Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Activation de l'emprunt d'identité pour contrôler l'activité des utilisateurs et des tâches Spark
Note
EMRLes blocs-notes sont disponibles sous forme d'espaces de travail de EMR studio dans la console. Le bouton Créer un espace de travail de la console vous permet de créer de nouveaux blocs-notes. Pour accéder aux espaces de travail ou les créer, les utilisateurs de EMR Notebooks ont besoin d'autorisations de IAM rôle supplémentaires. Pour plus d'informations, consultez Amazon EMR Notebooks are Amazon EMR Studio Workspaces dans la console et dans la console Amazon EMR.
EMRNotebooks vous permet de configurer l'usurpation d'identité d'un utilisateur sur un cluster Spark. Cette fonctionnalité vous permet de suivre les tâches d'activité lancées à partir de l'éditeur de bloc-notes. En outre, EMR Notebooks intègre un widget Jupyter Notebook pour afficher les détails des tâches Spark ainsi que les résultats des requêtes dans l'éditeur de bloc-notes. Le widget est disponible par défaut et ne nécessite aucune configuration spéciale. Toutefois, pour consulter les serveurs d'historique, votre client doit être configuré pour afficher les interfaces EMR Web Amazon hébergées sur le nœud principal.
Configuration de l'emprunt d'identité d'un utilisateur Spark
Par défaut, les tâches Spark que les utilisateurs soumettent à l'aide de l'éditeur de bloc-notes semblent provenir d'une identité d'utilisateur livy indistincte. Vous pouvez configurer l'emprunt d'identité de l'utilisateur pour le cluster afin que ces tâches soient associées à l'identité de l'utilisateur qui a exécuté le code à la place. HDFSdes annuaires d'utilisateurs sur le nœud principal sont créés pour chaque identité d'utilisateur qui exécute le code dans le bloc-notes. Par exemple, si l'utilisateur NbUser1 exécute du code à partir de l'éditeur de bloc-notes, vous pouvez vous connecter au nœud primaire et voir que hadoop fs -ls /user affiche le répertoire /user/user_NbUser1.
Vous activez cette fonctionnalité en définissant des propriétés dans les classifications de configuration livy-conf et core-site. Cette fonctionnalité n'est pas disponible par défaut lorsque Amazon EMR crée un cluster avec un bloc-notes. Pour plus d'informations sur l'utilisation des classifications de configuration pour personnaliser les applications, consultez la section Configuration des applications dans le Amazon EMR Release Guide.
Utilisez les classifications et valeurs de configuration suivantes pour permettre l'usurpation d'identité utilisateur pour les EMR blocs-notes :
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
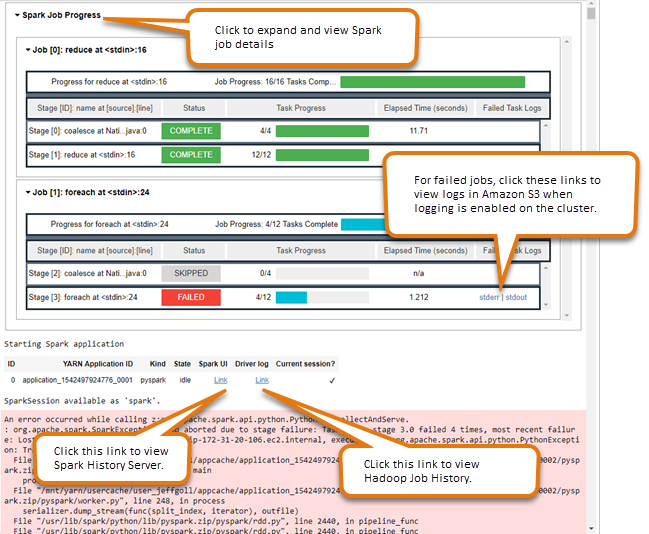
Utilisation du widget de surveillance de tâche Spark
Lorsque vous exécutez du code dans l'éditeur de bloc-notes qui exécute des tâches Spark sur le EMR cluster, la sortie inclut un widget Jupyter Notebook pour la surveillance des tâches Spark. Le widget fournit des détails de la tâche et des liens utiles vers la page de serveur d'historique Spark et la page de l'historique des tâches Hadoop, ainsi que des liens pratiques vers les journaux de tâche dans Amazon S3 pour les tâches échouées.
Pour afficher les pages du serveur d'historique sur le nœud principal du cluster, vous devez configurer un SSH client et un proxy appropriés. Pour de plus amples informations, veuillez consulter Afficher les interfaces Web hébergées sur des EMR clusters Amazon. Pour afficher les journaux dans Amazon S3, la journalisation de cluster doit être activée (la valeur par défaut pour les nouveaux clusters). Pour de plus amples informations, veuillez consulter Afficher des fichiers journaux archivés dans Amazon S3.
Voici un exemple de surveillance d'une tâche Spark.