échange utilisée par la tâche. Unités : octets |
| MemoryUsage |
Groupe de contrôle (cgroup) memory.usage_in_bytes consommé par une tâche. DMS utilise des groupes de contrôle pour contrôler l’utilisation des ressources système telles que la mémoire et le CPU. Cette métrique indique l’utilisation de mémoire d’une tâche en mégaoctets au sein du groupe de contrôle alloué pour cette tâche. Les limites du groupe de contrôle sont basées sur les ressources disponibles pour votre classe d’instances de réplication DMS. memory.usage_in_bytes comprend la taille de résident défini (RSS), le cache et les composants d’échange de mémoire. Le système d’exploitation peut récupérer de la mémoire cache si nécessaire. Nous vous recommandons de surveiller également la métrique de l'instance de réplication, AvailableMemory. AWS DMS augmente cette métrique par rapport aux dimensions combinées de |
Affichage et gestion AWS Journaux des tâches DMS
Vous pouvez utiliser Amazon CloudWatch pour enregistrer les informations relatives aux tâches au cours d'un processus de AWS DMS migration. Vous activez la journalisation lorsque vous sélectionnez les paramètres de tâche. Pour de plus amples informations, veuillez consulter Paramètres de la tâche de journalisation.
Pour afficher les journaux d'une tâche exécutée, procédez comme suit :
-
Ouvrez la AWS DMS console et choisissez Tâches de migration de base de données dans le volet de navigation. La boîte de dialogue Tâches de migration de base de données s'affiche.
-
Sélectionnez le nom de votre tâche. La boîte de dialogue Détails de présentation s'affiche.
-
Localisez la section Journaux des tâches de migration et choisissez Afficher CloudWatch les journaux.
En outre, vous pouvez utiliser l' AWS DMS API AWS CLI or pour consulter les informations relatives aux journaux des tâches. Pour ce faire, utilisez la describe-replication-instance-task-logs AWS CLI
commande ou l'action de l' AWS DMS APIDescribeReplicationInstanceTaskLogs.
Par exemple, la AWS CLI commande suivante affiche les métadonnées du journal des tâches au format JSON.
$ aws dms describe-replication-instance-task-logs \ --replication-instance-arn arn:aws:dms:us-east-1:237565436:rep:CDSFSFSFFFSSUFCAY
Voici un exemple de réponse de la commande.
{ "ReplicationInstanceTaskLogs": [ { "ReplicationTaskArn": "arn:aws:dms:us-east-1:237565436:task:MY34U6Z4MSY52GRTIX3O4AY", "ReplicationTaskName": "mysql-to-ddb", "ReplicationInstanceTaskLogSize": 3726134 } ], "ReplicationInstanceArn": "arn:aws:dms:us-east-1:237565436:rep:CDSFSFSFFFSSUFCAY" }
Dans cette réponse, l'instance de réplication est associée à un seul journal de tâches (mysql-to-ddb). La taille de ce journal est de 3 726,124 octets.
Vous pouvez utiliser les informations renvoyés par describe-replication-instance-task-logs pour diagnostiquer et résoudre les problèmes liés aux journaux de tâches. Par exemple, si vous autorisez une journalisation détaillée du débogage pour une tâche, le journal de la tâche croîtra rapidement. L’espace de stockage disponible sur l’instance de réplication risque alors d’être entièrement consommé et le statut de l’instance passera à storage-full. En décrivant les journaux de tâches, vous pouvez identifier ceux dont vous n'avez plus besoin et les supprimer pour libérer de l'espace de stockage.
Pour supprimer les journaux pour une tâche, définissez le paramètre de tâche DeleteTaskLogs sur true. Par exemple, le code JSON suivant supprime les journaux des tâches lorsque vous modifiez une tâche à l'aide de la AWS CLI modify-replication-task commande ou de l'ModifyReplicationTaskaction de l' AWS DMS API.
{ "Logging": { "DeleteTaskLogs":true } }
Note
Pour chaque instance de réplication, AWS DMS supprime les journaux datant de plus de 10 jours.
Logging AWS DMS Appels d'API avec AWS CloudTrail
AWS DMS est intégré à AWS CloudTrail un service qui fournit un enregistrement des actions entreprises par un utilisateur, un rôle ou un AWS service dans AWS DMS. CloudTrail capture tous les appels d'API AWS DMS sous forme d'événements, y compris les appels depuis la AWS DMS console et les appels de code vers les opérations AWS DMS d'API. Si vous créez un suivi, vous pouvez activer la diffusion continue d' CloudTrail événements vers un compartiment Amazon S3, y compris les événements pour AWS DMS. Si vous ne configurez pas de suivi, vous pouvez toujours consulter les événements les plus récents dans la CloudTrail console dans Historique des événements. À l'aide des informations collectées par CloudTrail, vous pouvez déterminer la demande qui a été faite AWS DMS, l'adresse IP à partir de laquelle la demande a été faite, qui a fait la demande, quand elle a été faite et des détails supplémentaires.
Pour en savoir plus CloudTrail, consultez le guide de AWS CloudTrail l'utilisateur.
AWS DMS informations dans CloudTrail
CloudTrail est activé sur votre AWS compte lorsque vous le créez. Lorsqu'une activité se produit dans AWS DMS, cette activité est enregistrée dans un CloudTrail événement avec d'autres événements de AWS service dans l'historique des événements. Vous pouvez consulter, rechercher et télécharger les événements récents dans votre AWS compte. Pour plus d'informations, consultez la section Affichage des événements avec l'historique des CloudTrail événements.
Pour un enregistrement continu des événements de votre AWS compte, y compris des événements pour AWS DMS, créez un parcours. Un suivi permet CloudTrail de fournir des fichiers journaux à un compartiment Amazon S3. Par défaut, lorsque vous créez un parcours dans la console, celui-ci s'applique à toutes les AWS régions. Le journal enregistre les événements de toutes les AWS régions de la AWS partition et transmet les fichiers journaux au compartiment Amazon S3 que vous spécifiez. En outre, vous pouvez configurer d'autres AWS services pour analyser plus en détail les données d'événements collectées dans les CloudTrail journaux et agir en conséquence. Pour en savoir plus, consultez :
Toutes les AWS DMS actions sont enregistrées CloudTrail et documentées dans la référence de l'AWS Database Migration Service API. Par exemple, les appels auCreateReplicationInstance, TestConnection et les StartReplicationTask actions génèrent des entrées dans les fichiers CloudTrail journaux.
Chaque événement ou entrée de journal contient des informations sur la personne ayant initié la demande. Les informations relatives à l’identité permettent de déterminer les éléments suivants :
-
Si la demande a été effectuée avec des informations d’identification d’utilisateur root ou IAM.
-
Si la demande a été effectuée avec des informations d’identification de sécurité temporaires pour un rôle ou un utilisateur fédéré.
-
Si la demande a été faite par un autre AWS service.
Pour de plus amples informations, veuillez consulter l'élément userIdentity CloudTrail .
Compréhension AWS DMS entrées de fichier journal
Un suivi est une configuration qui permet de transmettre des événements sous forme de fichiers journaux à un compartiment Amazon S3 que vous spécifiez. CloudTrail les fichiers journaux contiennent une ou plusieurs entrées de journal. Un événement représente une demande unique provenant de n'importe quelle source et inclut des informations sur l'action demandée, la date et l'heure de l'action, les paramètres de la demande, etc. CloudTrail les fichiers journaux ne constituent pas une trace ordonnée des appels d'API publics, ils n'apparaissent donc pas dans un ordre spécifique.
L'exemple suivant montre une entrée de CloudTrail journal illustrant l'RebootReplicationInstanceaction.
{ "eventVersion": "1.05", "userIdentity": { "type": "AssumedRole", "principalId": "AKIAIOSFODNN7EXAMPLE:johndoe", "arn": "arn:aws:sts::123456789012:assumed-role/admin/johndoe", "accountId": "123456789012", "accessKeyId": "ASIAIOSFODNN7EXAMPLE", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2018-08-01T16:42:09Z" }, "sessionIssuer": { "type": "Role", "principalId": "AKIAIOSFODNN7EXAMPLE", "arn": "arn:aws:iam::123456789012:role/admin", "accountId": "123456789012", "userName": "admin" } } }, "eventTime": "2018-08-02T00:11:44Z", "eventSource": "dms.amazonaws.com", "eventName": "RebootReplicationInstance", "awsRegion": "us-east-1", "sourceIPAddress": "72.21.198.64", "userAgent": "console.amazonaws.com", "requestParameters": { "forceFailover": false, "replicationInstanceArn": "arn:aws:dms:us-east-1:123456789012:rep:EX4MBJ2NMRDL3BMAYJOXUGYPUE" }, "responseElements": { "replicationInstance": { "replicationInstanceIdentifier": "replication-instance-1", "replicationInstanceStatus": "rebooting", "allocatedStorage": 50, "replicationInstancePrivateIpAddresses": [ "172.31.20.204" ], "instanceCreateTime": "Aug 1, 2018 11:56:21 PM", "autoMinorVersionUpgrade": true, "engineVersion": "2.4.3", "publiclyAccessible": true, "replicationInstanceClass": "dms.t2.medium", "availabilityZone": "us-east-1b", "kmsKeyId": "arn:aws:kms:us-east-1:123456789012:key/f7bc0f8e-1a3a-4ace-9faa-e8494fa3921a", "replicationSubnetGroup": { "vpcId": "vpc-1f6a9c6a", "subnetGroupStatus": "Complete", "replicationSubnetGroupArn": "arn:aws:dms:us-east-1:123456789012:subgrp:EDHRVRBAAAPONQAIYWP4NUW22M", "subnets": [ { "subnetIdentifier": "subnet-cbfff283", "subnetAvailabilityZone": { "name": "us-east-1b" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-d7c825e8", "subnetAvailabilityZone": { "name": "us-east-1e" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-6746046b", "subnetAvailabilityZone": { "name": "us-east-1f" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-bac383e0", "subnetAvailabilityZone": { "name": "us-east-1c" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-42599426", "subnetAvailabilityZone": { "name": "us-east-1d" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-da327bf6", "subnetAvailabilityZone": { "name": "us-east-1a" }, "subnetStatus": "Active" } ], "replicationSubnetGroupIdentifier": "default-vpc-1f6a9c6a", "replicationSubnetGroupDescription": "default group created by console for vpc id vpc-1f6a9c6a" }, "replicationInstanceEniId": "eni-0d6db8c7137cb9844", "vpcSecurityGroups": [ { "vpcSecurityGroupId": "sg-f839b688", "status": "active" } ], "pendingModifiedValues": {}, "replicationInstancePublicIpAddresses": [ "18.211.48.119" ], "replicationInstancePublicIpAddress": "18.211.48.119", "preferredMaintenanceWindow": "fri:22:44-fri:23:14", "replicationInstanceArn": "arn:aws:dms:us-east-1:123456789012:rep:EX4MBJ2NMRDL3BMAYJOXUGYPUE", "replicationInstanceEniIds": [ "eni-0d6db8c7137cb9844" ], "multiAZ": false, "replicationInstancePrivateIpAddress": "172.31.20.204", "patchingPrecedence": 0 } }, "requestID": "a3c83c11-95e8-11e8-9d08-4b8f2b45bfd5", "eventID": "b3c4adb1-e34b-4744-bdeb-35528062a541", "eventType": "AwsApiCall", "recipientAccountId": "123456789012" }
AWS DMS Journalisation du contexte
AWS DMS utilise la journalisation contextuelle pour vous fournir des informations sur une migration en cours. La journalisation contextuelle écrit des informations, telles que les suivantes, dans le CloudWatch journal de la tâche :
Informations sur la connexion de la tâche aux bases de données source et cible.
Comportement des tâches de réplication. Vous pouvez utiliser les journaux de tâches pour diagnostiquer les problèmes de réplication.
Instructions SQL sans données qui AWS DMS s'exécutent sur les bases de données source et cible. Vous pouvez utiliser les journaux SQL pour diagnostiquer un comportement de migration inattendu.
Détails de position de flux pour chaque événement CDC.
La journalisation contextuelle n'est disponible que dans AWS DMS la version 3.5.0 ou supérieure.
AWS DMS active la journalisation contextuelle par défaut. Pour contrôler la journalisation du contexte, définissez le paramètre de tâche EnableLogContext sur true ou false, ou modifiez la tâche dans la console.
AWS DMS écrit les informations du journal contextuel dans la tâche de réplication du CloudWatch journal toutes les trois minutes. Veillez à ce que votre instance de réplication dispose de suffisamment d’espace pour son journal d’application. Pour plus d’informations sur la gestion des journaux de tâches, consultez Affichage et gestion AWS Journaux des tâches DMS.
Types d’objets
AWS DMS produit une connexion contextuelle CloudWatch pour les types d'objets suivants.
| Type d’objet | Description |
|---|---|
TABLE_NAME |
Ces entrées de journal contiennent des informations sur les tables concernées par la règle de mappage des tâches actuelle. Vous pouvez utiliser ces entrées pour examiner les événements de table pour une période spécifique au cours de la migration. |
SCHEMA_NAME |
Ces entrées de journal contiennent des informations sur les schémas utilisés par la règle de mappage des tâches actuelle. Vous pouvez utiliser ces entrées pour déterminer le schéma AWS DMS utilisé pendant une période spécifique au cours de la migration. |
TRANSACTION_ID |
Ces entrées contiennent l’ID de transaction pour chaque modification DML/DDL capturée à partir de la base de données source. Vous pouvez utiliser ces entrées de journal pour déterminer les changements survenus au cours d’une transaction donnée. |
CONNECTION_ID |
Ces entrées contiennent l’ID de connexion. Vous pouvez utiliser ces entrées de journal pour déterminer la connexion AWS DMS utilisée pour chaque étape de migration. |
STATEMENT |
Ces entrées contiennent le code SQL utilisé pour récupérer, traiter et appliquer chaque modification de migration. |
STREAM_POSITION |
Ces entrées contiennent la position dans le fichier journal de transactions pour chaque action de migration sur la base de données source. Le format de ces entrées varie selon le type de moteur de base de données source. Vous pouvez également utiliser ces informations pour déterminer la position de départ d'un point de contrôle de restauration lors de la configuration de la CDC-only réplication. |
Exemples de journalisation
Cette section contient des exemples d’enregistrements de journal que vous pouvez utiliser pour surveiller la réplication et diagnostiquer les problèmes de réplication.
Exemples de journaux de connexion
Cette section contient des exemples de journaux qui incluent les ID de connexion.
2023-02-22T10:09:29 [SOURCE_CAPTURE ]I: Capture record 1 to internal queue from Source {operation:START_REGULAR (43),connectionId:27598, streamPosition:0000124A/6800A778.NOW} (streamcomponent.c:2920) 2023-02-22T10:12:30 [SOURCE_CAPTURE ]I: Capture record 0 to internal queue from Source {operation:IDLE (51),connectionId:27598} (streamcomponent.c:2920) 2023-02-22T11:25:27 [SOURCE_CAPTURE ]I: Capture record 0 to internal queue from Source {operation:IDLE (51), columnName:region,connectionId:27598} (streamcomponent.c:2920)
Exemples de journaux de comportement des tâches
Cette section contient des exemples de journaux relatifs au comportement des tâches de réplication. Vous pouvez utiliser ces informations pour diagnostiquer les problèmes de réplication, tels que le statut IDLE d’une tâche.
Les journaux SOURCE_CAPTURE suivants indiquent qu’aucun événement ne peut être lu dans le fichier journal de la base de données source et contiennent des enregistrements TARGET_APPLY indiquant qu’aucun événement reçu des composants AWS DMS CDC ne s’applique à la base de données cible. Ces événements contiennent également des détails contextuels relatifs à des événements précédemment appliqués.
2023-02-22T11:23:24 [SOURCE_CAPTURE ]I: No Event fetched from wal log (postgres_endpoint_wal_engine.c:1369) 2023-02-22T11:24:29 [TARGET_APPLY ]I: No records received to load or apply on target , waiting for data from upstream. The last context is {operation:INSERT (1), tableName:sales_11, schemaName:public, txnId:18662441, connectionId:17855, statement:INSERT INTO "public"."sales_11"("sales_no","dept_name","sale_amount","sale_date","region") values (?,?,?,?,?),
Exemples de journaux d’instructions SQL
Cette section contient des exemples de journaux relatifs aux instructions SQL exécutées sur les bases de données source et cible. Les instructions SQL que vous voyez dans ces journaux indiquent uniquement l’instruction SQL et ne montrent pas les données. Le journal TARGET_APPLY suivant montre une instruction INSERT exécutée sur la cible.
2023-02-22T11:26:07 [TARGET_APPLY ]I: Applied record 2193305 to target {operation:INSERT (1), tableName:sales_111, schemaName:public, txnId:18761543, connectionId:17855, statement:INSERT INTO "public"."sales_111"("sales_no","dept_name","sale_amount","sale_date","region") values (?,?,?,?,?),
Limitations
Les limites suivantes s'appliquent à la journalisation AWS DMS contextuelle :
Tout en AWS DMS créant une journalisation minimale pour tous les types de points de terminaison, une journalisation contextuelle étendue spécifique au moteur n'est disponible que pour les types de points de terminaison suivants. Nous vous recommandons d’activer la journalisation du contexte lorsque vous utilisez ces types de point de terminaison.
MySQL
PostgreSQL
Oracle
Microsoft SQL Server
MongoDB / Amazon DocumentDB
Amazon S3
