Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Outil de mise à l’échelle automatique Flink
Présentation
La version 6.15.0 et les versions ultérieures d’Amazon EMR prennent en charge l’outil de mise à l’échelle automatique Flink. La fonctionnalité de mise à l’échelle automatique des tâches collecte les métriques issues de l’exécution des tâches de streaming Flink et met à l’échelle automatiquement les vertex de chaque tâche. Cela réduit la contre-pression et répond à l’objectif d’utilisation que vous avez défini.
Pour plus d’informations, voir la rubrique Outil de mise à l’échelle automatique
Considérations
-
La version 6.15.0 et les versions ultérieures d’Amazon EMR prennent en charge l’outil de mise à l’échelle automatique Flink.
-
L’outil de mise à l’échelle automatique Flink est pris en charge uniquement pour les tâches de streaming.
-
Seul le planificateur adaptatif est pris en charge. Le planificateur par défaut n’est pas pris en charge.
-
Nous recommandons d’activer la mise à l’échelle de cluster pour permettre une mise à disposition de ressources dynamique. La mise à l’échelle gérée par Amazon EMR est préférable, car l’évaluation des métriques est effectuée toutes les 5 à 10 secondes. À cet intervalle, votre cluster peut s’adapter plus facilement à l’évolution des ressources de cluster requises.
Activation de l’outil de mise à l’échelle automatique
Pour activer l’outil de mise à l’échelle automatique Flink lorsque vous créez un cluster Amazon EMR sur EC2, procédez comme suit.
-
Créez un cluster EMR depuis la console Amazon EMR :
-
Choisissez Amazon EMR version
emr-6.15.0ou ultérieure. Sélectionnez l’offre d’applications Flink, puis toutes les autres applications que vous souhaitez inclure dans votre cluster.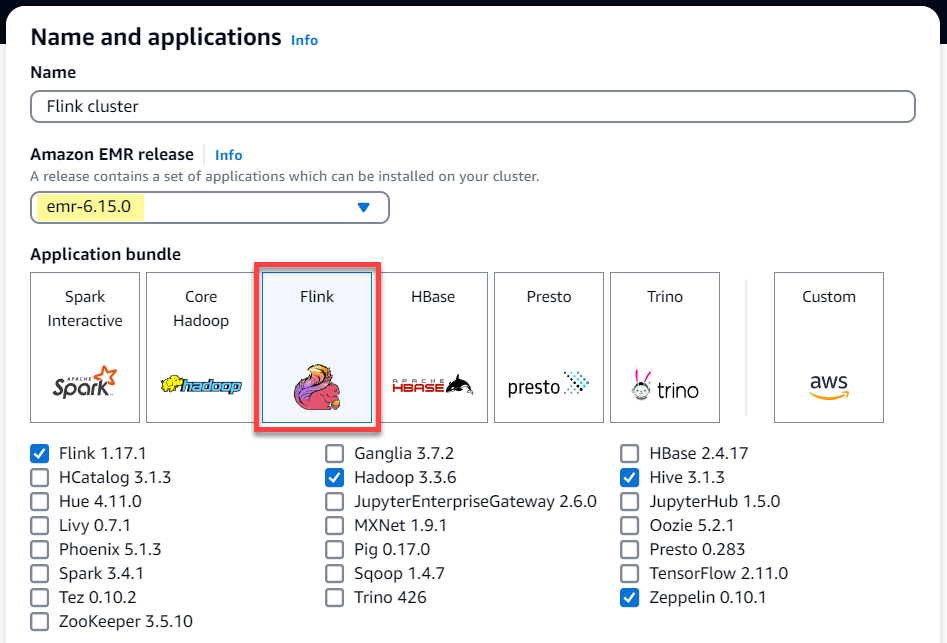
-
Dans Mise à l’échelle et provisionnement du cluster, sélectionnez l’option Utiliser la mise à l’échelle gérée par EMR.

-
-
Dans la section Paramètres du logiciel, entrez la configuration suivante pour activer l’outil de mise à l’échelle automatique Flink. Pour les scénarios de test, définissez l’intervalle de décision, l’intervalle entre les fenêtres de mesures et l’intervalle de stabilisation sur une valeur inférieure afin que la tâche prenne immédiatement une décision de mise à l’échelle et faciliter ainsi la vérification.
[ { "Classification": "flink-conf", "Properties": { "job.autoscaler.enabled": "true", "jobmanager.scheduler": "adaptive", "job.autoscaler.stabilization.interval": "60s", "job.autoscaler.metrics.window": "60s", "job.autoscaler.decision.interval": "10s", "job.autoscaler.debug.logs.interval": "60s" } } ] -
Sélectionnez ou configurez les autres paramètres selon vos préférences, puis créez le cluster compatible avec l’outil de mise à l’échelle automatique Flink.
Configurations de l’outil de mise à l’échelle automatique
Cette section couvre la plupart des configurations que vous pouvez modifier en fonction de vos besoins spécifiques.
Note
Avec des configurations temporelles telles que les paramètres time, interval et window, l’unité par défaut lorsqu’aucune unité n’est spécifiée est la milliseconde. Une valeur de 30 sans suffixe est donc égale à 30 millisecondes. Pour les autres unités de temps, incluez le suffixe approprié de s pour les secondes, m pour les minutes ou h pour les heures.
Rubriques
Configurations de boucle de l’outil de mise à l’échelle automatique
L’outil de mise à l’échelle automatique récupère les métriques au niveau des vertex de la tâche pour chaque intervalle de temps configurable, les convertit en variables d’échelle, estime le parallélisme des nouveaux vertex de la tâche et le recommande au planificateur de tâches. Les métriques ne sont collectées qu’à l’issue du redémarrage de la tâche et de l’intervalle de stabilisation du cluster.
| Clé de configuration | Valeur par défaut | Description | Exemples de valeur |
|---|---|---|---|
job.autoscaler.enabled |
false |
Activez la mise à l’échelle automatique sur votre cluster Flink. | true, false |
job.autoscaler.decision.interval |
60s |
Intervalle de décision de l’outil de mise à l’échelle automatique. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
job.autoscaler.restart.time |
3m |
Temps de redémarrage prévu à utiliser jusqu’à ce que l’opérateur puisse le déterminer de manière fiable à partir de l’historique. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
job.autoscaler.stabilization.interval |
300s |
Période de stabilisation au cours de laquelle aucune nouvelle mise à l’échelle ne sera exécutée. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
job.autoscaler.debug.logs.interval |
300s |
Intervalle entre les journaux de débogage de l’outil de mise à l’échelle automatique. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
Agrégation des métriques et configurations de l’historique
L’outil de mise à l’échelle automatique récupère les métriques et les agrège sur une fenêtre temporelle coulissante. Les métriques sont alors évaluées dans le cadre de décisions de mise à l’échelle. L’historique des décisions de mise à l’échelle pour chaque vertex de tâche est utilisé pour estimer le nouveau parallélisme. Les métriques présentent une date d’expiration basée sur l’ancienneté et une taille d’historique (1 au minimum).
| Clé de configuration | Valeur par défaut | Description | Exemples de valeur |
|---|---|---|---|
job.autoscaler.metrics.window |
600s |
Scaling metrics aggregation window size. |
30 (l’unité par défaut est la milliseconde), 5m, 1h |
job.autoscaler.history.max.count |
3 |
Nombre maximal de décisions de mise à l’échelle passées à conserver par vertex. | 1 sur Integer.MAX_VALUE |
job.autoscaler.history.max.age |
24h |
Nombre minimal de décisions de mise à l’échelle passées à conserver par vertex. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
Configurations au niveau des vertex de tâche
Le parallélisme de chaque vertex de tâche est modifié en fonction de l’utilisation de la cible et est limité par les limites minimale et maximale de parallélisme. Nous vous déconseillons de définir une cible d’utilisation proche de 100 % (c’est-à-dire une valeur de 1). La limite d’utilisation joue le rôle de tampon pour gérer les fluctuations de charge intermédiaires.
| Clé de configuration | Valeur par défaut | Description | Exemples de valeur |
|---|---|---|---|
job.autoscaler.target.utilization |
0.7 |
Utilisation des vertex cibles. | 0 - 1 |
job.autoscaler.target.utilization.boundary |
0.4 |
Limite d’utilisation des vertex cibles. La mise à l’échelle ne sera pas effectuée si le taux de traitement actuel est compris entre [target_rate /
(target_utilization - boundary) et (target_rate /
(target_utilization + boundary)]. |
0 - 1 |
job.autoscaler.vertex.min-parallelism |
1 |
Parallélisme minimal que l’outil de mise à l’échelle automatique peut utiliser. | 0 - 200 |
job.autoscaler.vertex.max-parallelism |
200 |
Parallélisme maximal que l’outil de mise à l’échelle automatique peut utiliser. Notez que l’outil de mise à l’échelle automatique ignore cette limite si elle est supérieure au parallélisme maximal configuré dans la configuration Flink ou directement sur chaque opérateur. | 0 - 200 |
Configurations de traitement du backlog
Le vertex de la tâche requiert des ressources supplémentaires pour gérer les événements en attente, ou backlogs, qui s’accumulent pendant le délai de mise à l’échelle. C’est ce que l’on appelle également la durée de catch-up. Si le délai de traitement du backlog dépasse la lag -threshold valeur configurée, l’utilisation cible du vertex de la tâche augmente jusqu’au niveau maximum. Cela permet d’éviter les opérations de mise à l’échelle inutiles pendant le traitement du backlog.
| Clé de configuration | Valeur par défaut | Description | Exemples de valeur |
|---|---|---|---|
job.autoscaler.backlog-processing.lag-threshold |
5m |
Seuil de retard qui évitera les mises à l’échelle inutiles tout en supprimant les messages en attente responsables du retard. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
job.autoscaler.catch-up.duration |
15m |
Durée cible pour le traitement complet de tout backlog après une opération de mise à l’échelle. Définissez cette valeur sur 0 pour désactiver la mise à l’échelle basée sur le backlog. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
Configurations des opérations de mise à l’échelle
Aucune opération de réduction n’est effectuée par l’outil de mise à l’échelle automatique immédiatement après une opération de mise à l’échelle pendant le délai de grâce. Cela permet d’éviter tout cycle inutile d’opérations successives d’augmentation ou de réduction d’échelle provoquées par des fluctuations de charge temporaires.
Nous pouvons utiliser le ratio de réduction d’échelle pour réduire progressivement le parallélisme et libérer des ressources pour faire face à des pics de charge temporaires. Cela permet également d’éviter des opérations d’augmentation d’échelle mineures et inutiles après une opération de réduction majeure.
Nous pouvons détecter une opération de mise à l’échelle inefficace sur la base de l’historique des décisions d’augmentation d’échelle des vertex de tâches passées afin d’empêcher toute nouvelle modification du parallélisme.
| Clé de configuration | Valeur par défaut | Description | Exemples de valeur |
|---|---|---|---|
job.autoscaler.scale-up.grace-period |
1h |
Durée pendant laquelle aucune réduction d’échelle d’un vertex n’est autorisée après l’augmentation d’échelle de ce vertex. | 30 (l’unité par défaut est la milliseconde), 5m, 1h |
job.autoscaler.scale-down.max-factor |
0.6 |
Facteur maximal de réduction d’échelle. Une valeur égale à 1 signifie qu’aucune limite de réduction d’échelle n’est définie ; 0.6 indique que seule une réduction d’échelle de 60 % du parallélisme d’origine peut être appliquée à la tâche. |
0 - 1 |
job.autoscaler.scale-up.max-factor |
100000. |
Ratio maximal d’augmentation d’échelle. Une valeur de 2.0 signifie que seule une augmentation d’échelle de 200 % du parallélisme actuel peut être appliquée à la tâche. |
0 - Integer.MAX_VALUE |
job.autoscaler.scaling.effectiveness.detection.enabled |
false |
Permet d’activer la détection des opérations de mise à l’échelle inefficaces et d’autoriser le blocage de nouvelles mises à l’échelle par l’outil de mise à l’échelle automatique. | true, false |
