Avis de fin de support : le 7 octobre 2026,AWS le support de.AWS IoT Greengrass Version 1 Après le 7 octobre 2026, vous ne pourrez plus accéder aux AWS IoT Greengrass V1 ressources. Pour plus d'informations, rendez-vous sur Migrer depuis AWS IoT Greengrass Version 1.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configurations d'exportation prises en charge AWS Cloud destinations
User-defined Les fonctions Lambda sont utilisées StreamManagerClient dans le SDK AWS IoT Greengrass Core pour interagir avec le gestionnaire de flux. Lorsqu'une fonction Lambda crée un flux ou met à jour un flux, elle transmet un MessageStreamDefinition objet qui représente les propriétés du flux, y compris la définition de l'exportation. L'ExportDefinitionobjet contient les configurations d'exportation définies pour le flux. Le gestionnaire de flux utilise ces configurations d'exportation pour déterminer où et comment exporter le flux.
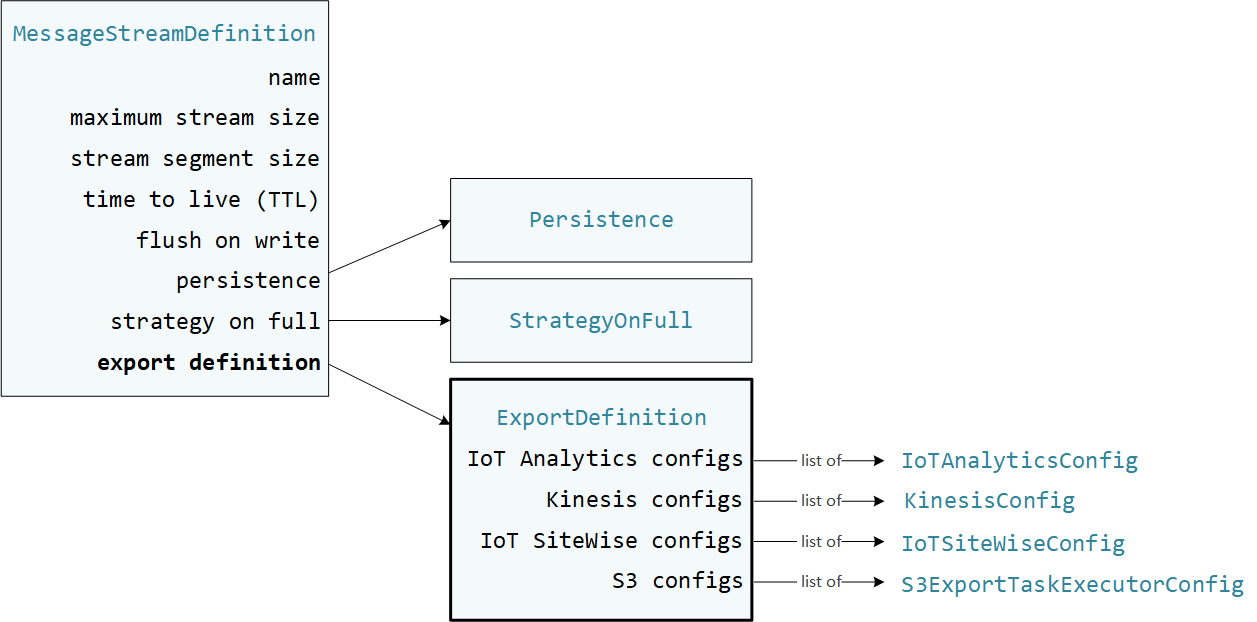
Vous pouvez définir zéro ou plusieurs configurations d'exportation sur un flux, y compris plusieurs configurations d'exportation pour un seul type de destination. Par exemple, vous pouvez exporter un flux vers deux AWS IoT Analytics canaux et un flux de données Kinesis.
En cas d'échec des tentatives d'exportation, le gestionnaire de flux essaie continuellement d'exporter les données à des AWS Cloud intervalles allant jusqu'à cinq minutes. Le nombre de nouvelles tentatives n'est pas limité.
Note
StreamManagerClientfournit également une destination cible que vous pouvez utiliser pour exporter des flux vers un serveur HTTP. Cette cible n'est destinée qu'à des fins de test. Il n'est pas stable ni pris en charge pour une utilisation dans des environnements de production.
AWS Cloud Destinations prises en charge
Vous êtes responsable de la maintenance de ces AWS Cloud ressources.
AWS IoT Analytics canaux
Le gestionnaire de flux prend en charge les exportations automatiques vers AWS IoT Analytics. AWS IoT Analytics vous permet d'effectuer une analyse avancée de vos données afin de prendre des décisions commerciales et d'améliorer les modèles d'apprentissage automatique. Pour plus d'informations, voir Qu'est-ce que c'est AWS IoT Analytics ? dans le guide de AWS IoT Analytics l'utilisateur.
Dans le SDK AWS IoT Greengrass principal, vos fonctions Lambda utilisent IoTAnalyticsConfig le pour définir la configuration d'exportation pour ce type de destination. Pour plus d'informations, consultez la référence du SDK pour votre langue cible :
-
IoTAnalyticsConfig
dans le SDK Python -
IoTAnalyticsConfig
dans le SDK Java -
IoTAnalyticsConfig
dans le Node.js SDK
Exigences
Cette destination d'exportation répond aux exigences suivantes :
-
Les canaux cibles entrants AWS IoT Analytics doivent appartenir au même groupe Greengrass Compte AWS et Région AWS appartenir à celui-ci.
-
Ils Rôle de groupe Greengrass doivent
iotanalytics:BatchPutMessageautoriser les chaînes cibles. Par exemple :Vous pouvez accorder un accès granulaire ou conditionnel aux ressources, par exemple en utilisant un schéma de
*dénomination générique. Pour plus d'informations, consultez la section Ajout et suppression de politiques IAM dans le Guide de l'utilisateur IAM.
Exporter vers AWS IoT Analytics
Pour créer un flux exporté vers AWS IoT Analytics, vos fonctions Lambda créent un flux avec une définition d'exportation qui inclut un ou plusieurs IoTAnalyticsConfig objets. Cet objet définit les paramètres d'exportation, tels que le canal cible, la taille du lot, l'intervalle entre les lots et la priorité.
Lorsque vos fonctions Lambda reçoivent des données provenant d'appareils, elles ajoutent des messages contenant un blob de données au flux cible.
Le gestionnaire de flux exporte ensuite les données en fonction des paramètres de lot et de la priorité définis dans les configurations d'exportation du flux.
Flux de données Amazon Kinesis
Le gestionnaire de flux prend en charge les exportations automatiques vers Amazon Kinesis Data Streams. Kinesis Data Streams est couramment utilisé pour agréger de gros volumes de données et les charger dans un entrepôt de données ou un cluster Map-Reduce. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Kinesis Data Streams ? dans le manuel Amazon Kinesis Developer Guide.
Dans le SDK AWS IoT Greengrass principal, vos fonctions Lambda utilisent KinesisConfig le pour définir la configuration d'exportation pour ce type de destination. Pour plus d'informations, consultez la référence du SDK pour votre langue cible :
-
KinesisConfig
dans le SDK Python -
KinesisConfig
dans le SDK Java -
KinesisConfig
dans le Node.js SDK
Exigences
Cette destination d'exportation répond aux exigences suivantes :
-
Les flux cibles dans Kinesis Data Streams doivent appartenir au Compte AWS même groupe Greengrass Région AWS et appartenir à celui-ci.
-
Ils Rôle de groupe Greengrass doivent
kinesis:PutRecordsautoriser le ciblage des flux de données. Par exemple :Vous pouvez accorder un accès granulaire ou conditionnel aux ressources, par exemple en utilisant un schéma de
*dénomination générique. Pour plus d'informations, consultez la section Ajout et suppression de politiques IAM dans le Guide de l'utilisateur IAM.
Exportation vers Kinesis Data Streams
Pour créer un flux exporté vers Kinesis Data Streams, vos fonctions Lambda créent un flux avec une définition d'exportation qui inclut un ou plusieurs objets. KinesisConfig Cet objet définit les paramètres d'exportation, tels que le flux de données cible, la taille du lot, l'intervalle entre les lots et la priorité.
Lorsque vos fonctions Lambda reçoivent des données provenant d'appareils, elles ajoutent des messages contenant un blob de données au flux cible. Le gestionnaire de flux exporte ensuite les données en fonction des paramètres de lot et de la priorité définis dans les configurations d'exportation du flux.
Le gestionnaire de flux génère un UUID unique et aléatoire comme clé de partition pour chaque enregistrement chargé sur Amazon Kinesis.
AWS IoT SiteWise propriétés des actifs
Le gestionnaire de flux prend en charge les exportations automatiques vers AWS IoT SiteWise. AWS IoT SiteWise vous permet de collecter, d'organiser et d'analyser les données des équipements industriels à grande échelle. Pour plus d'informations, voir Qu'est-ce que c'est AWS IoT SiteWise ? dans le guide de AWS IoT SiteWise l'utilisateur.
Dans le SDK AWS IoT Greengrass principal, vos fonctions Lambda utilisent IoTSiteWiseConfig le pour définir la configuration d'exportation pour ce type de destination. Pour plus d'informations, consultez la référence du SDK pour votre langue cible :
-
IoTSiteWiseConfig
dans le SDK Python -
IoTSiteWiseConfig
dans le SDK Java -
IoTSiteWiseConfig
dans le Node.js SDK
Note
AWS fournit également leSiteWise Connecteur IoT, qui est une solution prédéfinie que vous pouvez utiliser avec les OPC-UA sources.
Exigences
Cette destination d'exportation répond aux exigences suivantes :
-
Les propriétés des actifs cibles AWS IoT SiteWise doivent appartenir aux mêmes Compte AWS et à Région AWS celles du groupe Greengrass.
Note
Pour la liste des régions prises AWS IoT SiteWise en charge, voir les AWS IoT SiteWise points de terminaison et les quotas dans la référence AWS générale.
-
Ils Rôle de groupe Greengrass doivent
iotsitewise:BatchPutAssetPropertyValueautoriser le ciblage des propriétés des actifs. L'exemple de politique suivant utilise la clé deiotsitewise:assetHierarchyPathcondition pour accorder l'accès à une ressource racine cible et à ses enfants. Vous pouvez le supprimerConditionde la politique pour autoriser l'accès à tous vos AWS IoT SiteWise actifs ou spécifier les ARN des actifs individuels.Vous pouvez accorder un accès granulaire ou conditionnel aux ressources, par exemple en utilisant un schéma de
*dénomination générique. Pour plus d'informations, consultez la section Ajout et suppression de politiques IAM dans le Guide de l'utilisateur IAM.Pour obtenir des informations de sécurité importantes, consultez la section BatchPutAssetPropertyValue autorisation dans le guide de AWS IoT SiteWise l'utilisateur.
Exporter vers AWS IoT SiteWise
Pour créer un flux exporté vers AWS IoT SiteWise, vos fonctions Lambda créent un flux avec une définition d'exportation qui inclut un ou plusieurs IoTSiteWiseConfig objets. Cet objet définit les paramètres d'exportation, tels que la taille du lot, l'intervalle entre les lots et la priorité.
Lorsque vos fonctions Lambda reçoivent des données sur les propriétés des actifs de la part d'appareils, elles ajoutent des messages contenant ces données au flux cible. Les messages sont JSON-serialized PutAssetPropertyValueEntry des objets qui contiennent des valeurs de propriété pour une ou plusieurs propriétés d'actifs. Pour plus d'informations, voir Ajouter un message pour les destinations AWS IoT SiteWise d'exportation.
Note
Lorsque vous envoyez des données à AWS IoT SiteWise, celles-ci doivent répondre aux exigences de l'BatchPutAssetPropertyValueaction. Pour plus d’informations, consultez BatchPutAssetPropertyValue dans la Référence d’API AWS IoT SiteWise .
Le gestionnaire de flux exporte ensuite les données en fonction des paramètres de lot et de la priorité définis dans les configurations d'exportation du flux.
Vous pouvez ajuster les paramètres de votre gestionnaire de flux et la logique de la fonction Lambda pour concevoir votre stratégie d'exportation. Par exemple :
-
Pour les exportations en temps quasi réel, définissez des paramètres de taille de lot et d'intervalle faibles et ajoutez les données au flux dès leur réception.
-
Pour optimiser le traitement par lots, atténuer les contraintes de bande passante ou minimiser les coûts, vos fonctions Lambda peuvent regrouper les points de données timestamp-quality-value (TQV) reçus pour une propriété d'actif unique avant d'ajouter les données au flux. L'une des stratégies consiste à regrouper les entrées pour un maximum de 10 combinaisons propriétés-actifs différentes, ou alias de propriété, dans un seul message au lieu d'envoyer plusieurs entrées pour la même propriété. Cela permet au gestionnaire de flux de rester dans les limites AWS IoT SiteWise des quotas.
Objets Amazon S3
Le gestionnaire de flux prend en charge les exportations automatiques vers Amazon S3. Vous pouvez utiliser Amazon S3 pour stocker et récupérer de grandes quantités de données. Pour plus d'informations, consultez Qu'est-ce qu'Amazon S3 ? dans le guide du développeur d'Amazon Simple Storage Service.
Dans le SDK AWS IoT Greengrass principal, vos fonctions Lambda utilisent S3ExportTaskExecutorConfig le pour définir la configuration d'exportation pour ce type de destination. Pour plus d'informations, consultez la référence du SDK pour votre langue cible :
-
S3ExportTaskExecutorConfig
dans le SDK Python -
S3ExportTaskExecutorConfig
dans le SDK Java -
S3ExportTaskExecutorConfig
dans le Node.js SDK
Exigences
Cette destination d'exportation répond aux exigences suivantes :
-
Les compartiments Amazon S3 cibles doivent appartenir au même groupe Compte AWS que le groupe Greengrass.
-
Si la conteneurisation par défaut du groupe Greengrass est le conteneur Greengrass, vous devez définir le paramètre STREAM_MANAGER_READ_ONLY_DIRS pour utiliser un répertoire de fichiers d'entrée situé sous le système de fichiers racine ou non.
/tmp -
Si une fonction Lambda exécutée en mode conteneur Greengrass écrit des fichiers d'entrée dans le répertoire des fichiers d'entrée, vous devez créer une ressource de volume locale pour le répertoire et monter le répertoire dans le conteneur avec des autorisations d'écriture. Cela garantit que les fichiers sont écrits dans le système de fichiers racine et visibles en dehors du conteneur. Pour de plus amples informations, veuillez consulter Accédez aux ressources locales grâce aux fonctions et connecteurs Lambda.
-
Ils Rôle de groupe Greengrass doivent accorder les autorisations suivantes aux compartiments cibles. Par exemple :
Vous pouvez accorder un accès granulaire ou conditionnel aux ressources, par exemple en utilisant un schéma de
*dénomination générique. Pour plus d'informations, consultez la section Ajout et suppression de politiques IAM dans le Guide de l'utilisateur IAM.
Exportation vers Amazon S3
Pour créer un flux exporté vers Amazon S3, vos fonctions Lambda utilisent l'S3ExportTaskExecutorConfigobjet pour configurer la politique d'exportation. La politique définit les paramètres d'exportation, tels que le seuil et la priorité du téléchargement en plusieurs parties. Pour les exportations Amazon S3, le gestionnaire de flux télécharge les données qu'il lit à partir de fichiers locaux sur l'appareil principal. Pour lancer un téléchargement, vos fonctions Lambda ajoutent une tâche d'exportation au flux cible. La tâche d'exportation contient des informations sur le fichier d'entrée et l'objet Amazon S3 cible. Le gestionnaire de flux exécute les tâches dans l'ordre dans lequel elles sont ajoutées au flux.
Note
Le compartiment cible doit déjà exister dans votre Compte AWS. Si aucun objet correspondant à la clé spécifiée n'existe, le gestionnaire de flux le crée pour vous.
Ce flux de travail de haut niveau est illustré dans le schéma suivant.
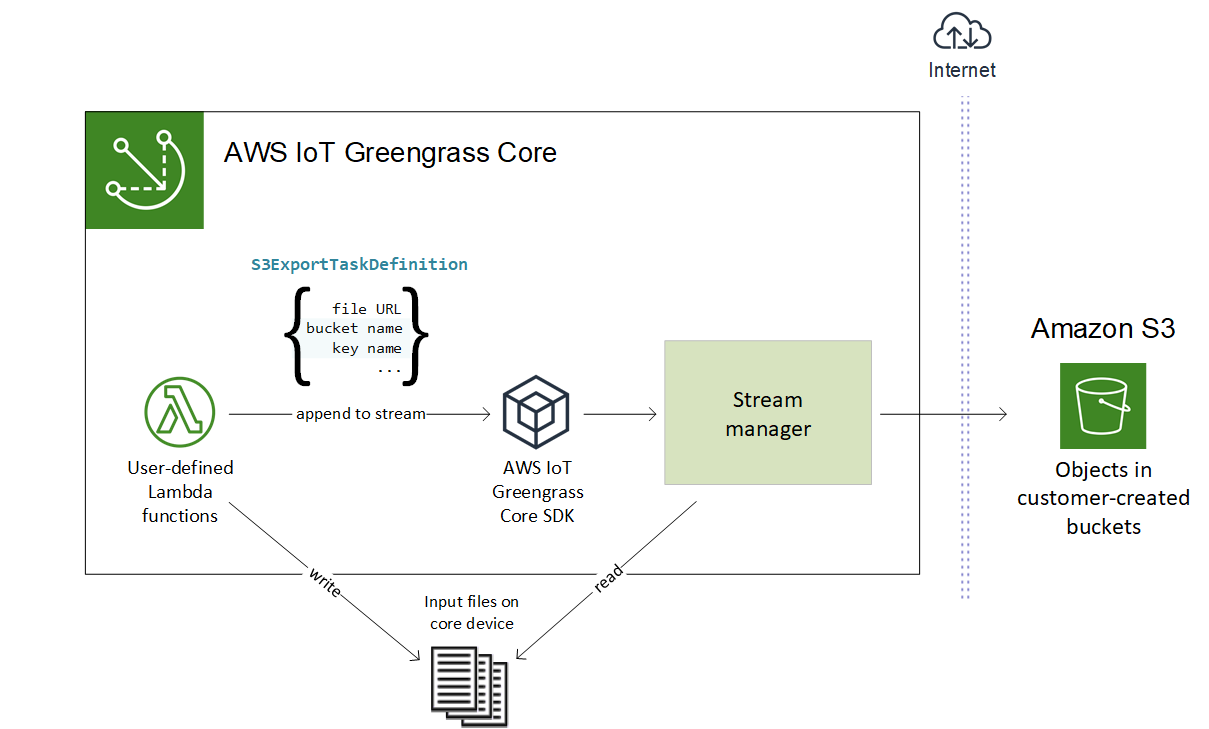
Le gestionnaire de flux utilise la propriété de seuil de téléchargement en plusieurs parties, le paramètre de taille de pièce minimale et la taille du fichier d'entrée pour déterminer le mode de téléchargement des données. Le seuil de téléchargement partitionné doit être supérieur ou égal à la taille de pièce minimale. Si vous souhaitez télécharger des données en parallèle, vous pouvez créer plusieurs flux.
Les clés qui spécifient vos objets Amazon S3 cibles peuvent inclure des DateTimeFormatter chaînes Java!{timestamp: espaces réservés. Vous pouvez utiliser ces espaces réservés d'horodatage pour partitionner les données dans Amazon S3 en fonction de l'heure à laquelle les données du fichier d'entrée ont été téléchargées. Par exemple, le nom de clé suivant correspond à une valeur telle quevalue}my-key/2020/12/31/data.txt.
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
Note
Si vous souhaitez surveiller l'état d'exportation d'un flux, créez d'abord un flux d'état, puis configurez le flux d'exportation pour l'utiliser. Pour de plus amples informations, veuillez consulter Surveiller les tâches d'exportation.
Gérer les données d'entrée
Vous pouvez créer du code que les applications IoT utilisent pour gérer le cycle de vie des données d'entrée. L'exemple de flux de travail suivant montre comment vous pouvez utiliser les fonctions Lambda pour gérer ces données.
-
Un processus local reçoit des données provenant d'appareils ou de périphériques, puis écrit les données dans des fichiers situés dans un répertoire du périphérique principal. Il s'agit des fichiers d'entrée pour le gestionnaire de flux.
Note
Pour déterminer si vous devez configurer l'accès au répertoire du fichier d'entrée, consultez le paramètre STREAM_MANAGER_READ_ONLY_DIRS.
Le processus dans lequel le gestionnaire de flux s'exécute hérite de toutes les autorisations du système de fichiers associées à l'identité d'accès par défaut du groupe. Le gestionnaire de flux doit être autorisé à accéder aux fichiers d'entrée. Vous pouvez utiliser la
chmod(1)commande pour modifier l'autorisation des fichiers, si nécessaire. -
Une fonction Lambda analyse le répertoire et ajoute une tâche d'exportation au flux cible lorsqu'un nouveau fichier est créé. La tâche est un JSON-serialized
S3ExportTaskDefinitionobjet qui spécifie l'URL du fichier d'entrée, le compartiment et la clé Amazon S3 cibles, ainsi que les métadonnées utilisateur facultatives. -
Le gestionnaire de flux lit le fichier d'entrée et exporte les données vers Amazon S3 dans l'ordre des tâches ajoutées. Le compartiment cible doit déjà exister dans votre Compte AWS. Si aucun objet correspondant à la clé spécifiée n'existe, le gestionnaire de flux le crée pour vous.
-
La fonction Lambda lit les messages d'un flux d'état pour surveiller le statut de l'exportation. Une fois les tâches d'exportation terminées, la fonction Lambda peut supprimer les fichiers d'entrée correspondants. Pour de plus amples informations, veuillez consulter Surveiller les tâches d'exportation.
Surveiller les tâches d'exportation
Vous pouvez créer du code que les applications IoT utilisent pour surveiller le statut de vos exportations Amazon S3. Vos fonctions Lambda doivent créer un flux d'état, puis configurer le flux d'exportation pour écrire des mises à jour de statut dans le flux d'état. Un seul flux de statut peut recevoir des mises à jour de statut provenant de plusieurs flux exportés vers Amazon S3.
Créez d'abord un flux à utiliser comme flux d'état. Vous pouvez configurer la taille et les politiques de rétention du flux afin de contrôler la durée de vie des messages d'état. Par exemple :
-
Définissez
PersistencecetteMemoryoption si vous ne souhaitez pas enregistrer les messages d'état. -
Réglé
StrategyOnFullsur pourOverwriteOldestDataque les nouveaux messages d'état ne soient pas perdus.
Créez ou mettez à jour le flux d'exportation pour utiliser le flux d'état. Spécifiquement, définissez la propriété de configuration d'état de la configuration S3ExportTaskExecutorConfig d'exportation du flux. Cela indique au gestionnaire de flux d'écrire des messages d'état concernant les tâches d'exportation dans le flux d'état. Dans l'StatusConfigobjet, spécifiez le nom du flux d'état et le niveau de verbosité. Les valeurs prises en charge suivantes vont de la moins détaillée (ERROR) à la plus détaillée (). TRACE La valeur par défaut est INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
L'exemple de flux de travail suivant montre comment les fonctions Lambda peuvent utiliser un flux d'état pour surveiller le statut des exportations.
-
Comme décrit dans le flux de travail précédent, une fonction Lambda ajoute une tâche d'exportation à un flux configuré pour écrire des messages d'état concernant les tâches d'exportation dans un flux de statut. L'opération d'ajout renvoie un numéro de séquence qui représente l'ID de tâche.
-
Une fonction Lambda lit les messages de manière séquentielle à partir du flux d'état, puis filtre les messages en fonction du nom du flux et de l'ID de tâche ou en fonction d'une propriété de tâche d'exportation du contexte du message. Par exemple, la fonction Lambda peut filtrer en fonction de l'URL du fichier d'entrée de la tâche d'exportation, qui est représentée par l'
S3ExportTaskDefinitionobjet dans le contexte du message.Les codes d'état suivants indiquent qu'une tâche d'exportation est terminée :
-
Success. Le téléchargement a été effectué avec succès. -
Failure. Le gestionnaire de flux a rencontré une erreur. Par exemple, le bucket spécifié n'existe pas. Une fois le problème résolu, vous pouvez à nouveau ajouter la tâche d'exportation au flux. -
Canceled. La tâche a été abandonnée car la définition du flux ou de l'exportation a été supprimée ou parce que la durée de vie (TTL) de la tâche a expiré.
Note
La tâche peut également avoir le statut
InProgressouWarning. Le gestionnaire de flux émet des avertissements lorsqu'un événement renvoie une erreur qui n'affecte pas l'exécution de la tâche. Par exemple, l'échec du nettoyage d'un téléchargement partiel interrompu renvoie un avertissement. -
-
Une fois les tâches d'exportation terminées, la fonction Lambda peut supprimer les fichiers d'entrée correspondants.
L'exemple suivant montre comment une fonction Lambda peut lire et traiter les messages d'état.
