Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Surveillance avec les informations sur l'exécution de la tâcheAWS Glue
AWS GlueJob Run Insights est une fonctionnalité AWS Glue qui simplifie le débogage des tâches et l'optimisation de vos AWS Glue tâches. AWS Gluefournit l'interface utilisateur Spark, ainsi que CloudWatch des journaux et des indicateurs pour surveiller vos AWS Glue tâches. Grâce à cette fonctionnalité, vous obtenez les informations suivantes concernant l'exécution de votre AWS Glue tâche :
Le numéro de ligne de votre script de tâche AWS Glue qui a échoué.
L'action Spark exécutée en dernier dans le plan de requête Spark juste avant l'échec de votre tâche.
Les événements d'exception Spark liés à l'échec présenté dans un flux de journal classé par ordre chronologique.
L'analyse des causes racines et l'action recommandée (telle que le réglage de votre script) pour résoudre le problème.
Les événements Spark courants (messages de journaux relatifs à une action Spark) avec une action recommandée qui traite la cause racine.
Toutes ces informations sont mises à votre disposition à l'aide de deux nouveaux flux de journaux dans les CloudWatch journaux de vos AWS Glue tâches.
Prérequis
La fonctionnalité AWS Glue Job Run Insights est disponible pour AWS Glue les versions 2.0, 3.0 et 4.0. Vous pouvez suivre le Guide de migration pour vos tâches existantes afin de les mettre à niveau à partir d'anciennes versions AWS Glue.
Activation des informations relatives à l'exécution des tâches pour une tâche AWS Glue ETL
Vous pouvez activer les informations sur l'exécution de la tâche via AWS Glue Studio ou le CLI.
AWS Glue Studio
Lors de la création d'une tâche via AWS Glue Studio, vous pouvez activer ou désactiver les informations sur l'exécution de la tâche sous l'onglet Détails de la tâche. Vérifiez que la case Générer des informations sur les tâches est sélectionnée.

Ligne de commande
Si vous créez une tâche via le CLI, vous pouvez démarrer l'exécution d'une tâche avec un seul nouveau paramètre de tâche :--enable-job-insights = true.
Par défaut, les flux de journaux des informations sur l'exécution de la tâche sont créés sous le même groupe de journaux par défaut utilisé par AWS Gluejournalisation continue, c'est-à-dire, /aws-glue/jobs/logs-v2/. Vous pouvez configurer un nom de groupe de journaux personnalisé, des filtres de journaux et des configurations de groupes de journaux à l'aide du même ensemble d'arguments que pour la journalisation continue. Pour plus d'informations, consultez Activation de la journalisation continue pour les tâches AWS Glue.
Accès aux flux de journaux Job Run Insights dans CloudWatch
Lorsque la fonctionnalité des informations sur l'exécution de la tâche est activée, deux flux de journaux peuvent être créés en cas d'échec d'une exécution de tâche. Lorsqu'une tâche se termine correctement, aucun des flux n'est généré.
Flux de journaux d'analyse des exceptions :
<job-run-id>-job-insights-rca-driver. Ce flux fournit les informations suivantes :Le numéro de ligne de votre script de tâche AWS Glue qui a causé l'échec.
L'action Spark exécutée en dernier dans le plan de requête Spark (DAG).
Les événements chronologiques concis provenant du pilote Spark et les programmes d'exécution associés à l'exception. Vous pourrez trouver des détails tels que des messages d'erreur complets, la tâche Spark qui a échoué et l'ID de ses programmes d'exécution. Ces informations vous aident à vous concentrer sur le flux de journal du programme d'exécution spécifique pour une analyse plus approfondie si nécessaire.
Flux d'informations basé sur des règles :
Analyse des causes racines et recommandations sur la manière de corriger les erreurs (telles que l'utilisation d'un paramètre de tâche spécifique pour optimiser les performances).
Les événements Spark pertinents servant de base à l'analyse des causes racines et à une action recommandée.
Note
Le premier flux n'existera que si des événements Spark d'exception sont disponibles pour une exécution de tâche qui a échoué, et le second flux n'existera que si des informations sont disponibles pour l'exécution de la tâche qui a échoué. Par exemple, si votre tâche se termine correctement, aucun des flux ne sera généré. Si votre tâche échoue, mais qu'aucune règle définie par le service ne correspond à votre scénario d'échec, seul le premier flux sera généré.
Si la tâche est créée à partir de AWS Glue Studio, les liens vers les flux ci-dessus sont également disponibles sous l'onglet détails de l'exécution de la tâche (Informations sur l'exécution de la tâche) sous les rubriques « Journaux d'erreurs concis et consolidés » et « Analyse d'erreurs et conseils ».
Exemple pour les informations sur l'exécution de la tâche AWS Glue
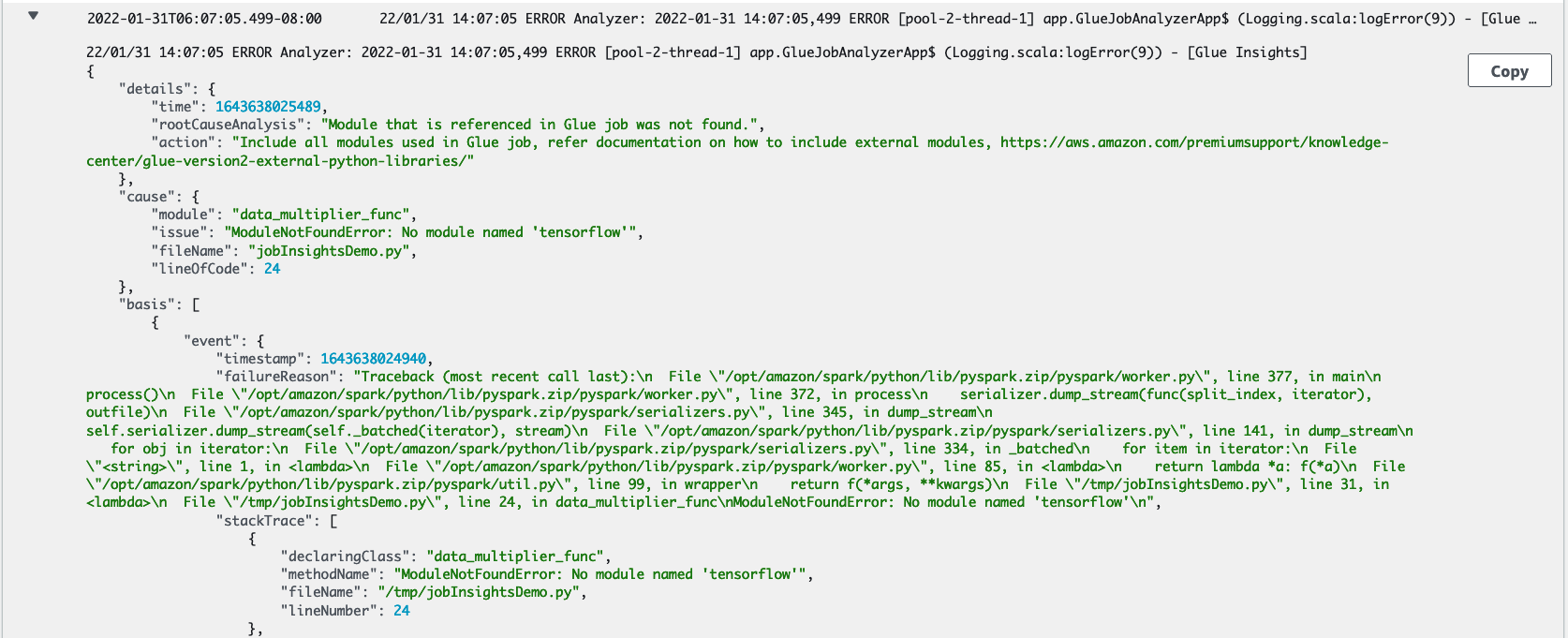
Dans cette section, nous vous présentons un exemple de la façon dont la fonctionnalité d'informations sur l'exécution de la tâche peut vous aider à résoudre un problème lié à votre tâche qui a échoué. Dans cet exemple, un utilisateur a oublié d'importer le module requis (tensorflow) dans une tâche AWS Glue pour analyser et créer un modèle de machine learning à partir de leurs données.
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.types import * from pyspark.sql.functions import udf,col args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) data_set_1 = [1, 2, 3, 4] data_set_2 = [5, 6, 7, 8] scoresDf = spark.createDataFrame(data_set_1, IntegerType()) def data_multiplier_func(factor, data_vector): import tensorflow as tf with tf.compat.v1.Session() as sess: x1 = tf.constant(factor) x2 = tf.constant(data_vector) result = tf.multiply(x1, x2) return sess.run(result).tolist() data_multiplier_udf = udf(lambda x:data_multiplier_func(x, data_set_2), ArrayType(IntegerType(),False)) factoredDf = scoresDf.withColumn("final_value", data_multiplier_udf(col("value"))) print(factoredDf.collect())
La tâche échoue et ,sans la fonctionnalité informations sur l'exécution de la tâche, vous ne voyez que ce message généré par Spark :
An error occurred while calling o111.collectToPython. Traceback (most recent call last):
Le message est ambigu et limite votre expérience de débogage. Dans ce cas, cette fonctionnalité vous fournit des informations supplémentaires dans deux flux de CloudWatch journaux :
Le flux de journal
job-insights-rca-driver:Événements d'exception : ce flux de journal fournit les événements d'exception Spark liés à l'échec collecté à partir du pilote Spark et de différents travailleurs distribués. Ces événements vous aident à comprendre la propagation chronologique de l'exception lorsque du code défectueux s'exécute sur les tâches Spark, les programmes d'exécution et les étapes distribuées sur les travailleurs AWS Glue.
Numéros de ligne: ce flux de journal identifie la ligne 21, qui a appelé à importer le module Python manquant à l'origine de l'échec. Il identifie également la ligne 24, l'appel à l'action Spark
collect(), en tant que dernière ligne exécutée dans votre script.
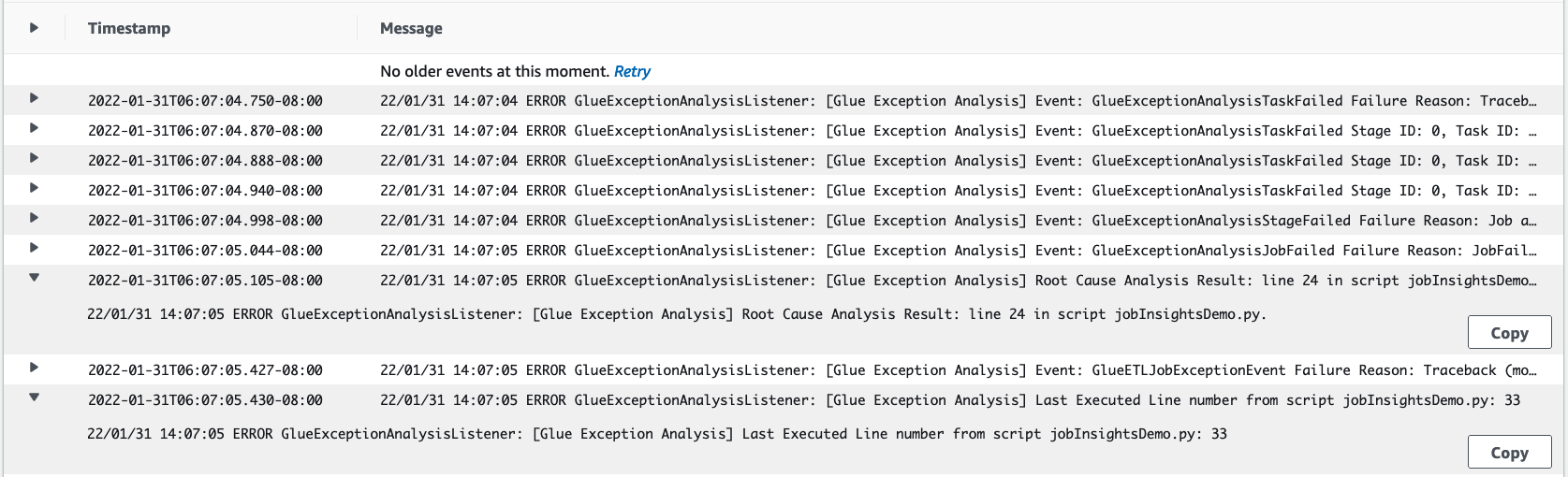
Le flux de journal
job-insights-rule-driver:Cause racine et recommandation : en plus du numéro de ligne et du dernier numéro de ligne exécuté pour l'erreur dans votre script, ce flux de journal affiche l'analyse des causes racines et la recommandation pour que vous puissiez suivre le document AWS Glue et configurer les paramètres de tâches nécessaires afin d'utiliser un module Python supplémentaire dans votre tâche AWS Glue.
Événement récurrent : ce flux de journal affiche également l'événement d'exception Spark qui a été évalué avec la règle définie par le service afin d'en déduire la cause racine et de fournir une recommandation.