Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Clusters élastiques Amazon DocumentDB : comment ça marche
Les rubriques de cette section fournissent des informations sur les mécanismes et les fonctions qui alimentent les clusters élastiques Amazon DocumentDB.
Rubriques
Sharding élastique de clusters Amazon DocumentDB
Les clusters élastiques Amazon DocumentDB utilisent le sharding basé sur le hachage pour partitionner les données dans un système de stockage distribué. Le sharding, également appelé partitionnement, divise les grands ensembles de données en petits ensembles de données répartis sur plusieurs nœuds, ce qui vous permet d'étendre votre base de données au-delà des limites de mise à l'échelle verticale. Les clusters élastiques utilisent la séparation, ou le « découplage », du calcul et du stockage dans Amazon DocumentDB, ce qui vous permet d'évoluer indépendamment les uns des autres. Plutôt que de repartitionner les collections en déplaçant de petits morceaux de données entre les nœuds de calcul, les clusters élastiques copient les données de manière efficace dans le système de stockage distribué.
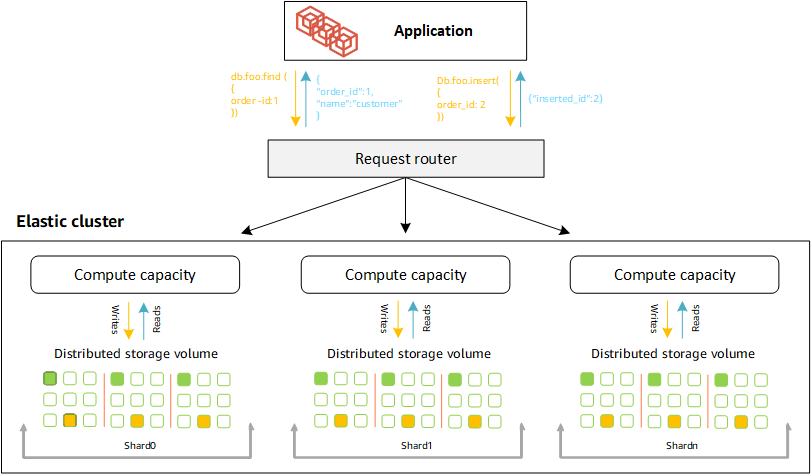
Définitions de partitions
Définitions de la nomenclature des partitions :
Shard : un shard fournit le calcul nécessaire à un cluster élastique. Il comportera une seule instance d'écriture et 0 à 15 répliques de lecture. Par défaut, une partition comporte deux instances : une instance d'écriture et une réplique en lecture unique. Vous pouvez configurer un maximum de 32 partitions et chaque instance de partition peut avoir un maximum de 64 vCPU.
Clé de partition : une clé de partition est un champ obligatoire dans vos documents JSON dans les collections fragmentées que les clusters élastiques utilisent pour distribuer le trafic de lecture et d'écriture vers le fragment correspondant.
Collection fragmentée : une collection fragmentée est une collection dont les données sont réparties sur un cluster élastique sous forme de partitions de données.
Partition : une partition est une portion logique de données fragmentées. Lorsque vous créez une collection fragmentée, les données sont automatiquement organisées en partitions au sein de chaque partition en fonction de la clé de partition. Chaque partition possède plusieurs partitions.
Répartition des données entre des partitions configurées
Créez une clé de partition dotée de nombreuses valeurs uniques. Une bonne clé de partition partitionnera uniformément vos données entre les partitions sous-jacentes, offrant ainsi à votre charge de travail le meilleur débit et les meilleures performances. L'exemple suivant montre des données de nom d'employé qui utilisent une clé de partition nommée « user_id » :
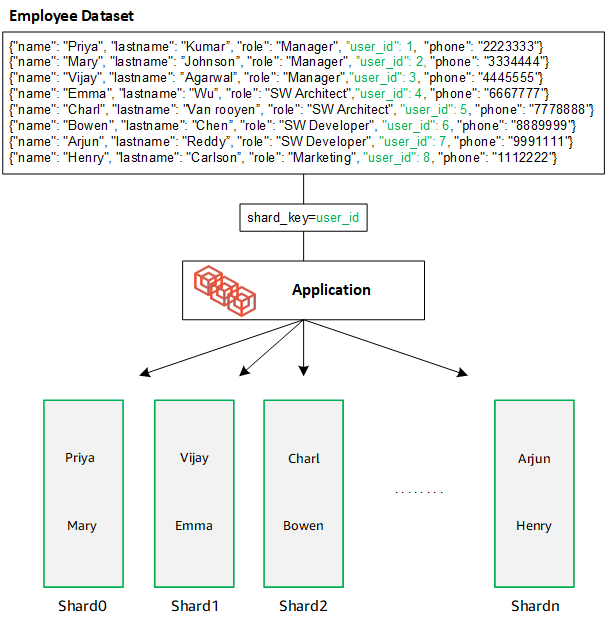
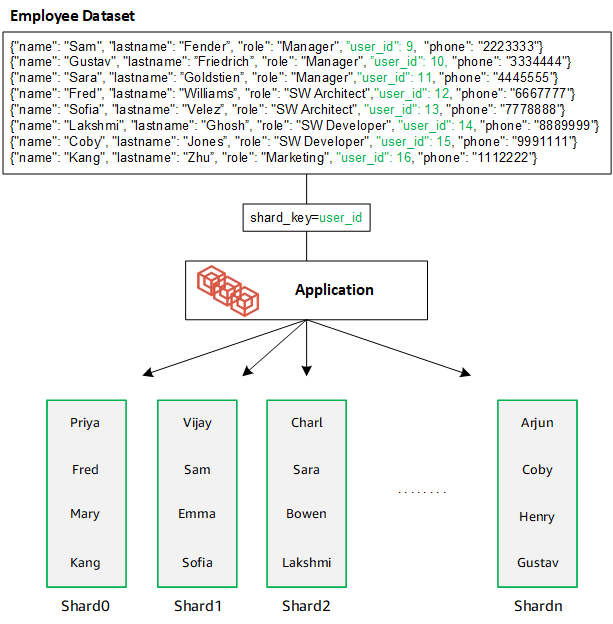
DocumentDB utilise le hachage pour partitionner vos données entre les partitions sous-jacentes. Les données supplémentaires sont insérées et distribuées de la même manière :
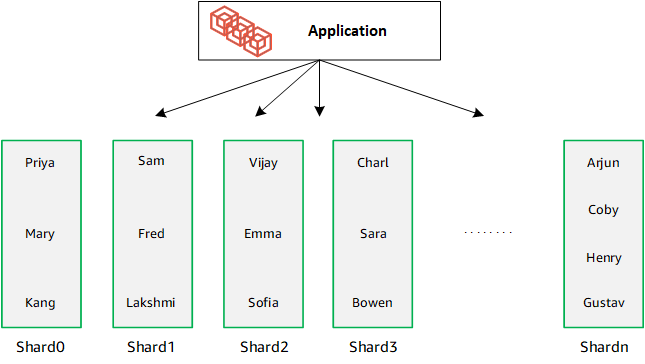
Lorsque vous agrandissez votre base de données en ajoutant des partitions supplémentaires, Amazon DocumentDB redistribue automatiquement les données :
Migration élastique de clusters
Amazon DocumentDB prend en charge la migration des données partitionnées MongoDB vers des clusters élastiques. Les méthodes de migration hors ligne, en ligne et hybrides sont prises en charge. Pour de plus amples informations, veuillez consulter Migration vers Amazon DocumentDB.
Mise à l'échelle élastique des clusters
Les clusters élastiques Amazon DocumentDB permettent d'augmenter le nombre de partitions (scalage externe) dans votre cluster élastique, ainsi que le nombre de vCPU appliqués à chaque partition (scalabilité). Vous pouvez également réduire le nombre de partitions et la capacité de calcul (vCPU) selon les besoins.
Pour connaître les meilleures pratiques en matière de dimensionnement, voirMise à l'échelle des clusters élastiques.
Note
Cluster-level la mise à l'échelle est également disponible. Pour de plus amples informations, veuillez consulter Dimensionnement des clusters Amazon DocumentDB.
Fiabilité du cluster élastique
Amazon DocumentDB est conçu pour être fiable, durable et tolérant aux pannes. Pour améliorer la disponibilité, les clusters élastiques déploient deux nœuds par partition placés dans différentes zones de disponibilité. Amazon DocumentDB inclut plusieurs fonctionnalités automatiques qui en font une solution de base de données fiable. Pour de plus amples informations, veuillez consulter Fiabilité d'Amazon DocumentDB.
Stockage et disponibilité élastiques en cluster
Les données Amazon DocumentDB sont stockées dans un volume de cluster, qui est un volume virtuel unique qui utilise des disques SSD. Un volume de cluster se compose de six copies de vos données, qui sont répliquées automatiquement sur plusieurs zones de disponibilité au sein d'une même AWS région. Cette réplication garantit que vos données sont hautement durables, avec une possibilité moindre de perte des données. Elle permet également de vous assurer que votre cluster est plus disponible pendant un basculement, car les copies de vos données existent déjà dans d'autres zones de disponibilité. Pour plus de détails sur le stockage, la haute disponibilité et la réplication, consultezAmazon DocumentDB : comment ça marche.
Différences fonctionnelles entre Amazon DocumentDB 4.0 et les clusters élastiques
Les différences fonctionnelles suivantes existent entre Amazon DocumentDB 4.0 et les clusters élastiques.
Les résultats provenant de
topetcollStatssont partitionnés par fragments. Pour les collections fragmentées, les données sont réparties entre plusieurs partitions et lescollStatsrapports sont agrégéscollScansà partir des partitions.Les statistiques de collecte provenant de
topetcollStatspour les collections fragmentées sont réinitialisées lorsque le nombre de partitions du cluster est modifié.Le rôle intégré de sauvegarde est désormais compatible
serverStatus. Action : les développeurs et les applications dotés d'un rôle de sauvegarde peuvent collecter des statistiques sur l'état du cluster Amazon DocumentDB.Le
SecondaryDelaySecschamp est remplacéslaveDelaydans lareplSetGetConfigsortie.La
hellocommande remplaceisMaster-hellorenvoie un document qui décrit le rôle du cluster élastique.Dans les clusters élastiques,
$elemMatchl'opérateur correspond uniquement aux documents du premier niveau d'imbrication d'un tableau. Dans Amazon DocumentDB 4.0, l'opérateur parcourt tous les niveaux avant de renvoyer les documents correspondants. Par exemple :
db.foo.insert( [ {a: {b: 5}}, {a: {b: [5]}}, {a: {b: [3, 7]}}, {a: [{b: 5}]}, {a: [{b: 3}, {b: 7}]}, {a: [{b: [5]}]}, {a: [{b: [3, 7]}]}, {a: [[{b: 5}]]}, {a: [[{b: 3}, {b: 7}]]}, {a: [[{b: [5]}]]}, {a: [[{b: [3, 7]}]]} ]); // Elastic clusters > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } // Docdb 4.0: traverse more than one level deep > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } { "a" : [ [ { "b" : [ 5 ] } ] ] }
La projection « $ » dans Amazon DocumentDB 4.0 renvoie tous les documents avec tous les champs. Avec les clusters élastiques, la
findcommande avec une projection « $ » renvoie les documents qui correspondent au paramètre de requête contenant uniquement le champ correspondant à la projection « $ ».Dans les clusters élastiques,
findles commandes avec les paramètres de$optionsrequête$regexet de requête renvoient une erreur : « Impossible de définir les options à la fois dans $regex et $options. »
Avec les clusters élastiques, renvoie
$indexOfCPdésormais « -1 » lorsque :la sous-chaîne est introuvable dans le
string expression, oustartest un nombre supérieur àend, oustartest un nombre supérieur à la longueur en octets de la chaîne.
Dans Amazon DocumentDB 4.0,
$indexOfCPrenvoie « 0 » lorsque lastartposition est supérieure à un nombreendou à la longueur en octets de la chaîne.Avec les clusters élastiques, les opérations de projection dans
_id fields, par exemple{"_id.nestedField" : 1}, renvoient des documents qui incluent uniquement le champ projeté. Par ailleurs, dans Amazon DocumentDB 4.0, les commandes de projection de champs imbriqués ne filtrent aucun document.
