Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion de la capacité de stockage
Amazon FSx for NetApp ONTAP fournit un certain nombre de fonctionnalités liées au stockage que vous pouvez utiliser pour gérer la capacité de stockage de votre système de fichiers.
Rubriques
niveaux de stockage FSx pour ONTAP
Les niveaux de stockage sont les supports de stockage physiques d'un système de fichiers Amazon FSx for NetApp ONTAP. FSx for ONTAP propose les niveaux de stockage suivants :
Niveau SSD : stockage sur disque SSD (SSD) hautes performances, fourni par l'utilisateur, spécialement conçu pour la partie active de votre ensemble de données.
Niveau du pool de capacité : stockage entièrement élastique qui s'adapte automatiquement à une taille de plusieurs pétaoctets et est optimisé en termes de coûts pour vos données rarement consultées.
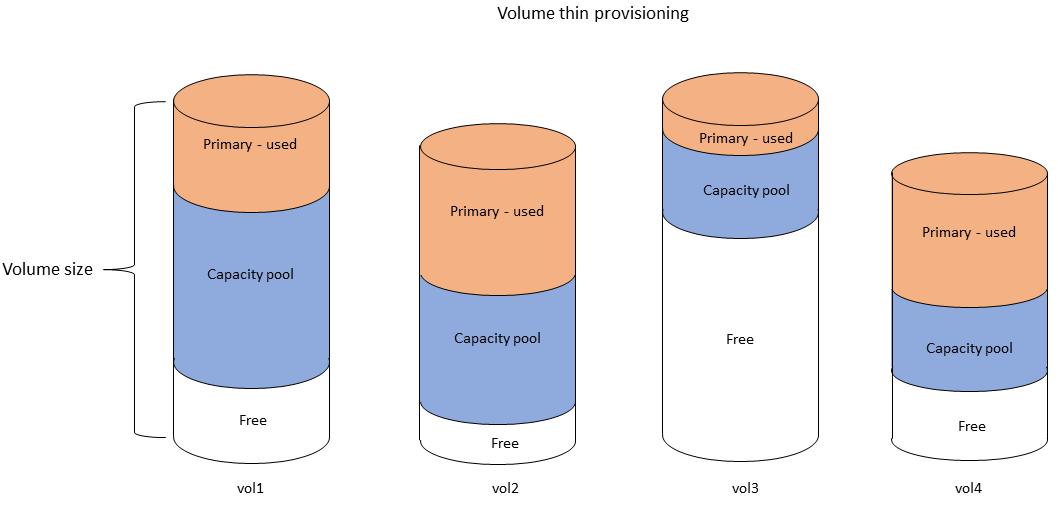
Un volume FSx for ONTAP est une ressource virtuelle qui, comme les dossiers, ne consomme pas de capacité de stockage. Les données que vous stockez, et qui consomment de l'espace de stockage physique, se trouvent dans des volumes. Lorsque vous créez un volume, vous spécifiez sa taille, que vous pouvez modifier après sa création. Les volumes FSx for ONTAP sont dotés d'un provisionnement léger et le stockage du système de fichiers n'est pas réservé à l'avance. Au lieu de cela, le stockage SSD et le stockage en pool de capacité sont alloués dynamiquement, selon les besoins. Une politique de hiérarchisation, que vous configurez au niveau du volume, détermine si et quand les données stockées dans le niveau SSD passent au niveau du pool de capacités.
Le schéma suivant illustre un exemple de données réparties sur plusieurs volumes FSx pour ONTAP dans un système de fichiers.
Le schéma suivant montre comment la capacité de stockage physique du système de fichiers est consommée par les données des quatre volumes du schéma précédent.
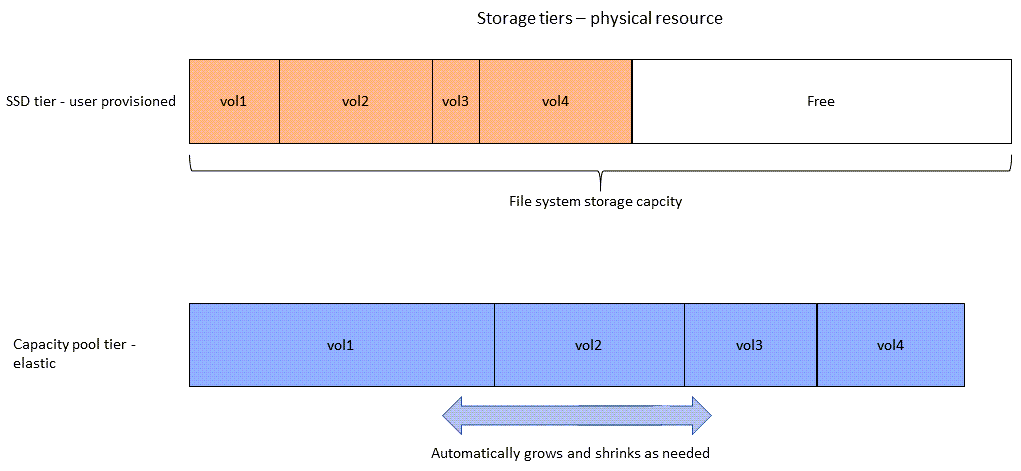
Vous pouvez réduire vos coûts de stockage en choisissant la politique de hiérarchisation qui répond le mieux aux exigences de chaque volume de votre système de fichiers. Pour de plus amples informations, veuillez consulter Hiérarchisation des données de volume.
Choisir la bonne quantité de stockage SSD pour le système de fichiers
Lorsque vous choisissez la capacité de stockage SSD pour votre système de fichiers FSx for ONTAP, vous devez garder à l'esprit les éléments suivants qui ont un impact sur la quantité de stockage SSD disponible pour le stockage de vos données :
Capacité de stockage réservée à la surcharge logicielle NetApp ONTAP.
Métadonnées des fichiers
Données récemment écrites
Les fichiers que vous avez l'intention de stocker sur un disque SSD, qu'il s'agisse de données n'ayant pas atteint la période de refroidissement ou de données que vous avez récemment lues et qui ont été récupérées sur le SSD.
Comment est utilisé le stockage SSD
Le stockage SSD de votre système de fichiers est utilisé à la NetApp fois pour le logiciel ONTAP (surcharge), les métadonnées des fichiers et vos données.
NetApp Frais généraux liés au logiciel ONTAP
À l'instar des autres systèmes de fichiers NetApp ONTAP, jusqu'à 16 % de la capacité de stockage SSD d'un système de fichiers est réservée aux frais généraux d'ONTAP, ce qui signifie qu'il n'est pas disponible pour le stockage de vos fichiers. Les frais généraux de l'ONTAP sont répartis comme suit :
11 % sont réservés au logiciel NetApp ONTAP. Pour les systèmes de fichiers dont la capacité de stockage SSD est supérieure à 30 tebioctets (TiB), 6 % sont réservés.
5 % sont réservés aux instantanés agrégés, qui sont nécessaires pour synchroniser les données entre les deux serveurs de fichiers d'un système de fichiers.
Métadonnées des fichiers
Les métadonnées des fichiers consomment généralement 3 à 7 % de la capacité de stockage utilisée par les fichiers. Ce pourcentage dépend de la taille moyenne des fichiers (une taille moyenne de fichier inférieure nécessite davantage de métadonnées) et des économies d'efficacité du stockage réalisées sur vos fichiers. Notez que les métadonnées des fichiers ne bénéficient pas des économies d'efficacité du stockage. Vous pouvez utiliser les directives suivantes pour estimer la quantité de stockage SSD utilisée pour les métadonnées sur votre système de fichiers.
| Taille de fichier moyenne | Taille des métadonnées en pourcentage des données du fichier |
|---|---|
|
4 Ko |
7 % |
|
8 Ko |
3,5 % |
|
32 Ko ou plus |
1 à 3 % |
Lorsque vous évaluez la capacité de stockage SSD dont vous avez besoin pour les métadonnées des fichiers que vous prévoyez de stocker au niveau du pool de capacité, nous vous recommandons d'utiliser un ratio prudent de 1 Go de stockage SSD pour 10 Go de données que vous prévoyez de stocker au niveau du pool de capacité.
Données de fichiers stockées sur votre niveau SSD
Outre votre ensemble de données actif et toutes les métadonnées des fichiers, toutes les données écrites dans votre système de fichiers sont initialement écrites sur le niveau SSD avant d'être transférées vers le stockage en pool de capacité. Cela est vrai quelle que soit la politique de hiérarchisation du volume, à l'exception du fait que les données sont écrites directement sur le stockage du pool de capacité lorsqu'elles sont utilisées SnapMirror sur un volume configuré avec une politique de hiérarchisation de toutes les données.
Les lectures aléatoires provenant du niveau du pool de capacités sont mises en cache dans le niveau SSD, tant que le niveau SSD est inférieur à 90 % d'utilisation. Pour de plus amples informations, veuillez consulter Hiérarchisation des données de volume.
Utilisation recommandée de la capacité SSD
Nous vous recommandons de ne pas dépasser 80 % d'utilisation du niveau de stockage de votre SSD sur une base continue. Pour les systèmes de fichiers de deuxième génération, nous vous recommandons également de ne pas dépasser 80 % d'utilisation continue des agrégats de votre système de fichiers. Ces recommandations sont conformes à NetApp la recommandation concernant l'ONTAP. Étant donné que le niveau SSD de votre système de fichiers est également utilisé pour effectuer des écritures et des lectures aléatoires depuis le niveau du pool de capacité, toute modification soudaine des modèles d'accès peut rapidement entraîner une augmentation de l'utilisation de votre niveau SSD.
À 90 % d'utilisation du SSD, les données lues depuis le niveau du pool de capacités ne sont plus mises en cache sur le niveau SSD, de sorte que la capacité restante du SSD est préservée pour toute nouvelle donnée écrite dans le système de fichiers. Cela entraîne la lecture répétée des mêmes données depuis le niveau du pool de capacité à être lues depuis le stockage du pool de capacité au lieu d'être mises en cache et lues depuis le niveau SSD, ce qui peut avoir un impact sur la capacité de débit de votre système de fichiers.
Toutes les fonctionnalités de hiérarchisation s'arrêtent lorsque le niveau du SSD atteint ou dépasse 98 % d'utilisation. Pour de plus amples informations, veuillez consulter Seuils de hiérarchisation.
Efficacité du stockage
NetApp ONTAPpropose des fonctionnalités d'efficacité du stockage au niveau des blocs au niveau du volume, notamment la compression, le compactage et la déduplication. Ces fonctionnalités peuvent vous faire économiser jusqu'à 65 % de capacité de stockage pour les partages de fichiers généraux, sans pour autant sacrifier les performances. Vous pouvez activer l'efficacité du stockage par volume. Ces fonctionnalités réduisent la quantité de capacité de stockage consommée par vos données, ce qui vous permet de consommer moins d'espace de stockage sur les SSD, le pool de capacité et le stockage des sauvegardes. Vous pouvez activer la compression et la déduplication sur chaque volume pour les données stockées sur SSD. Les économies de stockage résultant de la compression et de la déduplication sur le stockage SSD sont préservées lorsque les données sont hiérarchisées en fonction de la capacité de stockage du pool. L'efficacité du stockage est toujours activée pour les données de sauvegarde, quelle que soit la configuration d'efficacité du stockage de votre système de fichiers.
Le tableau suivant présente des exemples d'économies de stockage typiques.
| Compression uniquement | Déduplication uniquement | Compression et déduplication | |
|---|---|---|---|
| General-purpose partages de fichiers | 50% | 30 % | 65 % |
| Serveurs et bureaux virtuels | 55 % | 70 % | 70 % |
| Bases de données | 65 à 70 % | 0 % | 65 à 70 % |
| Données d'ingénierie | 55 % | 30 % | 75% |
| Données géosismiques | 40 % | 3 % | 40 % |
Pour la plupart des charges de travail, l'activation de la compression et de la déduplication n'aura pas d'impact négatif sur les performances du système de fichiers. Pour la plupart des charges de travail, la compression améliore les performances globales. Pour permettre des lectures et des écritures rapides à partir du cache RAM, les serveurs de fichiers FSx for ONTAP sont dotés de niveaux de bande passante réseau supérieurs à ceux disponibles entre les serveurs de fichiers et les disques de stockage sur les cartes d'interface réseau (NIC) frontales. Étant donné que la compression des données réduit la quantité de données envoyées entre les serveurs de fichiers et les disques de stockage, pour la plupart des charges de travail, vous constaterez une augmentation de la capacité de débit globale du système de fichiers lors de l'utilisation de la compression de données. Les augmentations de capacité de débit liées à la compression des données seront plafonnées une fois que vous aurez saturé la carte réseau frontale de votre système de fichiers.
Amazon FSx for NetApp ONTAP prend également en charge d'autres ONTAP fonctionnalités qui vous permettent d'économiser de l'espace, notamment les instantanés, le provisionnement dynamique et les volumes. FlexClone
Les fonctionnalités d'efficacité du stockage ne sont pas activées par défaut. Vous pouvez les activer comme suit :
Sur le volume racine d'une SVM lorsque vous créez un système de fichiers.
Lorsque vous créez un nouveau volume.
Lorsque vous modifiez un volume existant.
Pour connaître le montant des économies de stockage réalisées sur un système de fichiers sur lequel l'efficacité du stockage est activée, voirSurveillance des économies d'efficacité du stockage.
Calcul des économies d'efficacité du stockage
Vous pouvez utiliser les métriques du système de CloudWatch fichiers LogicalDataStored et StorageUsed FSx for ONTAP pour calculer les économies de stockage réalisées grâce à la compression, à la déduplication, au compactage, aux instantanés et. FlexClones Ces métriques ont une seule dimension,FileSystemId. Pour de plus amples informations, veuillez consulter Métriques du système de fichiers.
Pour calculer les économies d'efficacité du stockage en octets, prenez la moyenne
StorageUsedsur une période donnée et soustrayez-la de la moyenneLogicalDataStoredsur la même période.Pour calculer les économies d'efficacité du stockage en pourcentage de la taille logique totale des données, prenez le chiffre
AveragedeStorageUsedsur une période donnée et soustrayez-le du chiffre deLogicalDataStoredsur laAveragemême période. Divisez ensuite la différence par leAveragedeLogicalDataStoredsur la même période.
Exemple de dimensionnement d'un SSD
Supposons que vous souhaitiez stocker 100 TiB de données pour une application où 80 % des données sont rarement consultées. Dans ce scénario, 80 % (80 TiB) de vos données sont automatiquement hiérarchisées selon le niveau du pool de capacité et les 20 % restants (20 TiB) restent sur un stockage SSD. Sur la base des économies d'efficacité du stockage typiques de 65 % pour les charges de travail de partage de fichiers à usage général, cela équivaut à 7 TiB de données. Pour maintenir un taux d'utilisation des SSD de 80 %, vous avez besoin de 8,75 TiB de capacité de stockage SSD pour les 20 TiB de données activement consultées. La quantité de stockage SSD que vous fournissez doit également tenir compte de la surcharge de stockage du logiciel ONTAP de 16 %, comme indiqué dans le calcul suivant.
ssdNeeded = ssdProvisioned * (1 - 0.16) 8.75 TiB / 0.84 = ssdProvisioned 10.42 TiB = ssdProvisioned
Dans cet exemple, vous devez donc provisionner au moins 10,42 TiB de stockage SSD. Vous utiliserez également 28 TiB de capacité de stockage en pool pour les 80 TiB restants de données rarement consultées.
