Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connexions Redshift
Vous pouvez utiliser AWS Glue for Spark pour lire et écrire dans les tables des bases de données Amazon Redshift. Lors de la connexion aux bases de données Amazon Redshift, AWS Glue déplace les données via Amazon S3 pour atteindre un débit maximal, à l'aide d'Amazon Redshift et des commandes. SQL COPY UNLOAD Dans AWS Glue 4.0 et versions ultérieures, vous pouvez utiliser l'intégration Amazon Redshift pour Apache Spark pour lire et écrire avec des optimisations et des fonctionnalités spécifiques à Amazon Redshift, au-delà de celles disponibles lors de la connexion via les versions précédentes.
Découvrez comment AWS Glue facilite plus que jamais la migration des utilisateurs d'Amazon Redshift vers AWS Glue pour l'intégration des données sans serveur et. ETL
Configuration des connexions Redshift
Pour utiliser les clusters Amazon Redshift dans AWS Glue, vous aurez besoin de certaines conditions préalables :
-
Un répertoire Amazon S3 à utiliser pour le stockage temporaire lors de la lecture et de l'écriture dans la base de données.
-
Un Amazon VPC permettant la communication entre votre cluster Amazon Redshift, votre job AWS Glue et votre répertoire Amazon S3.
-
IAMAutorisations appropriées pour le job AWS Glue et le cluster Amazon Redshift.
Configuration des IAM rôles
Configurer le rôle pour le cluster Amazon Redshift
Votre cluster Amazon Redshift doit être capable de lire et d'écrire sur Amazon S3 afin de pouvoir s'intégrer aux tâches AWS Glue. Pour ce faire, vous pouvez associer IAM des rôles au cluster Amazon Redshift auquel vous souhaitez vous connecter. Votre rôle doit disposer d'une politique autorisant la lecture et l'écriture dans votre répertoire temporaire Amazon S3. Votre rôle doit avoir une relation de confiance permettant au service redshift.amazonaws.com de AssumeRole.
Pour associer un IAM rôle à Amazon Redshift
Conditions préalables : un compartiment ou un répertoire Amazon S3 utilisé pour le stockage temporaire de fichiers.
-
Identifiez les autorisations Amazon S3 dont votre cluster Amazon Redshift aura besoin. Lors du transfert de données vers et depuis un cluster Amazon Redshift, AWS Glue Jobs émet des critiques à l'encontre COPY d'UNLOADAmazon Redshift. Si votre tâche modifie un tableau dans Amazon Redshift, AWS Glue publiera également CREATE LIBRARY des déclarations. Pour plus d'informations sur les autorisations Amazon S3 spécifiques requises pour qu'Amazon Redshift exécute ces instructions, consultez la documentation Amazon Redshift : Amazon Redshift : Permissions to access other Resources. AWS
Dans la IAM console, créez une IAM politique avec les autorisations nécessaires. Pour plus d'informations sur la création d'une politique Création IAM de politiques.
Dans la IAM console, créez un rôle et une relation de confiance permettant à Amazon Redshift d'assumer le rôle. Suivez les instructions de la IAM documentation Pour créer un rôle pour un AWS service (console)
Lorsqu'on vous demande de choisir un cas d'utilisation du AWS service, choisissez « Redshift - Personnalisable ».
Lorsque vous êtes invité à joindre une politique, choisissez celle que vous avez définie précédemment.
Note
Pour plus d'informations sur la configuration des rôles pour Amazon Redshift, consultez la section Autoriser Amazon Redshift à accéder à d'autres AWS services en votre nom dans la documentation Amazon Redshift.
Dans la console Amazon Redshift, associez le rôle à votre cluster Amazon Redshift. Suivez les instructions de la documentation Amazon Redshift.
Sélectionnez l'option en surbrillance dans la console Amazon Redshift pour configurer ce paramètre :
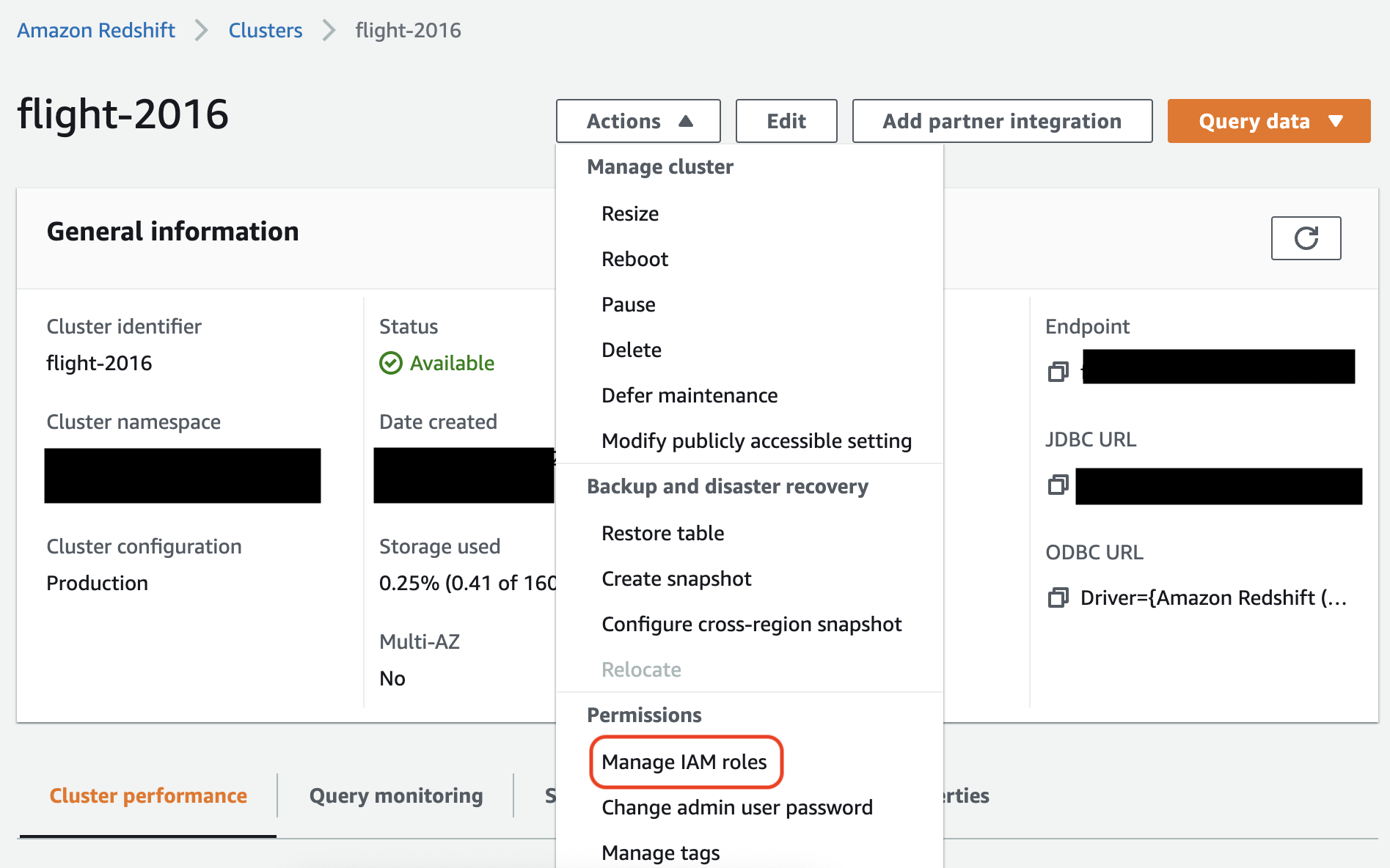
Note
Par défaut, les tâches AWS Glue transmettent les informations d'identification temporaires Amazon Redshift créées à l'aide du rôle que vous avez spécifié pour exécuter la tâche. Nous vous déconseillons d'utiliser ces informations d'identification. Pour des raisons de sécurité, ces informations d'identification expirent au bout d'une heure.
Configuration du rôle pour la tâche AWS Glue
La tâche AWS Glue a besoin d'un rôle pour accéder au compartiment Amazon S3. Vous n'avez pas besoin d'IAMautorisations pour accéder au cluster Amazon Redshift, votre accès est contrôlé par la connectivité d'Amazon VPC et les informations d'identification de votre base de données.
Configurer Amazon VPC
Pour configurer l'accès pour les magasins de données Amazon Redshift
Connectez-vous à la console Amazon Redshift AWS Management Console et ouvrez-la à l'adresse. https://console.aws.amazon.com/redshiftv2/
-
Dans le panneau de navigation de gauche, choisissez Clusters.
-
Choisissez le nom du cluster à partir duquel vous souhaitez accéder AWS Glue.
-
Dans la section Propriétés du cluster, choisissez un groupe de sécurité parmi les groupes VPC de sécurité pour autoriser AWS Glue à utiliser. Enregistrez le nom du groupe de sécurité que vous avez choisi pour référence ultérieure. Le choix du groupe de sécurité ouvre la liste des groupes de sécurité de la EC2 console Amazon.
-
Choisissez le groupe de sécurité à modifier et accédez à l'onglet Inbound (Entrant).
-
Ajoutez une règle d'autoréférencement pour autoriser AWS Glue composants pour communiquer. Plus spécifiquement, ajoutez ou confirmez qu'il existe une règle Type
All TCP, que Protocol (Protocole) estTCP, que Port Range (Plage de ports) comprend tous les ports et que la valeur de Source est le même nom de groupe de sécurité que la valeur de Group ID (ID du groupe).La règle entrante ressemble à ce qui suit :
Type Protocole Plage de ports Source Tous TCP
TCP
0-65535
database-security-group
Par exemple :
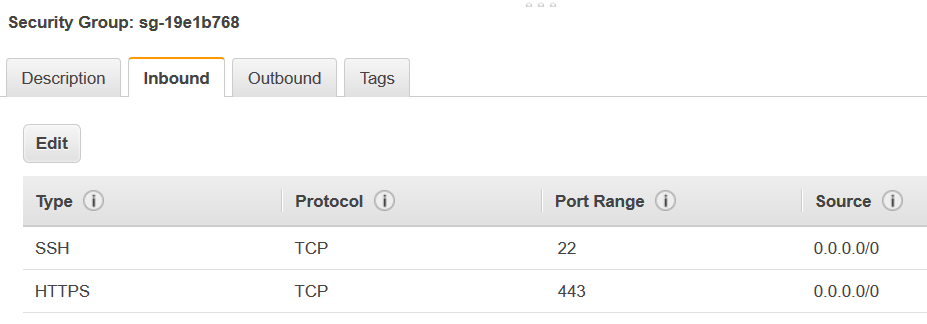
-
Ajoutez également une règle pour le trafic sortant. Ouvrez le trafic sortant pour tous les ports, par exemple :
Type Protocole Plage de ports Destination Tout le trafic
ALL
ALL
0.0.0.0/0
Ou créez une règle avec référence circulaire où Type est
All TCP, Protocol (Protocole) estTCP, Port Range (Plage de ports) comprend tous les ports et dont la valeur de Destination est le même nom de groupe de sécurité que la valeur de Group ID (ID du groupe). Si vous utilisez un point de VPC terminaison Amazon S3, ajoutez également une HTTPS règle pour l'accès à Amazon S3. Les3-prefix-list-idest requis dans la règle du groupe de sécurité pour autoriser le trafic depuis le point de terminaison Amazon S3 VPC vers le point de VPC terminaison Amazon S3.Par exemple :
Type Protocole Plage de ports Destination Tous TCP
TCP
0-65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
Configurer AWS Glue
Vous devez créer une connexion AWS Glue Data Catalog qui fournit les informations de VPC connexion Amazon.
Pour configurer Amazon Redshift, la VPC connectivité Amazon à AWS Glue dans la console
-
Créez une connexion au catalogue de données en suivant les étapes décrites dans :Ajouter une AWS Glue connexion. Après avoir créé la connexion, conservez le nom de la connexion pour l'étape suivante.
connectionNameLorsque vous sélectionnez un type de connexion, sélectionnez Amazon Redshift.
Lorsque vous sélectionnez un cluster Redshift, sélectionnez le nom de votre cluster.
Fournissez les informations de connexion par défaut pour un utilisateur Amazon Redshift sur votre cluster.
Vos VPC paramètres Amazon seront automatiquement configurés.
Note
Vous devrez fournir manuellement votre Amazon VPC lors
PhysicalConnectionRequirementsde la création d'une connexion Amazon Redshift via le. AWS SDK -
Dans la configuration de votre tâche AWS Glue
connectionName, fournissez une connexion réseau supplémentaire.
Exemple : lecture à partir de tables Amazon Redshift
Vous pouvez lire à partir de clusters Amazon Redshift et des environnements Amazon Redshift sans serveur.
Conditions préalables : une table Amazon Redshift à partir de laquelle vous souhaitez lire. Suivez les étapes de la section précédente, Configuration des connexions Redshift après quoi vous devriez avoir l'Amazon S3 URI comme répertoire temporaire, temp-s3-dir et un IAM rôlers-role-name, (dans le compterole-account-id).
Exemple : écrire sur des tables Amazon Redshift
Vous pouvez sur des clusters Amazon Redshift et des environnements Amazon Redshift sans serveur.
Conditions préalables : un cluster Amazon Redshift et suivez les étapes de la Configuration des connexions Redshift section précédente, après quoi vous devriez avoir l'Amazon URI S3 comme répertoire temporaire et IAM un rôletemp-s3-dir,rs-role-name, (dans role-account-id le compte). Vous aurez également besoin d'un DynamicFrame dont vous souhaitez écrire le contenu dans la base de données.
Référence des options de connexion Amazon Redshift
Les options de connexion de base utilisées pour toutes les JDBC connexions AWS Glue permettent de configurer des informations telles queurl, user et password sont cohérentes entre tous les JDBC types. Pour plus d'informations sur JDBC les paramètres standard, consultezJDBCréférence des options de connexion.
Le type de connexion Amazon Redshift propose des options de connexion supplémentaires :
-
"redshiftTmpDir": (obligatoire) chemin Amazon S3 où les données temporaires peuvent être stockées lors de la copie à partir de la base de données. -
"aws_iam_role": (Facultatif) ARN pour un IAM rôle. La tâche AWS Glue transmettra ce rôle au cluster Amazon Redshift pour accorder au cluster les autorisations nécessaires pour exécuter les instructions de la tâche.
Options de connexion supplémentaires disponibles dans AWS Glue 4.0+
Vous pouvez également transmettre les options du nouveau connecteur Amazon Redshift via les options de connexion AWS Glue. Pour obtenir la liste complète des options de connecteur prises en charge, consultez la section sur SQLles paramètres Spark dans Intégration d'Amazon Redshift pour Apache Spark.
Pour vous faciliter la tâche, nous vous rappelons ici certaines nouvelles options :
| Nom | Obligatoire | Par défaut | Description |
|---|---|---|---|
| autopushdown |
Non | TRUE | Applique le transfert des prédicats et des requêtes en capturant et en analysant les plans logiques des opérations de SQL Spark. Les opérations sont traduites en une SQL requête, puis exécutées dans Amazon Redshift pour améliorer les performances. |
| autopushdown.s3_result_cache |
Non | FALSE | Met en cache la SQL requête pour décharger les données pour le mappage des chemins Amazon S3 en mémoire afin que la même requête n'ait pas besoin de s'exécuter à nouveau dans la même session Spark. Pris en charge uniquement lorsqu' |
| unload_s3_format |
Non | PARQUET | PARQUET- Décharge les résultats de la requête au format Parquet. TEXT- Décharge les résultats de la requête au format texte délimité par des tubes. |
| sse_kms_key |
Non | N/A | La KMS clé AWS SSE - à utiliser pour le chiffrement pendant |
| extracopyoptions |
Non | N/A | Une liste d'options supplémentaires à ajouter à la commande Amazon Notez que ces options étant ajoutées à la fin de la commande |
| csvnullstring (expérimental) |
Non | NULL | La valeur de chaîne à écrire pour les valeurs nulles lorsque vous utilisez le CSV |
Ces nouveaux paramètres peuvent être utilisés comme suit.
Nouvelles options destinées à améliorer les performances
Le nouveau connecteur intègre de nouvelles options d'amélioration des performances :
-
autopushdown: activée par défaut. -
autopushdown.s3_result_cache: désactivée par défaut. -
unload_s3_format:PARQUETpar défaut.
Pour plus d'informations sur l'utilisation de ces options, consultez Intégration Amazon Redshift pour Apache Spark. Nous vous recommandons de ne pas activer
autopushdown.s3_result_cache lorsque vous effectuez des opérations mixtes (lecture et écriture), car les résultats mis en cache peuvent contenir des informations périmées. L'option unload_s3_format est définie sur PARQUET par défaut pour la commande UNLOAD, afin d'améliorer les performances et de réduire les coûts de stockage. Pour utiliser le comportement par défaut de la commande UNLOAD, réinitialisez l'option sur TEXT.
Nouvelle option de chiffrement pour la lecture
Par défaut, les données du dossier temporaire qui AWS Glue utilisé lorsqu'il lit les données de la table Amazon Redshift est crypté à l'aide SSE-S3 du chiffrement. Pour utiliser les clés gérées par le client à partir de AWS Key Management Service (AWS KMS) pour chiffrer vos données, vous pouvez configurer l'("sse_kms_key"
→ kmsKey)origine ksmKey de l'identifiant de la clé AWS KMS, au lieu de l'option ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") de configuration traditionnelle dans AWS Glue version 3.0.
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
Basé IAM sur le support JDBC URL
Le nouveau connecteur prend en charge une IAM base JDBCURL, vous n'avez donc pas besoin de transmettre un utilisateur/mot de passe ou un secret. Avec une IAM base JDBCURL, le connecteur utilise le rôle d'exécution des tâches pour accéder à la source de données Amazon Redshift.
Étape 1 : Joignez la politique minimale requise suivante à votre AWS Glue rôle d'exécution de la tâche.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": [ "arn:aws:redshift:<region>:<account>:dbgroup:<cluster name>/*", "arn:aws:redshift:*:<account>:dbuser:*/*", "arn:aws:redshift:<region>:<account>:dbname:<cluster name>/<database name>" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "redshift:DescribeClusters", "Resource": "*" } ] }
Étape 2 : Utilisez la IAM base JDBC URL comme suit. Spécifiez une nouvelle option DbUser avec le nom d'utilisateur Amazon Redshift qui permet de vous connecter.
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
Note
A ne prend DynamicFrame actuellement en charge qu'un IAM basé JDBC URL avec un
DbUser dans le GlueContext.create_dynamic_frame.from_options flux de travail.
Migration à partir de AWS Glue de la version 3.0 à la version 4.0
Dans AWS Glue 4.0, les ETL tâches ont accès à un nouveau connecteur Amazon Redshift Spark et à un nouveau JDBC pilote avec différentes options et configurations. Le nouveau connecteur et le nouveau pilote Amazon Redshift ont été conçus dans un souci de performance et garantissent la cohérence transactionnelle de vos données. Ces produits sont décrits dans la documentation Amazon Redshift. Pour plus d’informations, consultez :
Restriction portant sur les noms et les identifiants des tables et des colonnes
Concernant le nom de la table Redshift, les exigences du nouveau connecteur et du nouveau pilote Amazon Redshift Spark sont plus restreintes. Pour plus d'informations, consultez la section Noms et identifiants qui explique comment définir le nom de votre table Amazon Redshift. Le flux de travail des signets de tâches peut ne pas fonctionner avec un nom de table non conforme aux règles et avec certains caractères (l'espace, par exemple).
Si vous utilisez d'anciennes tables dont les noms ne sont pas conformes aux règles relatives aux noms et identifiants et que vous rencontrez des problèmes liés aux signets (tâches dédiées au retraitement des données d'anciennes tables Amazon Redshift), nous vous recommandons de renommer vos tables. Pour plus d'informations, consultez les ALTERTABLEexemples.
Modification de tempformat par défaut dans le Dataframe
Le AWS Glue version 3.0 Le connecteur Spark définit le tempformat to par défaut CSV lors de l'écriture sur Amazon Redshift. Pour être cohérent, dans AWS Glue version 3.0, la valeur par défaut
DynamicFrame est toujours celle tempformat à utiliserCSV. Si vous avez déjà utilisé Spark Dataframe APIs directement avec le connecteur Amazon Redshift Spark, vous pouvez définir explicitement tempformat le CSV to dans DataframeReader les options/. Writer Sinon, tempformat est défini par défaut sur AVRO dans le nouveau connecteur Spark.
Changement de comportement : associez le type de données Amazon Redshift REAL au type de données Spark au lieu de FLOAT DOUBLE
Entrée AWS Glue version 3.0, Amazon Redshift REAL est converti en un type Spark
DOUBLE. Le nouveau connecteur Amazon Redshift Spark a mis à jour le comportement afin que le type Amazon Redshift
REAL soit converti en type FLOAT de Spark et inversement. Si, conformément à un ancien cas d'utilisation, vous souhaitez toujours que le type REAL Amazon Redshift soit mappé sur un type Spark DOUBLE, vous pouvez utiliser la solution alternative suivante :
-
Pour un
DynamicFrame, mappez le typeFloatsur un typeDoubleavecDynamicFrame.ApplyMapping. Pour unDataframe, vous devez utilisercast.
Exemple de code :
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
