Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connexion à Amazon DocumentDB en tant que jeu de répliques
Lorsque vous développez avec Amazon DocumentDB (compatible avec MongoDB), nous vous recommandons de vous connecter à votre cluster en tant que jeu de répliques et de distribuer les lectures aux instances de réplication à l'aide des fonctionnalités de préférence de lecture intégrées de votre pilote. Cette section explique en détail ce que cela signifie et décrit comment vous pouvez vous connecter à votre cluster Amazon DocumentDB en tant que jeu de répliques en utilisant le SDK pour Python comme exemple.
Amazon DocumentDB possède trois points de terminaison que vous pouvez utiliser pour vous connecter à votre cluster :
-
Point de terminaison de cluster
-
Point de terminaison du lecteur
-
Points de terminaison d’instance
Dans la plupart des cas, lorsque vous vous connectez à Amazon DocumentDB, nous vous recommandons d'utiliser le point de terminaison du cluster. Il s'agit d'un CNAME qui pointe vers l'instance principale de votre cluster, comme illustré dans le schéma suivant.
Lorsque vous utilisez un tunnel SSH, nous vous recommandons de vous connecter à votre cluster à l'aide du point de terminaison de cluster et de ne pas essayer de vous connecter en mode d’ensemble de réplicas (c'est-à-dire en spécifiant replicaSet=rs0 dans votre chaîne de connexion), car cela entraînerait une erreur.
Note
Pour plus d'informations sur les points de terminaison Amazon DocumentDB, consultez. Points de terminaison Amazon DocumentDB
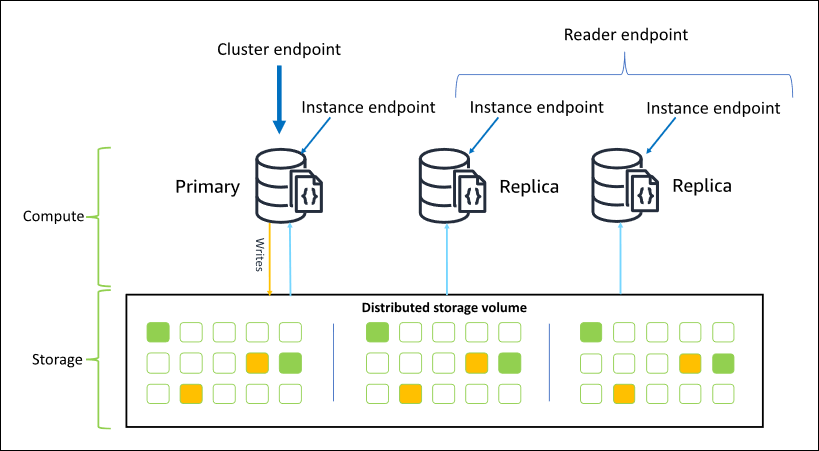
À l'aide du point de terminaison du cluster, vous pouvez vous connecter à votre cluster en mode jeu de réplicas. Vous pouvez ensuite utiliser les fonctionnalités intégrées du pilote de préférence de lecture. Dans l'exemple suivant, la spécification /?replicaSet=rs0 signifie au kit SDK que vous souhaitez vous connecter en tant que jeu de réplicas. Si vous omettez /?replicaSet=rs0', le client achemine toutes les demandes vers le point de terminaison du cluster, c'est-à-dire votre instance principale.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
L'avantage de se connecter en tant qu'ensemble de réplicas est qu'il permet à votre kit SDK de découvrir automatiquement la topographie du cluster, y compris lorsque des instances sont ajoutées ou supprimées du cluster. Vous pouvez ensuite utiliser votre cluster plus efficacement en acheminant les demandes de lecture vers vos instances de réplica.
Lorsque vous vous connectez en tant que jeu de réplicas, vous pouvez spécifier la readPreference pour la connexion. Si vous spécifiez comme préférence de lecture secondaryPreferred, le client achemine les requêtes en lecture vers vos réplicas et écrit les requêtes vers votre instance principale (comme dans le diagramme suivant). Il s'agit d'une meilleure utilisation des ressources de votre cluster. Pour de plus amples informations, veuillez consulter Options de préférence de lecture.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
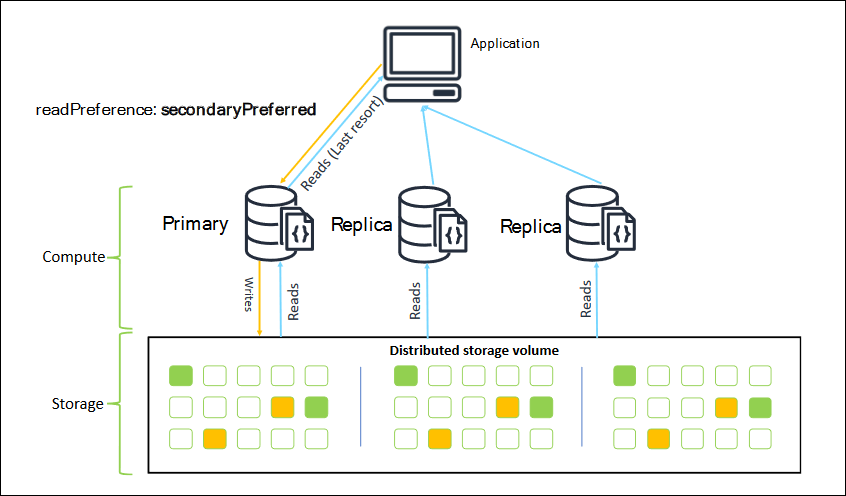
Les lectures effectuées à partir de répliques Amazon DocumentDB sont finalement cohérentes. Elles renvoient les données dans le même ordre qu'elles ont été écrites sur le nœud principal, et le retard de réplication est souvent inférieur à 50 ms. Vous pouvez surveiller le décalage de réplication de votre cluster à l'aide CloudWatch des métriques Amazon DBInstanceReplicaLag etDBClusterReplicaLagMaximum. Pour de plus amples informations, veuillez consulter Surveillance d'Amazon DocumentDB avec CloudWatch.
Contrairement à l'architecture de base de données monolithique traditionnelle, Amazon DocumentDB sépare le stockage et le calcul. En raison de cette architecture moderne, nous vous encourageons à effectuer une mise à l'échelle en lecture sur les instances de réplica. Les lectures sur les instances de réplica ne bloquent pas les écritures répliquées à partir de l'instance principale. Vous pouvez ajouter jusqu'à 15 instances de réplica en lecture dans un cluster et monter en charge pour atteindre plusieurs millions de lectures par seconde.
L'avantage clé de la connexion en tant qu'ensemble de réplicas et de la distribution des lectures sur les réplicas est qu'elle augmente les ressources globales de votre cluster disponibles pour travailler pour votre application. Nous vous recommandons de vous connecter en tant qu'ensemble de réplicas à titre de bonne pratique. De plus, nous le recommandons le plus souvent dans les scénarios suivants :
-
Vous utilisez presque 100 % d'UC sur votre instance principale.
-
Le taux d'accès au cache du tampon est proche de zéro.
-
Vous atteignez les limites de connexion ou de curseur pour une instance individuelle.
La mise à l'échelle d'une taille d'instance de cluster est une option et, dans certains cas, peut être le meilleur moyen de dimensionner le cluster. Mais vous devez également réfléchir à la façon de mieux utiliser les réplicas que vous avez déjà dans votre cluster. Cela vous permet d'augmenter la mise à l'échelle sans avoir à augmenter le coût d'utilisation d'un type d'instance plus grand. Nous vous recommandons également de surveiller ces limites et d'émettre des alertes à ce sujet (c'est-à-dire CPUUtilizationDatabaseConnections, etBufferCacheHitRatio) à l'aide d' CloudWatch alarmes afin de savoir quand une ressource est fortement utilisée.
Pour plus d’informations, consultez les rubriques suivantes :
Utilisation de connexions au cluster
Envisagez le scénario d'utilisation de toutes les connexions de votre cluster. Par exemple, une instance r5.2xlarge a une limite de 4 500 connexions (et 450 curseurs ouverts). Si vous créez un cluster Amazon DocumentDB à trois instances et que vous vous connectez uniquement à l'instance principale à l'aide du point de terminaison du cluster, les limites de votre cluster pour les connexions ouvertes et les curseurs sont respectivement de 4 500 et 450. Vous pouvez atteindre ces limites si vous construisez des applications qui utilisent de nombreux travaux qui s'exécutent dans des conteneurs. Les conteneurs ouvrent un certain nombre de connexions simultanément et saturent le cluster.
Au lieu de cela, vous pouvez vous connecter au cluster Amazon DocumentDB en tant que jeu de répliques et distribuer vos lectures aux instances de réplication. Vous pouvez ensuite tripler efficacement le nombre de connexions et de curseurs disponibles dans le cluster pour atteindre 13 500 et 1 350 respectivement. L'ajout d'instances supplémentaires au cluster augmente uniquement le nombre de connexions et de curseurs pour les charges de travail de lecture. Si vous avez besoin d'augmenter le nombre de connexions pour les écritures dans votre cluster, nous vous recommandons d'augmenter la taille d'instance.
Note
Le nombre de connexions pour les instances large, xlarge et 2xlarge augmente avec la taille de l'instance jusqu'à 4 500. Le nombre maximal de connexions par instance pour les instances 4xlarge ou supérieures est de 4 500. Pour plus d'informations sur les limites par type d'instance, consultez Limites d’instance.
En général, nous vous déconseillons de vous connecter à votre cluster à l'aide de secondary comme préférence en lecture. Cela est dû au fait que s'il n'y a pas d'instances de réplica dans votre cluster, les lectures échouent. Supposons, par exemple, que vous disposiez d'un cluster Amazon DocumentDB à deux instances avec une instance principale et une réplique. Si le réplica a un problème, les demandes de lecture à partir d'un groupe de connexions défini comme secondary échouent. L'avantage de secondaryPreferred est que si le client ne parvient pas à trouver une instance de réplica appropriée à laquelle se connecter, il revient à l'instance principale pour les lectures.
Plusieurs pools de connexions
Dans certains scénarios, les lectures d'une application doivent avoir une cohérence entre lecture après écriture, qui ne peut être effectuée qu'à partir de l'instance principale d'Amazon DocumentDB. Dans ces scénarios, vous pouvez créer deux groupes de connexions client : un pour les écritures et un pour les lectures nécessitant une cohérence en lecture après écriture. Pour ce faire, votre code doit ressembler à ce qui suit.
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
Une autre option consiste à créer un seul groupe de connexions et à remplacer la préférence de lecture pour une collection donnée.
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
Résumé
Pour mieux utiliser les ressources de votre cluster, nous vous recommandons de vous connecter à votre cluster à l'aide du mode du jeu de réplicas. Si cela convient à votre application, vous pouvez la dimensionner en répartissant vos lectures sur les instances de réplica.
