Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de Agrégation pour effectuer des calculs récapitulatifs sur des champs sélectionnés
Pour utiliser Aggregate transform (transformation d'agrégation)
-
Ajoutez le Aggregate node (nœud d'agrégation) au diagramme de tâches.
-
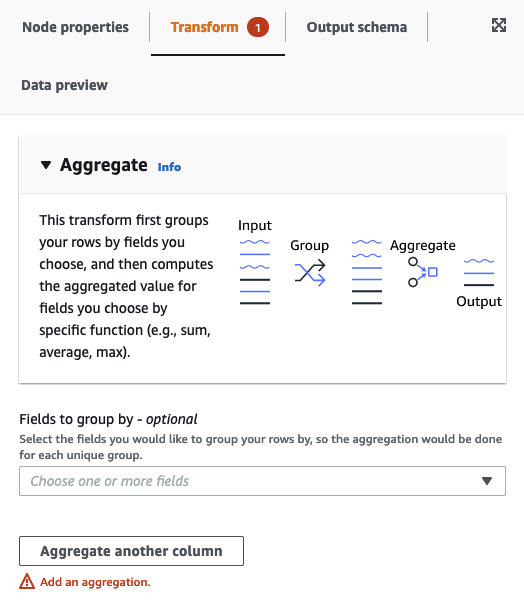
Dans l'onglet Node properties (Propriétés de nœud), choisissez les champs à regrouper en sélectionnant le champ déroulant (facultatif). Vous pouvez sélectionner plusieurs champs à la fois ou rechercher un nom de champ en saisissant dans la barre de recherche.
Lorsque les champs sont sélectionnés, le nom et le type de données sont affichés. Pour supprimer un champ, choisissez « X » sur le champ.
-
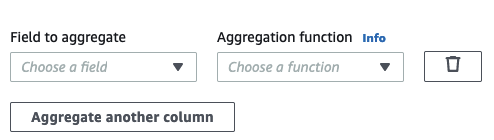
Choisissez Aggregate another column (Agréger une autre colonne). Il est nécessaire de sélectionner au moins un champ.
-
Choisissez un champ dans le champ déroulant Field to aggregate (Champ à agréger).
-
Choisissez la fonction d'agrégation à appliquer au champ choisi :
-
avg – calcule la moyenne
-
countDistinct – calcule le nombre de valeurs uniques non null
-
count – calcule le nombre de valeurs non null
-
first – renvoie la première valeur qui répond aux critères de « groupe par »
-
last – renvoie la dernière valeur qui répond aux critères de « groupe par »
-
kurtosis – calcule la netteté du pic d'une courbe de distribution de fréquences
-
max – renvoie la valeur la plus élevée qui répond aux critères de « groupe par »
-
min – renvoie la valeur la plus basse qui répond aux critères de « groupe par »
-
asymétrie – mesure de l'asymétrie de la distribution de probabilité d'une distribution normale
-
stddev_pop – calcule l'écart type de population et renvoie la racine carrée de la variance de la population
-
sum – la somme de toutes les valeurs dans le groupe
-
sumDistinct – la somme des valeurs distinctes dans le groupe
-
var_samp – la variance d'échantillon du groupe (ignore les valeurs nulles)
-
var_pop – la variance de la population du groupe (ignore les valeurs nulles)
-
