Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
JDBCgénération automatique de schémas
Amazon DocumentDB est une base de données de documents et ne possède donc pas le concept de tables et de schémas. Cependant, les outils de BI tels que Tableau s'attendent à ce que la base de données qu'ils connectent présente un schéma. Plus précisément, lorsque la connexion au JDBC pilote doit obtenir le schéma de la collection dans la base de données, elle interroge toutes les collections de la base de données. Le pilote déterminera si une version mise en cache du schéma pour cette collection existe déjà. Si aucune version mise en cache n'existe, elle échantillonne la collection pour les documents et crée un schéma basé sur le comportement suivant.
Rubriques
Limites de génération de schémas
Le JDBC pilote DocumentDB limite la longueur des identifiants à 128 caractères. Le générateur de schéma peut tronquer la longueur des identifiants générés (noms de tables et noms de colonnes) pour s'assurer qu'ils correspondent à cette limite.
Options de méthode de numérisation
Le comportement d'échantillonnage peut être modifié à l'aide des options de chaîne de connexion ou de source de données.
-
scanMethod= <option>
-
random - (par défaut) - Les exemples de documents sont renvoyés dans un ordre aléatoire.
-
idForward- Les exemples de documents sont renvoyés par ordre d'identification.
-
idReverse- Les exemples de documents sont renvoyés dans l'ordre inverse de leur identifiant.
-
tous - Échantillonnez tous les documents de la collection.
-
-
scanLimit= <n>- Le nombre de documents à échantillonner. La valeur doit être un nombre entier positif. La valeur par défaut est 1000. Si la scanMethodvaleur est définie sur tous, cette option est ignorée.
Types de données Amazon DocumentDB
Le serveur Amazon DocumentDB prend en charge un certain nombre de types de données MongoDB. Les types de données pris en charge et les types de JDBC données associés sont répertoriés ci-dessous.
| Type de données MongoDB | Pris en charge dans DocumentDB | JDBCType de données |
|---|---|---|
| Données binaires | Oui | VARBINARY |
| Booléen | Oui | BOOLEAN |
| Double | Oui | DOUBLE |
| Entier 32 bits | Oui | INTEGER |
| Entier 64 bits | Oui | BIGINT |
| Chaîne | Oui | VARCHAR |
| ObjectId | Oui | VARCHAR |
| Date | Oui | TIMESTAMP |
| Null | Oui | VARCHAR |
| Expression régulière | Oui | VARCHAR |
| Horodatage | Oui | VARCHAR |
| MinKey | Oui | VARCHAR |
| MaxKey | Oui | VARCHAR |
| Objet | Oui | table virtuelle |
| Tableau | Oui | table virtuelle |
| Decimal128 | Non | DECIMAL |
| JavaScript | Non | VARCHAR |
| JavaScript (avec lunette) | Non | VARCHAR |
| Non défini | Non | VARCHAR |
| Symbol | Non | VARCHAR |
| DBPointer(4,0 et plus) | Non | VARCHAR |
Cartographie de champs de documents scalaires
Lors de la numérisation d'un échantillon de documents d'une collection, le JDBC pilote crée un ou plusieurs schémas pour représenter les échantillons de la collection. En général, un champ scalaire du document correspond à une colonne du schéma de table. Par exemple, dans une collection nommée team et dans un seul document{ "_id" : "112233", "name" :
"Alastair", "age": 25 }, cela correspondrait au schéma :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| équipe | identifiant de l'équipe | VARCHAR | PK |
| équipe | name | VARCHAR | |
| équipe | age | INTEGER |
Promotion des conflits liés aux types de données
Lors de la numérisation des documents échantillonnés, il est possible que les types de données d'un champ ne soient pas cohérents d'un document à l'autre. Dans ce cas, le JDBC pilote fera passer le type de JDBC données à un type de données commun qui conviendra à tous les types de données des documents échantillonnés.
Par exemple :
{ "_id" : "112233", "name" : "Alastair", "age" : 25 } { "_id" : "112244", "name" : "Benjamin", "age" : "32" }
Le champ d'âge est de type entier 32 bits dans le premier document mais de type chaîne dans le second document. Ici, le JDBC pilote va promouvoir le type de JDBC données VARCHAR pour gérer l'un ou l'autre type de données lorsqu'il est rencontré.
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| équipe | identifiant de l'équipe | VARCHAR | PK |
| équipe | name | VARCHAR | |
| équipe | age | VARCHAR |
Promotion des conflits scalaires
Le schéma suivant montre la manière dont les conflits de type de données scalaire-scalaire sont résolus.
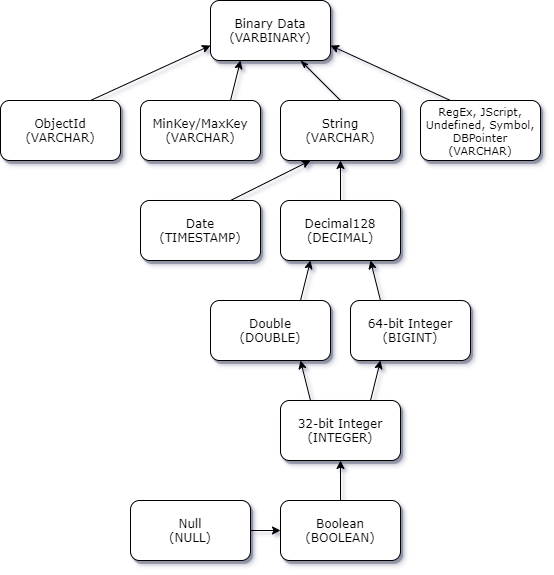
Promotion des conflits de type complexe scalaire
À l'instar des conflits de type scalaire-scalaire, le même champ dans différents documents peut contenir des types de données contradictoires entre complexes (tableau et objet) et scalaires (entier, booléen, etc.). Tous ces conflits sont résolus (promus) VARCHAR pour ces domaines. Dans ce cas, les données du tableau et de l'objet sont renvoyées en tant que JSON représentation.
Exemple de conflit entre un tableau intégré et un champ de chaîne :
{ "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] } { "_id":"112244", "name":"Joan Starr", "subscriptions":1 }
L'exemple ci-dessus correspond au schéma de la table customer2 :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| client 2 | identifiant customer2 | VARCHAR | PK |
| client 2 | name | VARCHAR | |
| client 2 | abonnement | VARCHAR |
et la table virtuelle customer1_subscription :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| customer1_abonnements | identifiant client1 | VARCHAR | PK/FK |
| customer1_abonnements | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_abonnements | value | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | code | VARCHAR |
Gestion des types de données d'objets et de tableaux
Jusqu'à présent, nous avons uniquement décrit la façon dont les types de données scalaires sont mappés. Les types de données Object et Array sont (actuellement) mappés à des tables virtuelles. Le JDBC pilote créera une table virtuelle pour représenter les champs d'un objet ou d'un tableau dans un document. Le nom de la table virtuelle mappée concaténera le nom de la collection d'origine suivi du nom du champ séparé par un trait de soulignement (« _ »).
La clé primaire de la table de base (« _id ») prend un nouveau nom dans la nouvelle table virtuelle et est fournie en tant que clé étrangère à la table de base associée.
Pour les champs de type tableau intégré, des colonnes d'index sont générées pour représenter l'index dans le tableau à chaque niveau du tableau.
Exemple de champ d'objet intégré
Pour les champs d'objet d'un document, un mappage vers une table virtuelle est créé par le JDBC pilote.
{ "Collection: customer", "_id":"112233", "name":"George Jackson", "address":{ "address1":"123 Avenue Way", "address2":"Apt. 5", "city":"Hollywood", "region":"California", "country":"USA", "code":"90210" } }
L'exemple ci-dessus correspond au schéma de la table des clients :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| customer | identifiant du client | VARCHAR | PK |
| customer | name | VARCHAR |
et la table virtuelle customer_address :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| customer_address | identifiant du client | VARCHAR | PK/FK |
| customer_address | adresse1 | VARCHAR | |
| customer_address | adresse2 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | code | VARCHAR |
Exemple de champ de tableau intégré
Pour les champs de tableau d'un document, un mappage vers une table virtuelle est également créé par le JDBC pilote.
{ "Collection: customer1", "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] }
L'exemple ci-dessus correspond au schéma de la table customer1 :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| client 1 | identifiant client1 | VARCHAR | PK |
| client 1 | name | VARCHAR |
et la table virtuelle customer1_subscription :
| Nom de la table | Nom de la colonne | Type de données | Clé |
|---|---|---|---|
| customer1_abonnements | identifiant client1 | VARCHAR | PK/FK |
| customer1_abonnements | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_abonnements | value | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | code | VARCHAR |
