Avis de fin de support : le 7 octobre 2026,AWS le support de.AWS IoT Greengrass Version 1 Après le 7 octobre 2026, vous ne pourrez plus accéder aux AWS IoT Greengrass V1 ressources. Pour plus d'informations, rendez-vous sur Migrer depuis AWS IoT Greengrass Version 1.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exécuter l'inférence de Machine Learning
Cette fonctionnalité est disponible pour AWS IoT Greengrass Core v1.6 ou version ultérieure.
Vous pouvez AWS IoT Greengrass ainsi effectuer des inférences basées sur le machine learning (ML) à la périphérie sur des données générées localement à l'aide de modèles conçus dans le cloud. Vous bénéficiez d'une faible latence et de coûts d'inférence locale réduits, tout en profitant des avantages de la puissance du cloud computing pour les modèles de formation et les traitements complexes.
Pour commencer à exécuter l'inférence locale, consultez Comment configurer l'inférence d'apprentissage automatique à l'aide du AWS Management Console.
Comment ? AWS IoT Greengrass L'inférence ML fonctionne
Vous pouvez entraîner vos modèles d'inférence n'importe où, les déployer localement en tant que ressources d'apprentissage automatique dans un groupe Greengrass, puis y accéder à partir des fonctions Greengrass Lambda. Par exemple, vous pouvez créer et entraîner des modèles d'apprentissage profond en SageMaker intelligence artificielle
Le schéma suivant montre le flux de travail d'inférence AWS IoT Greengrass ML.
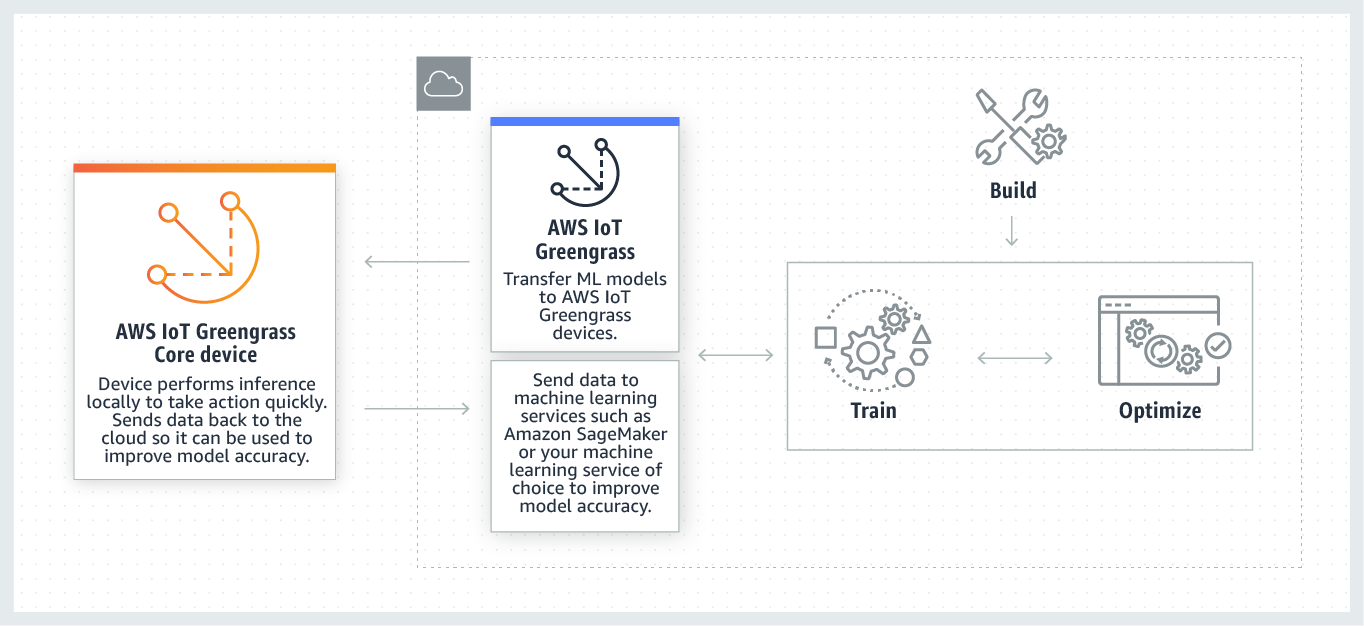
AWS IoT Greengrass L'inférence ML simplifie chaque étape du flux de travail ML, notamment :
-
La création et le déploiement de prototypes d'infrastructure de Machine Learning.
-
L'accès aux modèles formés dans le cloud et leur déploiement dans les appareils Greengrass principaux.
-
La création d'applications d'inférence pouvant accéder à des accélérateurs matériels (tels que des GPU et des FPGA) en tant que ressources locales.
Ressource de Machine Learning
Les ressources d'apprentissage automatique représentent des modèles d'inférence formés dans le cloud qui sont déployés sur un AWS IoT Greengrass cœur. Pour déployer des ressources de machine learning, vous devez d'abord les ajouter à un groupe Greengrass, puis vous définissez comment les fonctions Lambda du groupe peuvent y accéder. Lors du déploiement en groupe, AWS IoT Greengrass récupère les packages du modèle source depuis le cloud et les extrait dans des répertoires de l'espace de noms d'exécution Lambda. Les fonctions Greengrass Lambda utilisent ensuite les modèles déployés localement pour effectuer des inférences.
Pour mettre à jour un modèle déployé localement, commencez par mettre à jour le modèle source (dans le cloud) qui correspond à la ressource de Machine Learning, puis déployez le groupe. Pendant le déploiement, AWS IoT Greengrass vérifie si la source a fait l'objet de modifications. Si des modifications sont détectées, le modèle local est AWS IoT Greengrass mis à jour.
Sources de modèles prises en charge
AWS IoT Greengrass prend en charge les sources du modèle SageMaker AI et Amazon S3 pour les ressources d'apprentissage automatique.
Les exigences suivantes s'appliquent aux sources de modèles :
-
Les compartiments S3 qui stockent les sources de votre SageMaker IA et de votre modèle Amazon S3 ne doivent pas être chiffrés à l'aide SSE-C de. Pour les buckets qui utilisent le chiffrement côté serveur, AWS IoT Greengrass ML Inference ne prend actuellement en charge que les options de chiffrement SSE-S3 or SSE-KMS . Pour plus d'informations sur les options de chiffrement côté serveur, consultez la section Protection des données à l'aide du chiffrement côté serveur dans le guide de l'utilisateur d'Amazon Simple Storage Service.
-
Les noms des compartiments S3 qui stockent les sources de votre SageMaker IA et de votre modèle Amazon S3 ne doivent pas inclure de points (
.). Pour plus d'informations, consultez la règle concernant l'utilisation de compartiments de type hébergé virtuel avec SSL dans Règles de dénomination des compartiments du guide de l'utilisateur d'Amazon Simple Storage Service. -
Service-level Région AWS un support doit être disponible à la fois pour l'SageMaker IA AWS IoT Greengrasset pour l'IA. Actuellement, AWS IoT Greengrass prend en charge les modèles d' SageMaker IA dans les régions suivantes :
-
USA Est (Ohio)
-
USA Est (Virginie du Nord)
-
USA Ouest (Oregon)
-
Asie-Pacifique (Mumbai)
-
Asie-Pacifique (Séoul)
-
Asie-Pacifique (Singapour)
-
Asie-Pacifique (Sydney)
-
Asie-Pacifique (Tokyo)
-
Europe (Francfort)
-
Europe (Irlande)
-
Europe (Londres)
-
-
AWS IoT Greengrass doit avoir
readl'autorisation d'accéder à la source du modèle, comme décrit dans les sections suivantes.
- SageMaker AI
-
AWS IoT Greengrass prend en charge les modèles enregistrés en tant que tâches de formation à l' SageMaker IA. SageMaker L'IA est un service de machine learning entièrement géré que vous pouvez utiliser pour créer et entraîner des modèles à l'aide d'algorithmes intégrés ou personnalisés. Pour plus d'informations, voir Qu'est-ce que SageMaker l'IA ? dans le Guide du développeur d'SageMaker IA.
Si vous avez configuré votre environnement d' SageMaker IA en créant un bucket dont le nom contient
sagemaker, vous AWS IoT Greengrass disposez des autorisations suffisantes pour accéder à vos tâches de formation à l' SageMaker IA. La stratégie géréeAWSGreengrassResourceAccessRolePolicyautorise l'accès aux compartiments dont le nom contient la chaînesagemaker. Cette stratégie est attachée au rôle de service Greengrass.Dans le cas contraire, vous devez AWS IoT Greengrass
readautoriser le bucket dans lequel votre tâche de formation est stockée. Pour ce faire, intégrez la stratégie en ligne suivante dans le rôle de service. Vous pouvez répertorier plusieurs ARN de compartiment. - Amazon S3
-
AWS IoT Greengrass prend en charge les modèles stockés dans Amazon S3 sous forme
tar.gzde.zipfichiers.Pour permettre AWS IoT Greengrass l'accès aux modèles stockés dans des compartiments Amazon S3, vous devez AWS IoT Greengrass
readautoriser l'accès aux compartiments en effectuant l'une des opérations suivantes :-
Stockez votre modèle dans un compartiment dont le nom contient
greengrass.La stratégie gérée
AWSGreengrassResourceAccessRolePolicyautorise l'accès aux compartiments dont le nom contient la chaînegreengrass. Cette stratégie est attachée au rôle de service Greengrass. -
Intégrez une stratégie en ligne dans le rôle de service Greengrass.
Si le nom de votre compartiment ne contient pas
greengrass, ajoutez la stratégie en ligne suivante au rôle de service. Vous pouvez répertorier plusieurs ARN de compartiment.Pour plus d'informations, consultez la section Intégration de politiques intégrées dans le guide de l'utilisateur IAM.
-
Exigences
Les exigences suivantes s'appliquent pour la création et l'utilisation des ressources de Machine Learning :
-
Vous devez utiliser AWS IoT Greengrass Core v1.6 ou version ultérieure.
-
User-defined Les fonctions Lambda peuvent effectuer
readdesread and writeopérations sur la ressource. Les autorisations pour d'autres opérations ne sont pas disponibles. Le mode de conteneurisation des fonctions Lambda affiliées détermine la manière dont vous définissez les autorisations d'accès. Pour de plus amples informations, veuillez consulter Accédez aux ressources d'apprentissage automatique à partir des fonctions Lambda. -
Vous devez fournir le chemin d'accès complet de la ressource sur le système d'exploitation de l'appareil principal.
-
Un ID ou un nom de ressource doit comporter 128 caractères au maximum et utiliser le modèle
[a-zA-Z0-9:_-]+.
Environnements d'exécution et bibliothèques pour l'inférence ML
Vous pouvez utiliser les environnements d'exécution et bibliothèques ML suivants avec AWS IoT Greengrass.
-
Apache MXNet
-
TensorFlow
Ces environnements d’exécution et ces bibliothèques peuvent être installés sur les plateformes NVIDIA Jetson TX2, Intel Atom et Raspberry Pi. Pour obtenir des informations sur le téléchargement, consultez Bibliothèques et environnements d'exécution de machine learning pris en charge. Vous pouvez les installer directement sur votre appareil principal (noyau).
Assurez-vous de lire les informations de compatibilités et les limitations suivantes.
SageMaker Runtime d'apprentissage profond AI Neo
Vous pouvez utiliser le moteur d'apprentissage profond SageMaker AI Neo pour effectuer des inférences avec des modèles d'apprentissage automatique optimisés sur vos AWS IoT Greengrass appareils. Ces modèles sont optimisés à l'aide du compilateur d'apprentissage profond SageMaker AI Neo pour améliorer les vitesses de prédiction des inférences par apprentissage automatique. Pour plus d'informations sur l'optimisation des modèles dans l' SageMaker IA, consultez la documentation SageMaker AI Neo.
Note
Actuellement, vous pouvez optimiser les modèles d'apprentissage automatique à l'aide du compilateur d'apprentissage profond Neo uniquement dans des régions Amazon Web Services spécifiques. Cependant, vous pouvez utiliser le moteur d'apprentissage profond Neo avec des modèles optimisés dans chaque Région AWS cas où le AWS IoT Greengrass noyau est pris en charge. Pour plus d'informations, consultez Configuration de l'inférence Machine Learning optimisée.
Gestion des versions MXNet
Apache MXNet ne garantit actuellement pas une compatibilité ascendante. Par conséquent, les modèles que vous formez à l'aide de versions ultérieures de l'infrastructure peuvent ne pas fonctionner correctement dans des versions antérieures de l'infrastructure. Pour éviter les conflits entre les étapes de formation et d'utilisation des modèles, et pour garantir une expérience uniforme de bout en bout, utilisez la même version d'infrastructure MXNet à chaque étape.
MXNet sur Raspberry Pi
Les fonctions Greengrass Lambda qui accèdent aux modèles MXNet locaux doivent définir la variable d'environnement suivante :
MXNET_ENGINE_TYPE=NativeEngine
Vous pouvez définir la variable d'environnement dans le code de la fonction ou l'ajouter à la configuration spécifique au groupe de la fonction. Cette étape présente un exemple qui ajoute la variable d'environnement en tant que paramètre de configuration.
Note
Pour une utilisation générale de l'infrastructure MXNet, telle que l'exécution d'un exemple de code tiers, la variable d'environnement doit être configurée sur le Raspberry Pi.
TensorFlow limites de service de modèles sur le Raspberry Pi
Les recommandations suivantes pour améliorer les résultats d'inférence sont basées sur nos tests avec les bibliothèques Arm TensorFlow 32 bits sur la plate-forme Raspberry Pi. Ces recommandations sont destinées aux utilisateurs avancés pour référence uniquement, sans garantie d'aucune sorte.
-
Les modèles formés à l'aide du format Checkpoint
doivent être « bloqués » dans le format tampon du protocole avant d'être utilisés. Pour un exemple, consultez la bibliothèque de modèles de classification d'TensorFlow-Slim images . -
N'utilisez pas les TF-Slim bibliothèques TF-Estimator et dans le code d'entraînement ou dans le code d'inférence. À la place, utilisez le modèle de chargement de fichier
.pbindiqué dans l'exemple suivant.graph = tf.Graph() graph_def = tf.GraphDef() graph_def.ParseFromString(pb_file.read()) with graph.as_default(): tf.import_graph_def(graph_def)
Note
Pour plus d'informations sur les plateformes prises en charge pour TensorFlow, consultez la section Installation TensorFlow
