Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Tutoriel : Création d'une transformation de machine learning avec AWS Glue
Ce didacticiel vous guide tout au long des actions de création et de gestion d'une transformation Machine Learning (ML) à l'aide de AWS Glue. Avant d'utiliser ce tutoriel, vous devez être familiarisé avec l'utilisation de la console AWS Glue pour ajouter des crawlers et des tâches et modifier des scripts. Vous devez également être familiarisé avec la recherche et le téléchargement de fichiers sur la console Amazon Simple Storage Service (Amazon S3).
Dans cet exemple, vous allez créer une FindMatches transformation pour rechercher des enregistrements correspondants, l'entraîner à identifier les enregistrements correspondants et les non correspondants, puis l'utiliser dans une tâche AWS Glue. La tâche AWS Glue écrit un nouveau fichier Amazon S3 avec une colonne supplémentaire nommée match_id.
Les données source utilisées par ce tutoriel sont un fichier nommé dblp_acm_records.csv. Ce fichier est une version modifiée de publications universitaires (DBLP et ACM) disponibles à partir de l'ensemble de données DBLP ACM d'originedblp_acm_records.csv fichier est un fichier de valeurs séparées par des virgules (CSV) au UTF-8 format sans marque d'ordre des octets (BOM).
Un second fichier, dblp_acm_labels.csv, est un exemple de fichier d'étiquetage qui contient des enregistrements correspondants et non correspondants utilisés pour entraîner la transformation dans le cadre du didacticiel.
Rubriques
Étape 1 : Analyse des données source
Tout d'abord, analysez le le fichier CSV source Amazon S3 pour créer une table de métadonnées correspondante dans Data Catalog.
Important
Pour indiquer à le crawler de créer une table pour seulement le fichier CSV, stockez les données source CSV dans un autre dossier Amazon S3 à partir d'autres fichiers.
Connectez-vous à la AWS Glue console AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/glue/
. -
Dans le panneau de navigation, sélectionnez Crawlers, Ajouter un crawler.
-
Suivez les instructions de l'assistant pour créer et exécuter un crawler nommé
demo-crawl-dblp-acmavec une sortie dans une base de donnéesdemo-db-dblp-acm. Lorsque vous exécutez l'assistant, créez la base de donnéesdemo-db-dblp-acmsi elle n'existe pas déjà. Choisissez un chemin d'inclusion Amazon S3 vers les échantillons de données dans la AWS région actuelle. Par exemple, pourus-east-1, le chemin d'inclusion Amazon S3 pour le fichier source ests3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.Si l'opération aboutit, le crawler crée la table
dblp_acm_records_csvavec les colonnes suivantes : id, title, authors, venue, year et source.
Étape 2 : Ajouter une transformation de Machine Learning
Ensuite, ajoutez une transformation de Machine Learning basée sur le schéma de votre table source de données créée par le crawler nommé demo-crawl-dblp-acm.
-
Sur la console AWS Glue, dans le volet de navigation sous Intégration des données et ETL, choisissez Outils de classification des données > Correspondance des enregistrements, puis Ajouter une transformation. Suivez les instructions de l'assistant pour créer une transformation
Find matchesavec les propriétés suivantes.-
Pour Transform name (Nom de transformation), entrez
demo-xform-dblp-acm. Il s'agit du nom de la transformation qui est utilisée pour rechercher des correspondances dans les données source. -
Pour IAM role (Rôle IAM), sélectionnez un rôle IAM qui dispose d'une autorisation sur les données source Amazon S3, le fichier d'étiquetage et les opérations d'API AWS Glue. Pour de plus amples informations, veuillez consulter Création d'un rôle IAM pour AWS Glue dans le Guide du développeur AWS Glue .
-
Pour Data source (Source de données), choisissez la table nommée dblp_acm_records_csv dans la base de données demo-db-dblp-acm.
-
Pour Primary key (Clé primaire), choisissez la colonne de clé primaire pour la table, id.
-
Dans l'assistant, choisissez, choisissez Finish (Terminer) et revenez à la liste ML transforms (Transformations ML).
Étape 3 : Entraîner votre transformation Machine Learning
Ensuite, vous entraînez votre transformation Machine Learning à l'aide du fichier d'étiquetage de l'exemple de didacticiel.
Vous ne pouvez pas utiliser une transformation Machine Language dans une tâche d'extraction, de transformation et de chargement (ETL) tant que son statut n'est pas Ready for use (Prêt pour utilisation). Pour que votre transformation soit prête, vous devez l'entraîner à identifier les enregistrements correspondants et non correspondants en fournissant des exemples d'enregistrements correspondants et non correspondants. Pour entraîner votre transformation, vous pouvez Générer un fichier d'étiquettes, ajouter des étiquettes, puis Télécharger le fichier d'étiquettes. Dans ce didacticiel, vous pouvez utiliser l'exemple de fichier d'étiquetage nommé dblp_acm_labels.csv. Pour plus informations sur le processus d'étiquetage, veuillez consulter Étiquetage.
-
Sur la console AWS Glue, dans le volet de navigation, sélectionnez Correspondance des enregistrements.
-
Choisissez la transformation
demo-xform-dblp-acm, puis choisissez Action, Teach (Entraîner). Suivez les instructions de l'assistant pour entraîner votre transformationFind matches. Sur la page des propriétés de transformation, choisissez I have labels (Je dispose d'étiquettes). Choisissez un chemin Amazon S3 vers l'exemple de fichier d'étiquetage dans la AWS région actuelle. Par exemple, pour
us-east-1, chargez le fichier d'étiquetage fourni à partir du chemin Amazon S3s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvavec l'option de remplacement des étiquettes existantes. Le fichier d'étiquetage doit se trouver dans Amazon S3 dans la même région que la console AWS Glue.Lorsque vous chargez un fichier d'étiquetage, une tâche est démarrée dans AWS Glue pour ajouter ou remplacer les étiquettes utilisées pour entraîner la transformation à traiter la source de données.
Sur la dernière page de l'assistant, choisissez Terminer, puis revenez à la liste Transformations Machine Learning.
Étape 4 : Estimer la qualité de votre transformation Machine Learning
Ensuite, vous pouvez estimer la qualité de votre transformation Machine Learning. La qualité dépend de la quantité d'étiquetage que vous avez effectuée. Pour en savoir plus sur l'estimation de la qualité, consulter Estimation de la qualité.
-
Sur la console AWS Glue, dans le volet de navigation sous Intégration des données et ETL, choisissez Outils de classification des données > Correspondance des enregistrements.
-
Choisissez la transformation
demo-xform-dblp-acm, puis choisissez l'onglet Estimate quality (Estimation de la qualité). Cet onglet affiche les estimations de qualité actuelles, le cas échéant, pour la transformation. Choisissez Estimation de la qualité pour démarrer une tâche permettant d'estimer la qualité de la transformation. La précision de l'estimation de la qualité est basée sur l'étiquetage des données source.
Accédez à l'onglet History (Historique). Dans ce panneau, les exécutions de tâche sont répertoriées pour la transformation, y compris la tâche Estimation de la qualité. Pour plus de détails sur l'exécution, choisissez Journaux. Vérifiez que le statut d'exécution est Réussite lorsqu'elle se termine.
Étape 5 : Ajouter et exécuter une tâche avec votre transformation Machine Learning
Au cours de cette étape, vous utilisez votre transformation Machine Learning pour ajouter et exécuter une tâche dans AWS Glue. Lorsque la transformation demo-xform-dblp-acm a le statut Ready for use (Prête pour utilisation), vous pouvez l'utiliser dans une tâche ETL.
-
Sur la console AWS Glue, dans le panneau de navigation, sélectionnez Tâches.
-
Choisissez Ajouter une tâche, et suivez les étapes de l'assistant pour créer une tâche ETL Spark avec un script généré. Choisissez les valeurs de propriété suivantes pour votre transformation :
-
Pour Nom, choisissez l'exemple de tâche dans ce didacticiel, demo-etl-dblp-acm.
-
Pour Rôle IAM, choisissez un rôle IAM qui a une autorisation sur les données source Amazon S3, le fichier d'étiquetage et les opérations d'API AWS Glue. Pour plus informations, veuillez consulter Création d'un rôle IAM pour AWS Glue dans le Guide du développeur AWS Glue .
-
Pour Langage ETL, choisissez Scala. Il s'agit du langage de programmation dans le script ETL.
-
Pour Script file name (Nom du fichier script) , choisissez demo-etl-dblp-acm. Il s'agit du nom de fichier du script Scala (identique au nom de la tâche).
-
Pour Data source (Source de données), choisissez dblp_acm_records_csv. La source de données que vous choisissez doit correspondre au schéma de source de données de la transformation Machine Learning.
-
Pour Type de transformation, choisissez Rechercher des enregistrements correspondants pour créer une tâche à l'aide d'une transformation Machine Learning.
-
Désactivez Enlever les enregistrements en double. Vous ne souhaitez pas retirer les enregistrements en double car les enregistrements de sortie écrits comportent un champ
match_idsupplémentaire ajouté. -
Pour Transformation, choisissez demo-xform-dblp-acm, transformation Machine Learning utilisée par la tâche.
-
Pour Créer des tables dans votre cible de données, choisissez de créer des tables avec les propriétés suivantes :
-
Type de magasin de données —
Amazon S3 -
Format –
CSV -
Type de compression –
None -
Chemin cible : chemin Amazon S3 où est écrite la sortie de la tâche (dans la AWS région de console actuelle)
-
-
-
Choisissez Enregistrer la tâche et modifier le script pour afficher la page de l'éditeur de script.
-
Modifiez le script pour ajouter une instruction qui entraîne l'écriture de la sortie de tâche du chemin d'accès cible dans un seul fichier de partition. Ajoutez cette instruction immédiatement après l'instruction qui exécute la transformation
FindMatches. L'instruction est similaire à ce qui suit.val single_partition = findmatches1.repartition(1)Vous devez modifier l'instruction
.writeDynamicFrame(findmatches1)pour écrire la sortie en tant que.writeDynamicFrame(single_partion). -
Une fois que vous avez modifié le script, cliquez sur Enregistrer. Le script modifié ressemble au code qui suit, mais personnalisé pour votre environnement.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Appuyez sur Exécuter la tâche) pour démarrer l'exécution de la tâche. Vérifiez le statut de la tâche dans la liste des tâches. Une fois la tâche terminée, dans l'onglet Transformation ML, Historique, une nouvelle ligne exécution ID de type Tâche ETL est ajoutée.
Accédez à l'onglet Jobs (Tâches), Historique. Dans ce panneau, les exécutions de tâches sont répertoriées. Pour plus de détails sur l'exécution, choisissez Journaux. Vérifiez que le statut d'exécution est Réussite lorsqu'elle se termine.
Étape 6 : vérifier les données de sortie d'Amazon S3
Au cours de cette étape, vous vérifiez la sortie de la tâche exécutée dans le compartiment Amazon S3 que vous avez choisi lors de l'ajout à la tâche. Vous pouvez télécharger le fichier de sortie sur votre machine locale et vérifier que les enregistrements correspondants ont été identifiés.
Ouvrez la console Amazon S3 à l'adresse https://console.aws.amazon.com/s3/
. Téléchargez le fichier de sortie cible de la tâche
demo-etl-dblp-acm. Ouvrez le fichier dans une application de feuille de calcul (vous devrez peut-être ajouter une extension de fichier.csvpour que le fichier s'ouvre correctement).L'image suivante montre un extrait de la sortie dans Microsoft Excel.
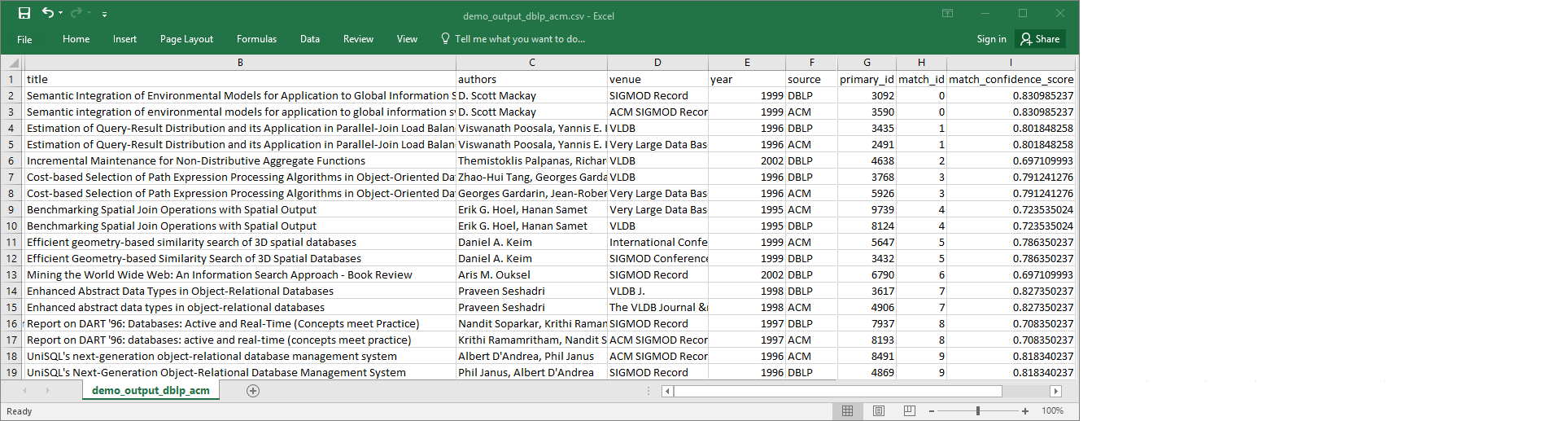
La source de données et le fichier cible comportent tous deux 4 911 enregistrements. Toutefois, la transformation
Find matchesajoute une autre colonne nomméematch_idpour identifier les enregistrements correspondants dans la sortie. Les lignes avec le mêmematch_idsont considérées comme des enregistrements correspondants. Lematch_confidence_scoreest un nombre compris entre 0 et 1 qui fournit une estimation de la qualité des correspondances trouvées parFind matches.-
Triez le fichier de sortie par
match_idafin de voir facilement les enregistrements qui sont des correspondances. Comparez les valeurs des autres colonnes pour voir si les résultats de la transformationFind matchesvous conviennent. Si ce n'est pas le cas, vous pouvez continuer à entraîner la transformation en ajoutant d'autres étiquettes.Vous pouvez également trier le fichier sur un autre champ, par exemple
title, pour voir si les enregistrements avec des titres similaires ont le mêmematch_id.
