Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Plug-in Apache Hive pour l'intégration de Ranger à Amazon EMR
Apache Hive est un moteur d'exécution populaire au sein de l'écosystème Hadoop. Amazon EMR fournit un plugin Apache Ranger permettant de fournir des contrôles d'accès précis pour Hive. Le plug-in est compatible avec le serveur d'administration open source Apache Ranger version 2.0 et ultérieure.
Rubriques
Fonctionnalités prises en charge
Le plugin Apache Ranger pour Hive on EMR prend en charge toutes les fonctionnalités du plugin open source, notamment les contrôles d'accès aux bases de données, aux tables et aux colonnes, le filtrage des lignes et le masquage des données. Pour un tableau des commandes Hive et des autorisations Ranger associées, consultez Mappage descommandes Hive aux autorisations Ranger
Installation de la configuration du service
Le plugin Apache Hive est compatible avec la définition de service Hive existante dans Apache Hive Hadoop. SQL
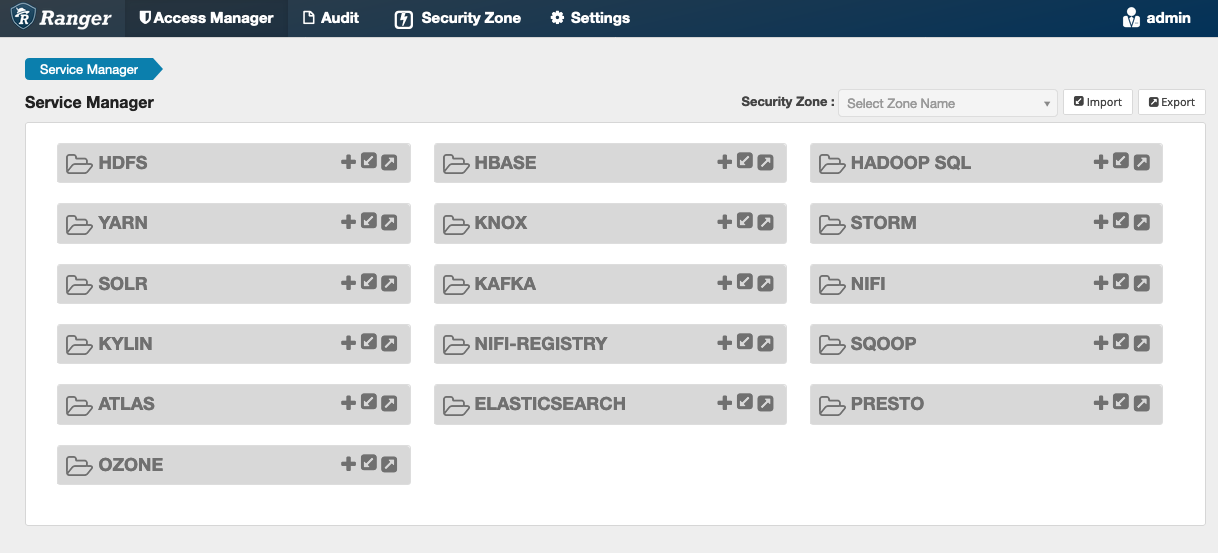
Si vous n'avez pas d'instance du service sous HadoopSQL, comme indiqué ci-dessus, vous pouvez en créer une. Cliquez sur le + à côté de HadoopSQL.
-
Nom du service (s'il est affiché) : entrez le nom du service. La valeur suggérée est
amazonemrhive. Notez le nom de ce service : il est nécessaire lors de la création d'une configuration EMR de sécurité. -
Nom d'affichage : entrez le nom à afficher pour le service. La valeur suggérée est
amazonemrhive.
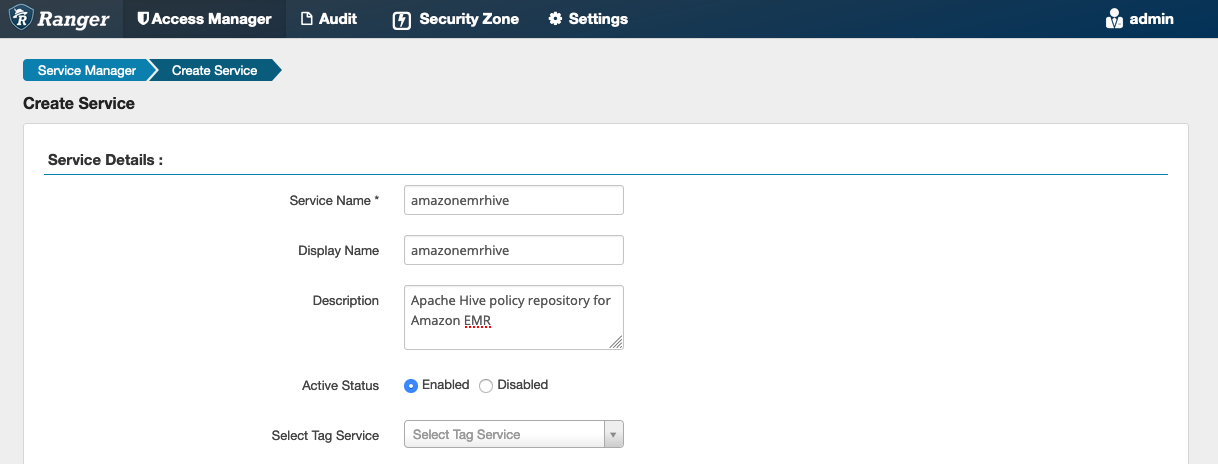
Les propriétés de configuration d'Apache Hive sont utilisées pour établir une connexion avec votre serveur d'administration Apache Ranger avec un HiveServer 2 pour implémenter la saisie automatique lors de la création de politiques. Les propriétés ci-dessous ne doivent pas nécessairement être exactes si vous ne disposez pas d'un processus HiveServer 2 persistant et peuvent être renseignées avec n'importe quelle information.
-
Nom d'utilisateur : entrez un nom d'utilisateur pour la JDBC connexion à une instance d'une instance HiveServer 2.
-
Mot de passe : entrez le mot de passe pour le nom d'utilisateur ci-dessus.
-
jdbc.driver. ClassName: Entrez le nom de classe de la JDBC classe pour la connectivité Apache Hive. La valeur par défaut peut être utilisée.
-
jdbc.url : Entrez la chaîne de JDBC connexion à utiliser lors de la connexion à 2. HiveServer
-
Nom commun du certificat : champ CN du certificat utilisé pour se connecter au serveur d'administration à partir d'un plug-in client. Cette valeur doit correspondre au champ CN de votre TLS certificat créé pour le plugin.
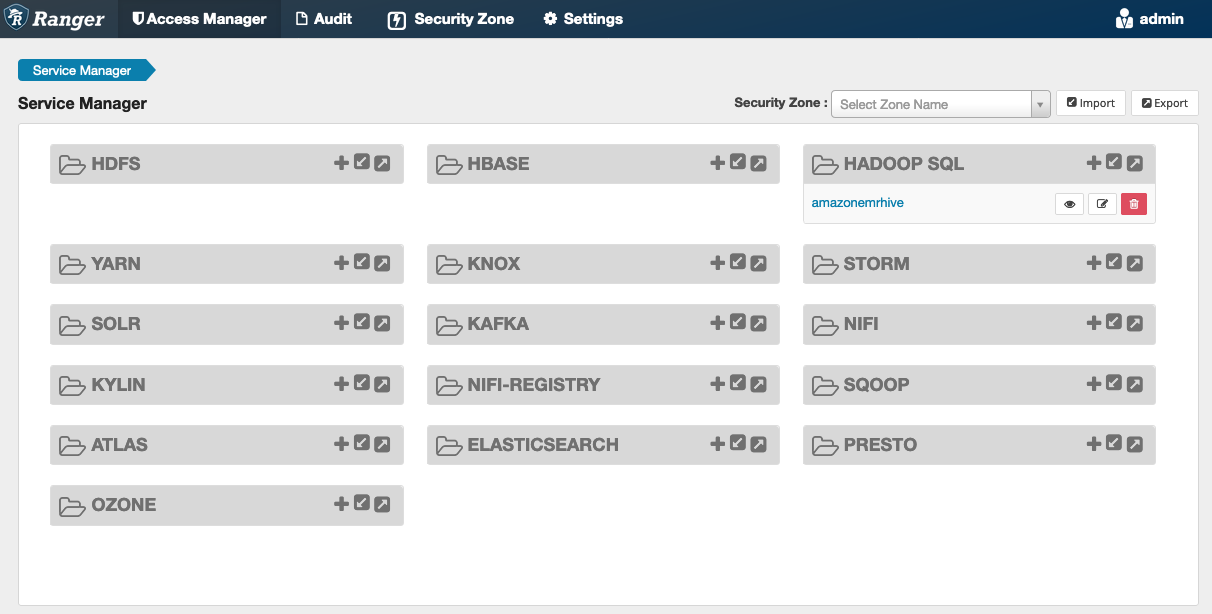
Le bouton Tester la connexion vérifie si les valeurs ci-dessus peuvent être utilisées pour établir une connexion réussie à l'instance HiveServer 2. Une fois le service créé avec succès, le gestionnaire de services devrait ressembler à ce qui suit :
Considérations
Serveur de métadonnées Hive
Le serveur de métadonnées Hive n'est accessible que par des moteurs fiables, en particulier Hive et emr_record_server, pour se protéger contre tout accès non autorisé. Le serveur de métadonnées Hive est également accessible par tous les nœuds du cluster. Le port 9083 requis permet à tous les nœuds d'accéder au nœud principal.
Authentification
Par défaut, Apache Hive est configuré pour s'authentifier à l'aide de Kerberos, comme indiqué dans la configuration de sécurité. EMR HiveServer2 peuvent également être configurés pour authentifier les utilisateurs à l'aide LDAP de. Consultez LDAPImplémentation de l'authentification pour Hive sur un EMR cluster Amazon multi-tenant
Limites
Les limitations actuelles du plugin Apache Hive sur Amazon EMR 5.x sont les suivantes :
-
Les rôles Hive ne sont actuellement pas pris en charge. Les instructions Grant, Revoke ne sont pas prises en charge.
-
Hive n'CLIest pas pris en charge. JDBC/Beeline est le seul moyen autorisé de connecter Hive.
-
hive.server2.builtin.udf.blacklistla configuration doit être renseignée avec UDFs les informations que vous jugez dangereuses.
