Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Plug-in Apache Spark
Amazon EMR a intégré EMR RecordServer Spark pour fournir un contrôle d'accès précis. SQL EMR RecordServer est un processus privilégié qui s'exécute sur tous les nœuds d'un cluster compatible avec Apache Ranger. Lorsqu'un pilote ou un exécuteur Spark exécute une SQL instruction Spark, toutes les métadonnées et demandes de données passent par le RecordServer. Pour en savoir plus EMR RecordServer, consultez la EMRComposants Amazon page.
Rubriques
Fonctionnalités prises en charge
| SQLDéclaration/action du Ranger | STATUS | EMRVersion prise en charge |
|---|---|---|
|
SELECT |
Pris en charge |
À partir de 5.32 |
|
SHOW DATABASES |
Pris en charge |
À partir de 5.32 |
|
SHOW COLUMNS |
Pris en charge |
À partir de 5.32 |
|
SHOW TABLES |
Pris en charge |
À partir de 5.32 |
|
SHOW TABLE PROPERTIES |
Pris en charge |
À partir de 5.32 |
|
DESCRIBE TABLE |
Pris en charge |
À partir de 5.32 |
|
INSERT OVERWRITE |
Pris en charge |
À partir de 5.34 et 6.4 |
| INSERT INTO | Pris en charge | À partir de 5.34 et 6.4 |
|
ALTER TABLE |
Pris en charge |
À partir de 6.4 |
|
CREATE TABLE |
Pris en charge |
Àpartir de 5.35 et 6.7 |
|
CREATE DATABASE |
Pris en charge |
Àpartir de 5.35 et 6.7 |
|
DROP TABLE |
Pris en charge |
Àpartir de 5.35 et 6.7 |
|
DROP DATABASE |
Pris en charge |
Àpartir de 5.35 et 6.7 |
|
DROP VIEW |
Pris en charge |
Àpartir de 5.35 et 6.7 |
|
CREATE VIEW |
Non pris en charge |
Les fonctionnalités suivantes sont prises en charge lors de l'utilisation de Spark SQL :
-
Un contrôle d'accès précis sur les tables du métastore Hive et des politiques peuvent être créées au niveau de la base de données, de la table et de la colonne.
-
Les politiques Apache Ranger peuvent inclure des politiques d'octroi et de refus pour les utilisateurs et les groupes.
-
Les événements d'audit sont soumis à CloudWatch Logs.
Redéployer la définition du service pour utiliser INSERTALTER, ou les instructions DDL
Note
À partir d'Amazon EMR 6.4, vous pouvez utiliser Spark SQL avec les instructions : INSERT INTO INSERTOVERWRITE, ou ALTERTABLE. À partir d'Amazon EMR 6.7, vous pouvez utiliser Spark SQL pour créer ou supprimer des bases de données et des tables. Si vous disposez d'une installation existante sur le serveur Apache Ranger avec des définitions de service Apache Spark déployées, utilisez le code suivant pour redéployer les définitions de service.
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
Installation de la définition du service
L'installation de la définition EMR du service Apache Spark nécessite la configuration du serveur d'administration Ranger. Consultez Configuration du serveur d'administration Ranger.
Pour installer la définition du service Apache Spark, procédez comme suit :
Étape 1 : SSH dans le serveur d'administration Apache Ranger
Par exemple :
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
Étape 2 : téléchargez la définition du service et le plug-in du serveur d'administration Apache Ranger
Dans un répertoire temporaire, téléchargez la définition de service. Cette définition de service est prise en charge par les versions 2.x de Ranger.
mkdir /tmp/emr-spark-plugin/ cd /tmp/emr-spark-plugin/ wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
Étape 3 : Installation du plugin Apache Spark pour Amazon EMR
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
Étape 4 : enregistrer la définition du service Apache Spark pour Amazon EMR
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'
Si cette commande s'exécute correctement, vous verrez apparaître un nouveau service dans votre interface utilisateur d'administration de Ranger appelé SPARK « AMAZON EMR - - », comme indiqué dans l'image suivante (la version 2.0 de Ranger est illustrée).
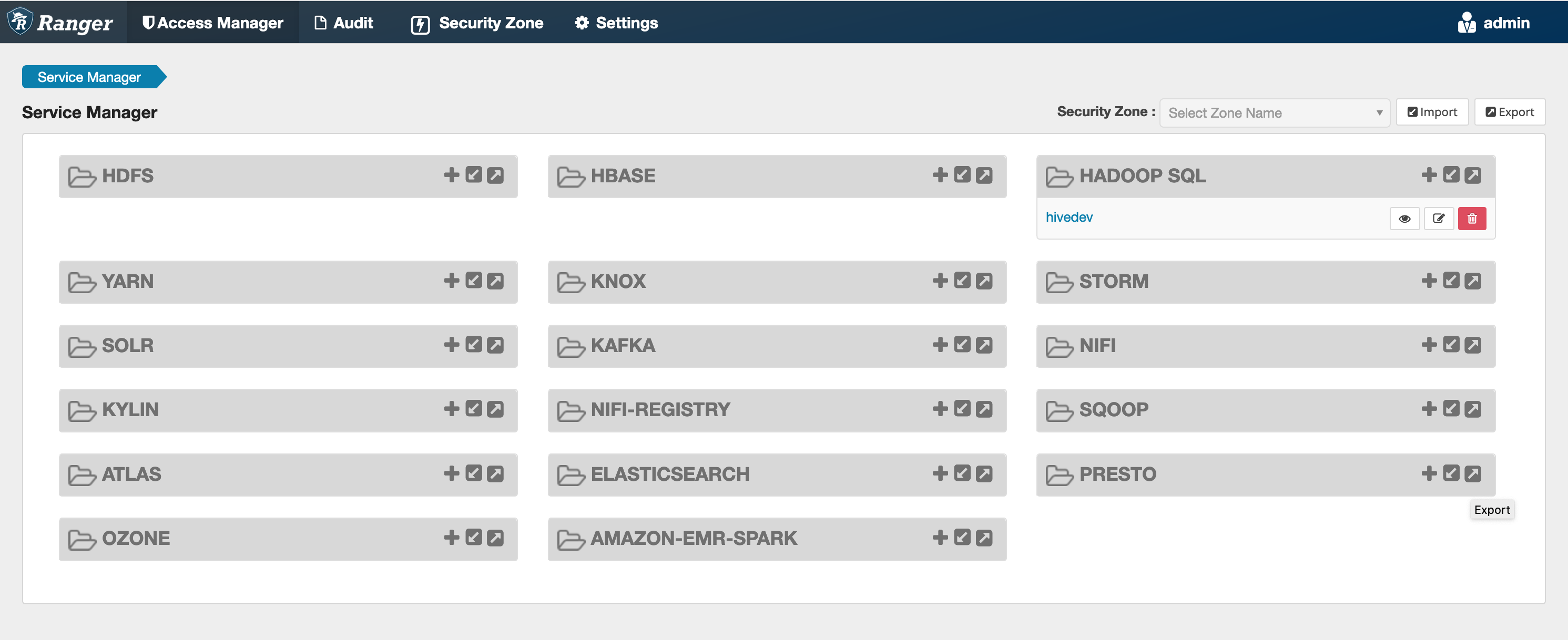
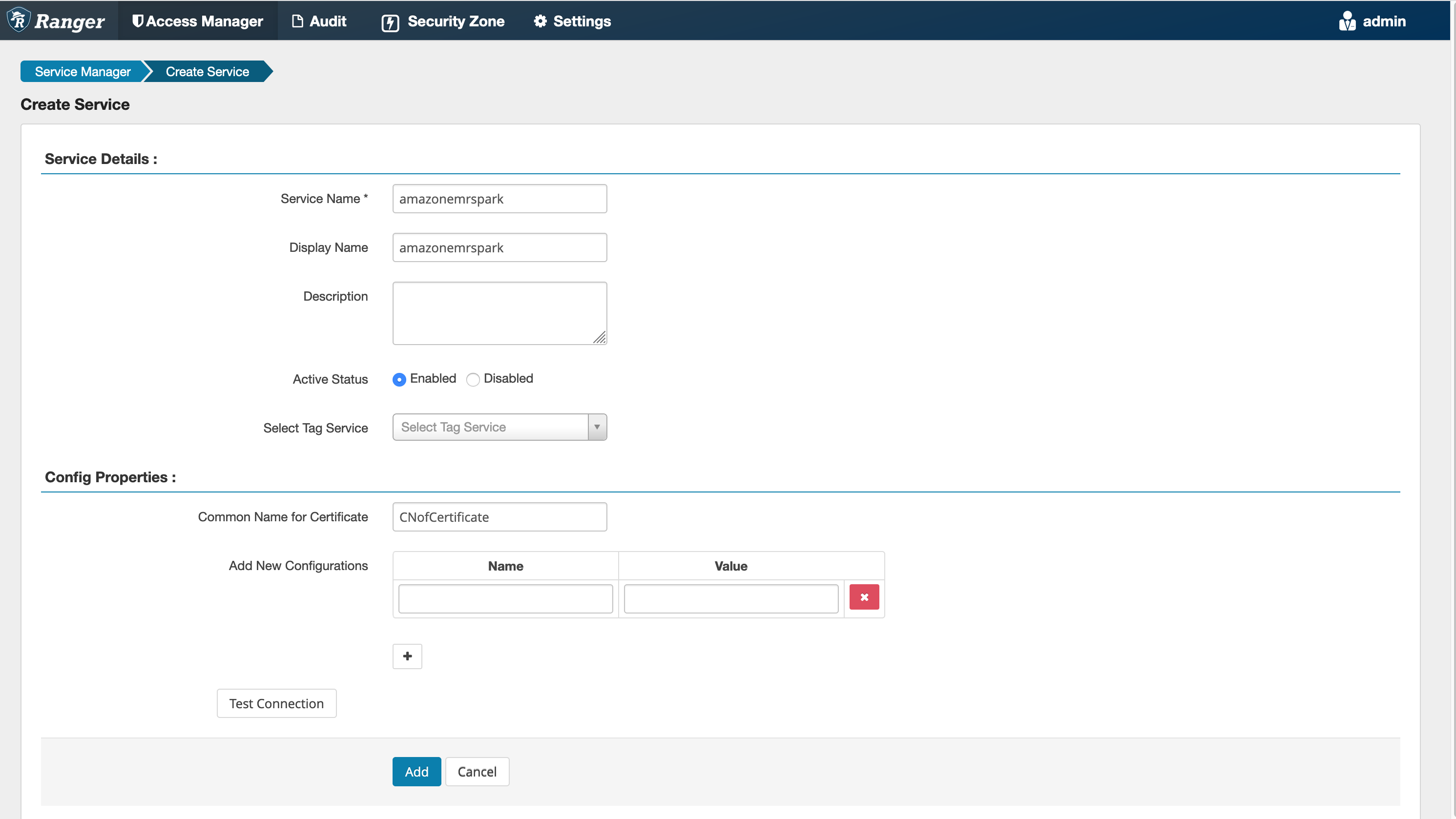
Étape 5 : Création d'une instance de l'SPARKapplication AMAZON EMR -
Nom du service (s'il est affiché) : nom du service qui sera utilisé. La valeur suggérée est amazonemrspark. Notez ce nom de service car il sera nécessaire lors de la création d'une configuration EMR de sécurité.
Nom d'affichage : nom à afficher pour cette instance. La valeur suggérée est amazonemrspark.
Nom commun du certificat : champ CN du certificat utilisé pour se connecter au serveur d'administration à partir d'un plug-in client. Cette valeur doit correspondre au champ CN de votre TLS certificat créé pour le plugin.
Note
Le TLS certificat de ce plugin doit avoir été enregistré dans le trust store du serveur d'administration Ranger. Pour plus d’informations, consultez TLScertificats.
Création de SQL politiques Spark
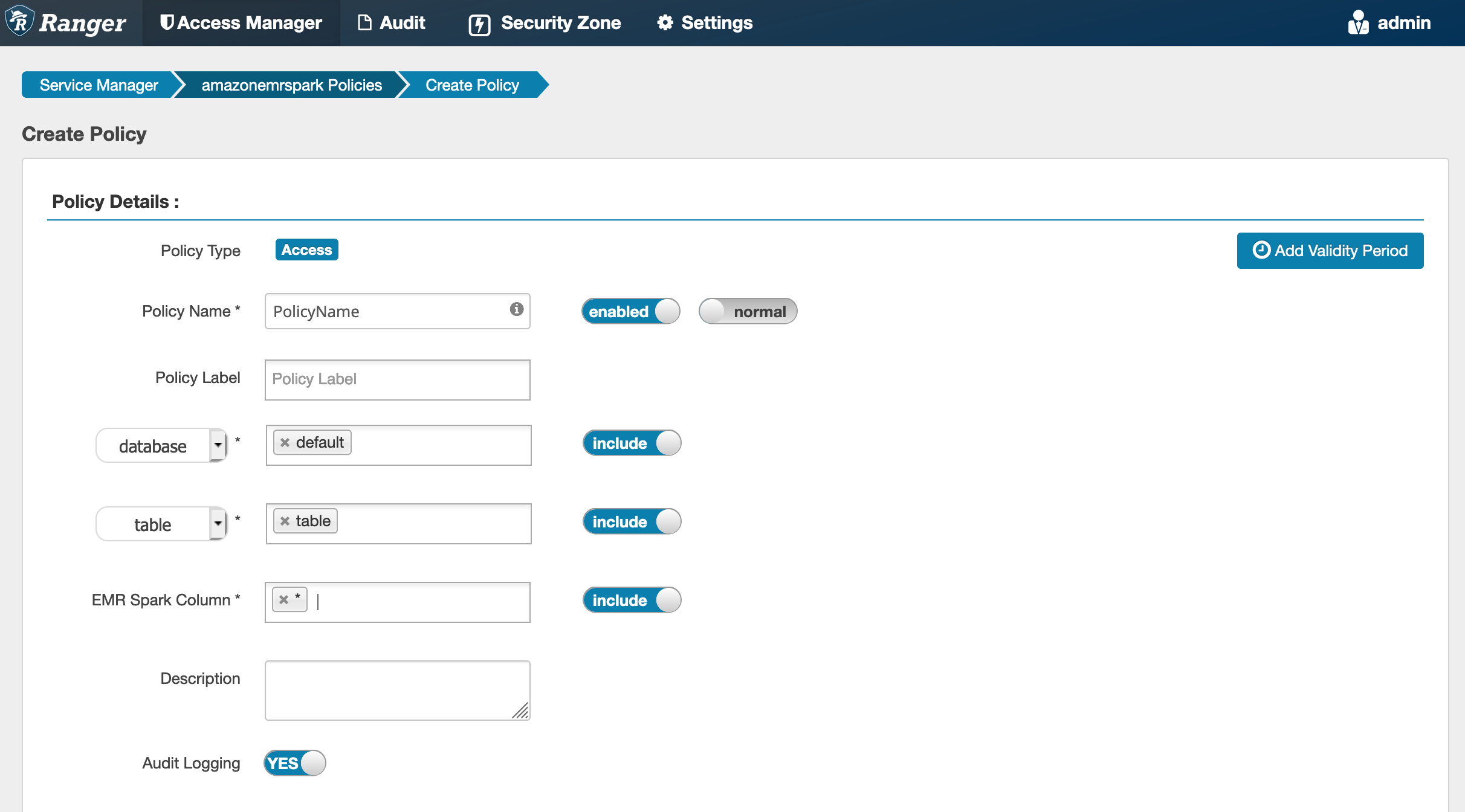
Lors de la création d'une nouvelle politique, les champs à remplir sont les suivants :
Nom de politique : le nom de cette politique.
Étiquette de politique : une étiquette que vous pouvez attribuer à cette politique.
Base de données : base de données à laquelle cette politique s'applique. Le caractère générique « * » représente toutes les bases de données.
Table : les tables auxquelles cette politique s'applique. Le caractère générique "*" représente toutes les tables.
EMRColonne Spark : colonnes auxquelles s'applique cette politique. Le caractère générique "*" représente toutes les colonnes.
Description : description de cette stratégie.
Pour spécifier les utilisateurs et les groupes, entrez les utilisateurs et les groupes ci-dessous pour accorder des autorisations. Vous pouvez également spécifier des exclusions pour les conditions autoriser et refuser.
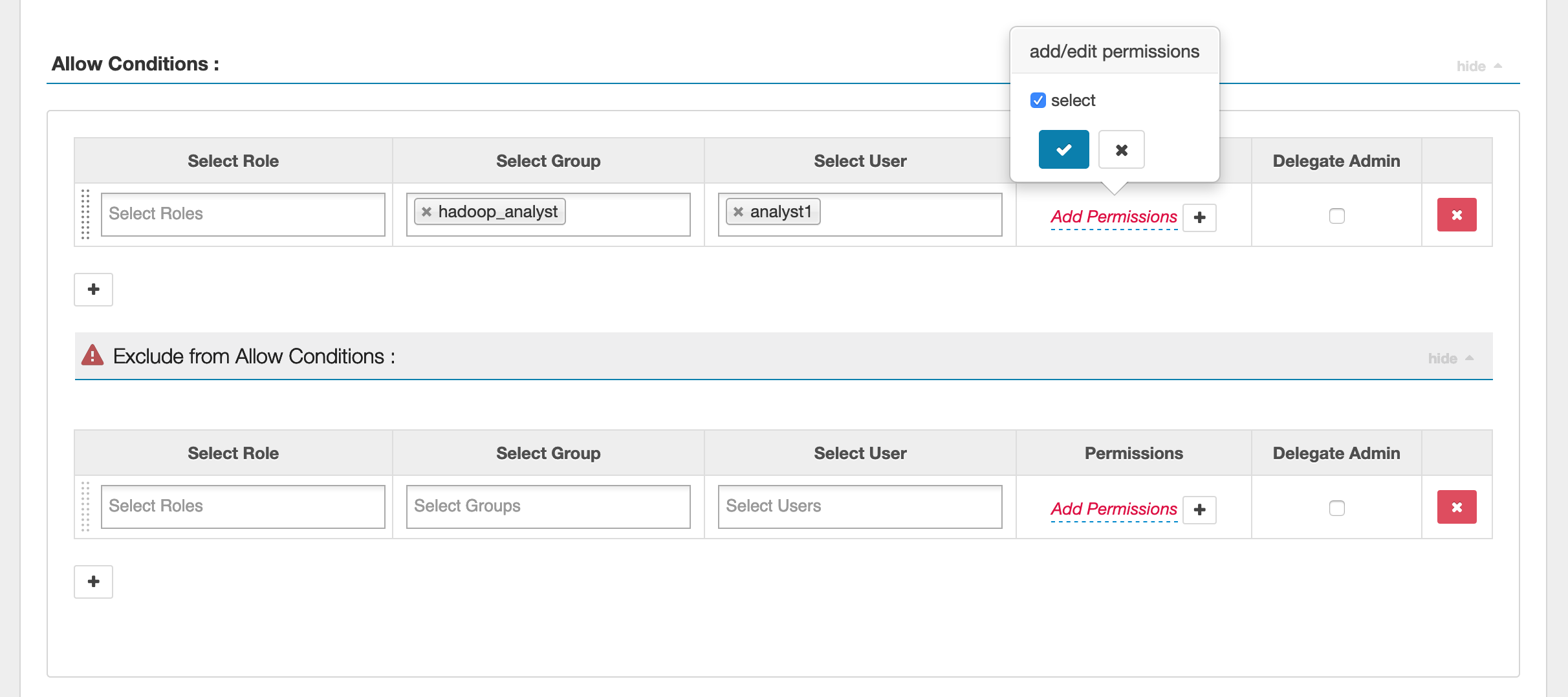
Après avoir spécifié les conditions d'autorisation et de refus, cliquez sur Enregistrer.
Considérations
Chaque nœud du EMR cluster doit pouvoir se connecter au nœud principal sur le port 9083.
Limites
Les limitations actuelles du plug-in Apache Spark sont les suivantes :
-
Le serveur d'enregistrement se connectera toujours à l'HMSexécution sur un EMR cluster Amazon. Configurez HMS pour vous connecter au mode distant, si nécessaire. Vous ne devez pas placer de valeurs de configuration dans le fichier de configuration Hive-site.xml d'Apache Spark.
-
Les tables créées à l'aide de sources de données Spark CSV ou Avro ne sont pas lisibles à l'aide de. EMR RecordServer Utilisez Hive pour créer et écrire des données, et lisez avec Record.
-
Les tables Delta Lake et Hudi ne sont pas prises en charge.
-
Les utilisateurs doivent avoir accès à la base de données par défaut. C'est une exigence pour Apache Spark.
-
Le serveur Ranger Admin ne prend pas en charge l'auto-complétion.
-
Le SQL plugin Spark pour Amazon EMR ne prend pas en charge les filtres de lignes ni le masquage de données.
-
Lors de l'utilisation ALTER TABLE avec SparkSQL, l'emplacement d'une partition doit être le répertoire enfant d'un emplacement de table. L'insertion de données dans une partition dont l'emplacement est différent de celui de la table n'est pas prise en charge.
