Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration de Flink dans Amazon EMR
Configuration de Flink avec Hive Metastore et Glue Catalog
Les versions 6.9.0 et supérieures d'Amazon EMR prennent en charge à la fois Hive Metastore et AWS Glue Catalog avec le connecteur Apache Flink vers Hive. Cette section décrit les étapes nécessaires pour configurer AWS Glue Catalog et Hive Metastore avec Flink.
Utilisation de Hive Metastore
-
Créez un cluster EMR avec la version 6.9.0 ou supérieure et au moins deux applications : Hive et Flink.
-
Utilisez script runner pour exécuter le script suivant en tant que fonction d'étape :
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar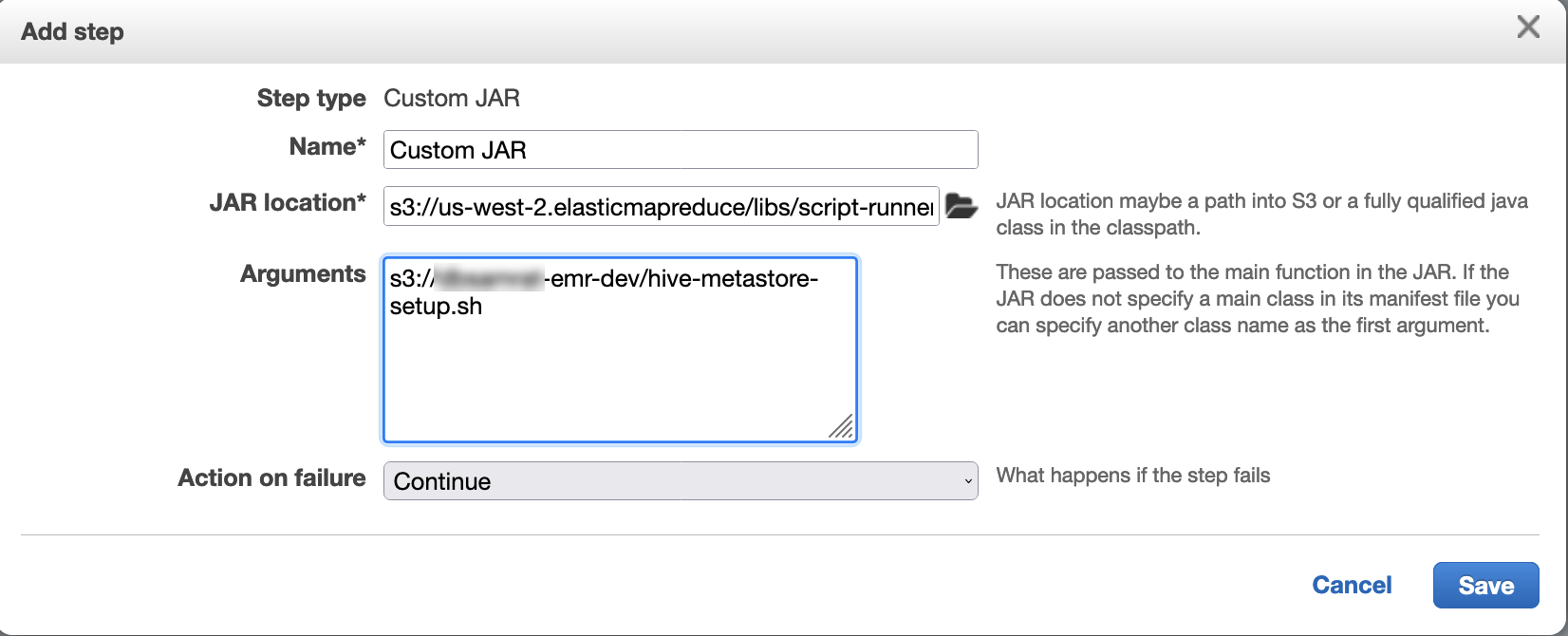
Utiliser le catalogue AWS de données Glue
-
Créez un cluster EMR avec la version 6.9.0 ou supérieure et au moins deux applications : Hive et Flink.
-
Sélectionnez Utiliser les métadonnées de la table Hive dans les paramètres du catalogue de données AWS Glue pour activer le catalogue de données dans le cluster.
-
Utilisez le script runner pour exécuter le script suivant en tant que fonction d'étape : Exécuter des commandes et des scripts sur un cluster Amazon EMR :
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
Configurer Flink avec un fichier de configuration
Vous pouvez utiliser l'API de configuration Amazon EMR pour configurer Flink à l'aide d'un fichier de configuration. Les fichiers configurables dans l'API sont les suivants :
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
Le fichier de configuration principal de Flink est flink-conf.yaml.
Pour configurer le nombre d'emplacements de tâches utilisés par Flink à partir du fichier AWS CLI
-
Créez un fichier,
configurations.json, contenant les éléments suivants :[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
Créez ensuite un cluster à l'aide de la configuration suivante :
aws emr create-cluster --release-labelemr-7.6.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
Note
Vous pouvez également modifier certaines configurations avec l'API Flink. Pour plus d'informations, consultez Concepts
Avec la version 5.21.0 et ultérieures d'Amazon EMR, vous permet de remplacer les configurations de cluster et de spécifier des classifications de configuration supplémentaires pour chaque groupe d'instances dans un cluster en cours d'exécution. Pour ce faire, utilisez la console Amazon EMR, le AWS Command Line Interface (AWS CLI) ou le AWS SDK. Pour plus d'informations, consultez Fourniture d'une configuration pour un groupe d'instances dans un cluster en cours d'exécution.
Options de parallélisme
En tant que propriétaire de votre application, c'est vous qui savez le mieux quelles ressources attribuer aux tâches dans Flink. Pour les exemples de cette documentation, utilisez le même nombre de tâches que les instances de tâches que vous utilisez pour l'application. Généralement, nous recommandons cela pour le niveau initial de parallélisme, mais vous pouvez également augmenter la granularité de parallélisme à l'aide des emplacements de tâches, qui ne doivent généralement pas dépasser le nombre de cœurs virtuels
Configuration de Flink sur un cluster EMR doté de plusieurs nœuds primaires
Le JobManager de Flink reste disponible pendant le processus de basculement du nœud principal dans un cluster Amazon EMR comportant plusieurs nœuds principaux. À partir d'Amazon EMR 5.28.0, la JobManager haute disponibilité est également activée automatiquement. Aucune configuration manuelle n'est nécessaire.
Avec les versions 5.27.0 ou antérieures d'Amazon EMR, il s' JobManager agit d'un point de défaillance unique. En cas d' JobManager échec, il perd tous les états des tâches et ne reprend pas les tâches en cours d'exécution. Vous pouvez activer la JobManager haute disponibilité en configurant le nombre de tentatives d'application, le point de contrôle et ZooKeeper en activant le stockage d'état pour Flink, comme le montre l'exemple suivant :
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
Vous devez configurer le nombre maximal de tentatives du maître d'application pour YARN et les tentatives d'application pour Flink. Pour plus d'informations, consultez Configuration de la haute disponibilité du cluster YARN
Configuration de la taille du processus de mémoire
Pour les versions d'Amazon EMR qui utilisent Flink 1.11.x, vous devez configurer la taille totale du processus de mémoire pour () et JobManager (jobmanager.memory.process.size) dans. TaskManager taskmanager.memory.process.size flink-conf.yaml Vous pouvez définir ces valeurs soit en configurant le cluster à l'aide de l'API de configuration, soit en décommentant manuellement ces champs via SSH. Flink fournit les valeurs par défaut suivantes.
-
jobmanager.memory.process.size: 1600m -
taskmanager.memory.process.size: 1728m
Pour exclure le métaspace JVM et la surcharge, utilisez la taille de mémoire totale de Flink (taskmanager.memory.flink.size) au lieu de taskmanager.memory.process.size. La valeur par défaut du paramètre taskmanager.memory.process.size est 1280m. Il n'est pas recommandé de définir à la fois taskmanager.memory.process.size et taskmanager.memory.process.size.
Toutes les versions d'Amazon EMR qui utilisent Flink 1.12.0 et versions ultérieures ont les valeurs par défaut répertoriées dans l'ensemble open source pour Flink comme valeurs par défaut sur Amazon EMR. Vous n'avez donc pas besoin de les configurer vous-même.
Configuration de la taille du fichier de sortie du journal
Les conteneurs d'applications Flink créent et écrivent dans trois types de fichiers journaux : fichiers .out, fichiers .log et fichiers .err. Seuls .err les fichiers sont compressés et supprimés du système de fichiers, tandis que les fichiers journaux .log et .out restent dans le système de fichiers. Pour garantir la gérabilité de ces fichiers de sortie et la stabilité du cluster, vous pouvez configurer la rotation des journaux dans log4j.properties afin de définir un nombre maximum de fichiers et de limiter leur taille.
Amazon EMR versions 5.30.0 et ultérieures
À partir d'Amazon EMR 5.30.0, Flink utilise le framework de journalisation log4j2 avec le nom de classification de configuration flink-log4j.. L'exemple de configuration suivant illustre le format log4j2.
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon EMR versions 5.29.0 et antérieures
Avec les versions 5.29.0 et antérieures d'Amazon EMR, Flink utilise le framework de journalisation log4j. L'exemple de configuration suivant illustre le format log4j.
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Configurer Flink pour qu'il fonctionne avec Java 11
Les versions 6.12.0 et supérieures d'Amazon EMR fournissent un support d'exécution Java 11 pour Flink. Les sections suivantes décrivent comment configurer le cluster pour fournir un support d'exécution Java 11 pour Flink.
Rubriques
Configurer Flink pour Java 11 lorsque vous créez un cluster
Procédez comme suit pour créer un cluster EMR avec Flink et Java 11 Runtime. Le fichier de configuration dans lequel vous ajoutez la prise en charge de Java 11 est flink-conf.yaml.
Configurer Flink pour Java 11 sur un cluster en cours d'exécution
Procédez comme suit pour mettre à jour un cluster EMR en cours d'exécution avec Flink et Java 11 Runtime. Le fichier de configuration dans lequel vous ajoutez la prise en charge de Java 11 est flink-conf.yaml.
Confirmez le runtime Java pour Flink sur un cluster en cours d'exécution
Pour déterminer l'environnement d'exécution Java d'un cluster en cours d'exécution, connectez-vous au nœud primaire avec SSH, comme décrit dans Connexion au nœud primaire avec SSH. Ensuite, exécutez la commande suivante :
ps -ef | grep flink
La commande ps associée à l'option -ef répertorie tous les processus en cours d'exécution sur le système. Vous pouvez filtrer cette sortie avec grep pour trouver les mentions de la chaîne flink. Vérifiez le résultat pour la valeur de l'environnement d'exécution Java (JRE), jre-XX. Dans le résultat suivant, jre-11 indique que Java 11 est activé lors de l'exécution de Flink.
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
Vous pouvez également vous connecter au nœud primaire avec SSH et démarrer une session Flink YARN avec une commande flink-yarn-session -d. La sortie montre la machine virtuelle Java (JVM) pour Flink, java-11-amazon-corretto dans l'exemple suivant :
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
