Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Stockage des données Spark Shuffle
La réorganisation est une étape importante d'une tâche Spark chaque fois que les données sont réarrangées entre des partitions. Elle est nécessaire parce que de larges transformations telles que join,
groupByKey, reduceByKey et repartition ont besoin d'informations provenant d'autres partitions pour terminer le traitement. Spark rassemble les données requises de chaque partition et les combine dans une nouvelle partition. Lors d'une réorganisation, les données sont écrites sur le disque et transférées via le réseau. Par conséquent, l'opération de réorganisation est liée à la capacité du disque local. Spark émet une erreur No space left on device ou
MetadataFetchFailedException lorsqu'il n'y a pas assez d'espace disque sur le programme d'exécution et qu'il n'y a pas de récupération.
Note
AWS Glue Le plugin Spark shuffle avec Amazon S3 n'est pris en charge que pour les tâches AWS Glue ETL.
Solution
Avec AWS Glue, vous pouvez désormais utiliser Amazon S3 pour stocker les données Spark Shuffle. Amazon S3 est un service de stockage d'objets qui offre une évolutivité, une disponibilité des données, une sécurité et des performances de pointe. Cette solution désagrège le calcul et le stockage pour vos tâches Spark, et offre une élasticité totale et un stockage économique de la réorganisation, ce qui vous permet d'exécuter vos applications les plus complexes de manière fiable.
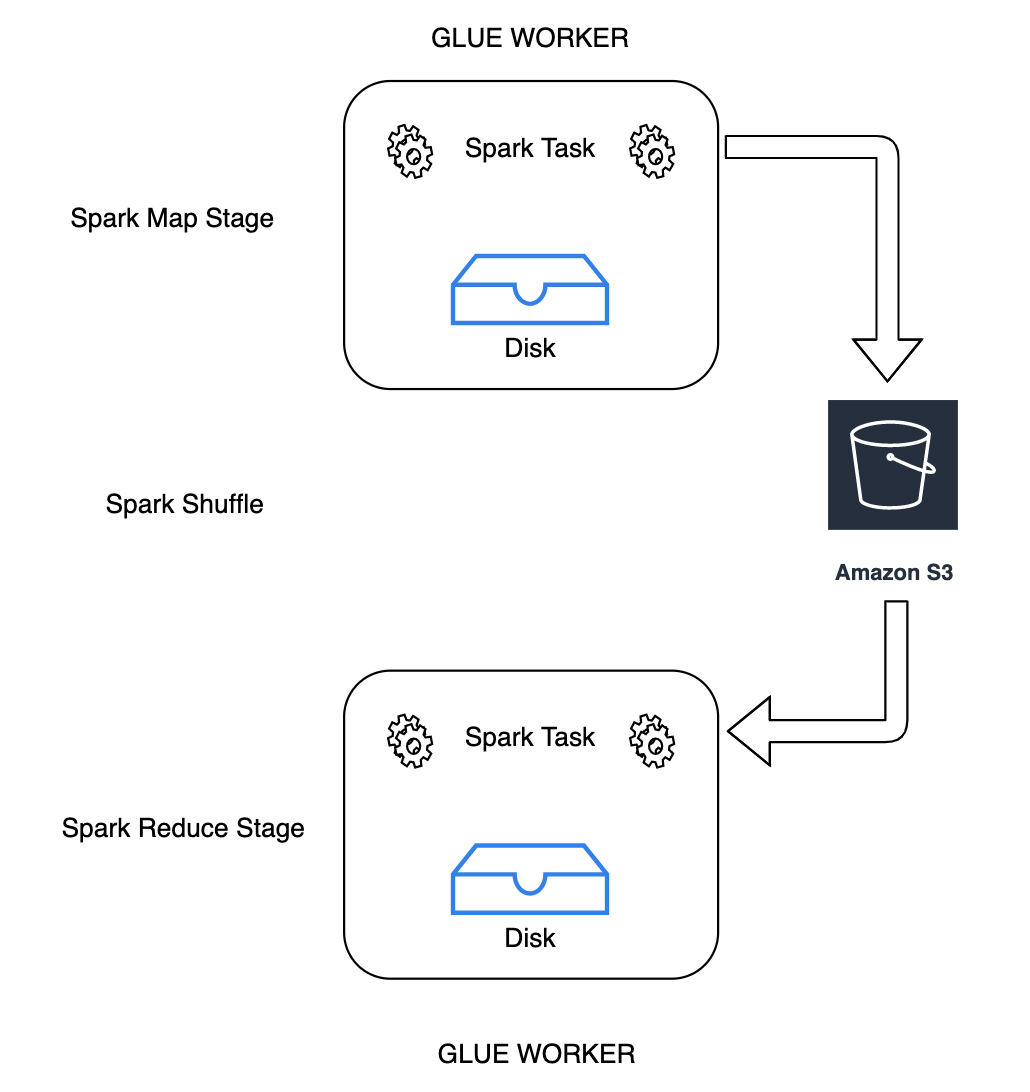
Nous introduisons un nouveau plug-in Cloud Shuffle Storage pour Apache Spark afin d'utiliser Amazon S3. Vous pouvez activer Amazon S3 shuffling pour exécuter votre AWS Glue des tâches fiables et sans défaillance si l'on sait qu'elles sont limitées par la capacité du disque local pour les opérations de brassage de grande envergure. Dans certains cas, une réorganisation vers Amazon S3 est légèrement plus lente que vers un disque local (ou EBS) si vous avez un grand nombre de petites partitions ou de fichiers réorganisés écrits dans Amazon S3.
Conditions préalables à l'utilisation du plug-in de stockage de réorganisation du cloud.
Pour utiliser le plug-in de stockage Cloud Shuffle avec des tâches AWS Glue ETL, vous avez besoin des éléments suivants :
-
Un compartiment Amazon S3 situé dans la même région que celle de votre exécution de tâche, pour stocker la réorganisation intermédiaire et les données déversées. Le préfixe Amazon S3 du stockage de réorganisation peut être spécifié avec
--conf spark.shuffle.glue.s3ShuffleBucket=s3://, comme dans l'exemple suivant :shuffle-bucket/prefix/--conf spark.shuffle.glue.s3ShuffleBucket=s3://glue-shuffle-123456789-us-east-1/glue-shuffle-data/ -
Définissez les stratégies de cycle de vie du stockage Amazon S3 sur le préfixe (tel que
glue-shuffle-data), car le gestionnaire de réorganisation ne nettoie pas les fichiers une fois la tâche terminée. La réorganisation intermédiaire et les données déversées doivent être supprimées une fois la tâche terminée. Les utilisateurs peuvent définir des stratégies de cycle de vie court pour le préfixe. Les instructions de configuration d'une stratégie de cycle de vie Amazon S3 sont disponibles dans la section Configuration du cycle de vie d'un compartiment dans le Guide de l'utilisateur Amazon Simple Storage Service.
Utilisation AWS Glue Gestionnaire de shuffle Spark depuis la console AWS
Pour configurer le AWS Glue Gestionnaire de shuffle Spark utilisant le AWS Glue console ou AWS Glue Studio lors de la configuration d'une tâche : choisissez le paramètre de tâche -- write-shuffle-files-to -s3 pour activer le shuffling Amazon S3 pour la tâche.
Utilisation AWS Glue Plug-in Spark Shuffle
Les paramètres de tâche suivants activent et ajustent le AWS Glue gestionnaire de shuffle. Ces paramètres étant des indicateurs, les valeurs fournies ne sont pas prises en compte.
-
--write-shuffle-files-to-s3— Le drapeau principal, qui active le AWS Glue Spark Shuffle Manager pour utiliser les compartiments Amazon S3 pour écrire et lire des données de shuffle. Lorsque l'indicateur n'est pas spécifié, le gestionnaire de réorganisation n'est pas utilisé. -
--write-shuffle-spills-to-s3— (Supporté uniquement sur AWS Glue version 2.0). Indicateur facultatif qui vous permet de décharger des fichiers de déversement dans des compartiments Amazon S3, pour une résilience supplémentaire de votre tâche Spark. Ceci n'est requis que pour les charges de travail volumineuses qui déversent beaucoup de données sur le disque. Lorsque l'indicateur n'est pas spécifié, aucun fichier de déversement intermédiaire n'est écrit. -
--conf spark.shuffle.glue.s3ShuffleBucket=s3://<shuffle-bucket>– autre indicateur facultatif spécifiant le compartiment Amazon S3 dans lequel vous écrivez les fichiers de réorganisation. Par défaut,--TempDir/shuffle-data. AWS Glue La version 3.0+ prend en charge l'écriture de fichiers shuffle dans plusieurs compartiments en spécifiant des compartiments avec un séparateur par virgule, comme dans.--conf spark.shuffle.glue.s3ShuffleBucket=s3://L'utilisation de plusieurs compartiments améliore les performances.shuffle-bucket-1/prefix,s3://shuffle-bucket-2/prefix/
Vous devez fournir des paramètres de configuration de sécurité pour activer le chiffrement au repos des données de réorganisation. Pour plus d'informations sur les configurations de sécurité, consultez Configuration du chiffrement dans AWS Glue. AWS Glue prend en charge toutes les autres configurations liées au shuffle fournies par Spark.
Binaires logiciels pour le plug-in Cloud Shuffle Storage
Vous pouvez également télécharger les fichiers binaires du plug-in Cloud Shuffle Storage pour Apache Spark sous la licence Apache 2.0 et l'exécuter dans n'importe quel environnement Spark. Le nouveau plugin est compatible avec out-of-the Amazon S3 et peut également être facilement configuré pour utiliser d'autres formes de stockage dans le cloud, telles que Google Cloud Storage et Microsoft Azure Blob Storage
Remarques et limitations
Vous trouverez ci-dessous des remarques ou des restrictions concernant le AWS Glue gestionnaire de shuffle :
-
AWS Glue le gestionnaire de shuffle ne supprime pas automatiquement les fichiers de données de shuffle (temporaires) stockés dans votre compartiment Amazon S3 une fois la tâche terminée. Pour garantir la protection des données, suivez les instructions fournies dans Conditions préalables à l'utilisation du plug-in de stockage de réorganisation du cloud. avant d'activer le plug-in Cloud Shuffle Storage.
-
Vous pouvez utiliser cette fonction si vos données sont biaisées.
